https://blog.tensorflowcn.cn/2022/09/content-moderation-using-machine-learning-the-server-side-part.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgZ_JzGn-9CXVZpuyyrXbmdthLMMdql_3BLsvQKu5mkD0xrlA57ZYRtFhDVtpanBhS9tC_2NCRqsm46uJCrXWR5-Fgz8klSwKJ0AVMMdwgAhofeQ80ryOIoTz-ZdsU90vHjy1H6chshzhYYrDQOUriFB-k_vYAqPPq1NiZxx7Lu9uBWpCfpmpDWxFiH/s1600/tensorflow-content-moderation-using-machine-learning-the%20server-side-part-02.png


作者:Jen Person,TensorFlow 高级开发者关系工程师
欢迎来到我对内容审核的双重方法的第二部分!在本文中,我将向您展示如何在服务器端环境中使用机器学习来实现内容审核。如果您想了解如何在客户端实现这种审核,请查看第 1 部分。
提醒我:我们在这里再做什么?
简而言之,匿名性可以在某种程度上让人们之间产生距离,从而让他们说出他们在现实生活中不会说的话。也就是说,有大量的喷子存在。坦白地说,我们每个人至少都曾在网上输入过一些我们实际上不会在现实生活中说的话!任何接受公共文本输入的网站都可以从某种形式的审核中获益。客户端审核的优点是即时反馈,但服务器端审核无法像客户端那样被绕过,所以我喜欢同时使用两种方法。
这个项目承接了第 1 部分,但您也可以从 Firebase 文本审核演示代码的全新副本开始。Firebase 演示中的网站展示了通过使用通过
实时数据库触发云函数 实现的服务器端内容审核系统来进行内容审核。这意味着访客簿数据存储在
Firebase 实时数据库 中,这是一个 NoSQL 数据库。每当将数据写入数据库的特定区域时,
云函数 就会被触发。我们可以选择在触发该事件时运行什么代码。在本例中,我们将使用
文本毒性分类器模型 来确定写入数据库的文本是否不当,然后在需要时将其从数据库中删除。使用此模型,您可以评估文本对不同类型的有害内容的标签,包括身份攻击、侮辱和淫秽内容。您可以尝试
演示 看看分类器的实际效果。
如果您想从最后开始,可以按照 GitHub 上的
项目的完整版本 进行操作。
cd text-moderation/functions |
打开
index.js 并删除其内容。在
index.js 中,添加以下代码
const functions = require('firebase-functions'); const toxicity = require('@tensorflow-models/toxicity');
exports.moderator = functions.database.ref('/messages/{messageId}').onCreate(async (snapshot, context) => { const message = snapshot.val();
// 验证快照是否有值 if (!message) { return; } functions.logger.log('检索到的消息内容: ', message);
// 对消息运行审核检查,如果需要则删除。 const moderateResult = await moderateMessage(message.text); functions.logger.log( '消息已审核。消息是否违反规则? ', moderateResult ); }); |
这段代码会在每次向数据库添加消息时运行。它获取消息的文本,然后将其传递给名为 `moderateResult` 的函数。如果您有兴趣详细了解 Cloud Functions 和实时数据库,请查看
Firebase 文档。
添加文本毒性分类器模型
根据您的开发环境,您现在可能遇到了一些错误,因为我们还没有编写名为 moderateMessage 的函数。让我们修复它。在您的 Cloud Function 触发器函数下方,添加以下代码
exports.moderator = functions.database.ref('/messages/{messageId}').onCreate(async (snapshot, context) => { //… // 您其他函数代码在这里。 });
async function moderateMessage(message) { const threshold = 0.9
let model = await toxicity.load(threshold);
const messages = [message];
let predictions = await model.classify(messages);
for (let item of predictions) { for (let i in item.results) { if (item.results[i].match === true) { return true; } } } return false; } |
|
这个函数的功能如下
- 将模型的threshold设置为0.9。模型的threshold是您要用于将模型预测设置为true或false的最低预测置信度,也就是说,模型对文本是否包含给定类型的有害内容的置信度。阈值的范围是0-1.0。在本例中,我将阈值设置为0.9,这意味着如果模型对其发现的置信度为90%,则它将预测true或false。
- 加载模型,传递阈值。加载后,将 toxicity_model 设置为 model` 的值。
- 将消息放入名为messages的数组中,因为数组是classify函数接受的对象类型。
- 对messages数组调用classify。
- 遍历预测结果。predictions是一个对象数组,每个对象代表一个不同的语言标签。您可能只想了解特定标签,而不是遍历所有标签。例如,如果您的用例是用于托管说唱对战文字记录的网站,您可能不希望检测和删除侮辱。
- 检查内容是否与该标签匹配。如果match值为true,则模型已检测到给定类型的有害语言。如果检测到有害语言,则函数返回true。无需继续检查其余结果,因为内容已被认定为不合适。
- 如果函数遍历了所有结果,并且没有标签匹配设置为true,则函数返回false - 意味着没有发现不良语言。匹配标签也可以是null。在这种情况下,它的值不是true,因此被认为是可接受的语言。我将在以后的文章中更多地讨论null选项。
如果您完成了本教程的第一部分,那么这些步骤可能听起来很熟悉。服务器端代码与客户端代码非常相似。这是我喜欢 TensorFlow.js 的原因之一:它通常可以轻松地将代码从客户端转移到服务器,反之亦然。
完成 Cloud Functions 代码
回到您的 Cloud Function 中,您现在知道,根据我们为moderateMessage编写的代码,moderateResult的值将为 true 或 false:如果消息被模型认为是有害的,则为 true;如果它没有检测到置信度大于 90% 的毒性,则为 false。现在添加代码以删除数据库中被认为是有害的消息 // 对消息运行审核检查,并在需要时删除。 const moderateResult = await moderateMessage(message.text); functions.logger.log( '消息已审核。消息是否违反规则? ', moderateResult );
if (moderateResult === true) { var modRef = snapshot.ref; try { await modRef.remove(); } catch (error) { functions.logger.error('Remove failed: ' + error.message); } } |
这段代码的功能如下:
- 检查 moderateResult 是否为真,表示留言板中写入的消息不合适。
- 如果值为真,则使用实时数据库 SDK 中的 remove 函数 从数据库中删除数据。
- 如果发生错误,则记录错误。
部署代码
要部署 Cloud Function,您可以使用
Firebase CLI。如果您没有,可以使用以下 npm 命令安装它:
npm install -g firebase-tools |
安装完成后,使用以下命令登录:
运行此命令将应用程序连接到您的 Firebase 项目 在这里,您可以从列表中选择您的项目,将 Firebase 连接到现有的 Google Cloud 项目,或创建一个新的 Firebase 项目。
项目配置完成后,使用以下命令部署您的 Cloud Function:
部署完成后,日志中将包含托管的留言板的链接。写一些留言板条目。如果您遵循了博客的第 1 部分,则需要从网站中删除审核代码并再次部署,或者手动将留言板条目添加到 Firebase 控制台中的实时数据库。
您可以在 Firebase 控制台中查看 Cloud Functions 日志。
基于示例进行构建
我有许多关于如何基于此示例进行构建的想法。以下只是一些想法。请告诉我您想让我构建哪些想法,并分享您的建议!最好的想法来自合作。
获取队列
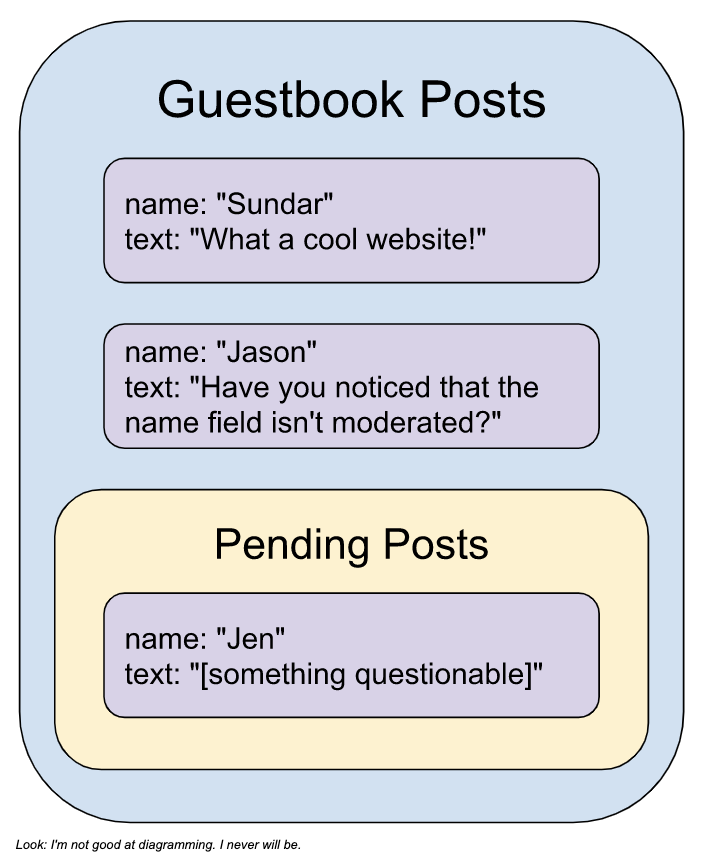
我提到过语言标签的“匹配”值可以是 true、false 或 null,而没有详细说明 null 值的意义。如果标签是 null,则模型无法确定该语言是否在给定阈值内具有毒性。限制 null 值数量的一种方法是降低此阈值。例如,如果您将阈值更改为 0.8,则如果模型至少 80% 确定文本包含符合标签的语言,则模型将标签的匹配值标记为 true。我的网站示例将值为 null 的标签分配给与标记为 false 的标签相同,允许该文本通过过滤器。但是,由于模型不确定该文本是否合适,因此最好让一些人查看它。您可以将这些帖子添加到审核队列中,然后根据需要批准或拒绝它们。这里我说是“您”,但我指的是“我”。如果您认为这是一个有趣的用例,请告诉我!如果它有用,我很乐意写一篇关于它的文章。
存储的内容
我作为项目基础使用的 Firebase 审核示例使用实时数据库。我更喜欢使用 Firestore,因为它具有结构、可扩展性和安全性。Firestore 的结构非常适合实现队列,因为我可以在帖子集合中拥有要审核的帖子集合。如果您想查看使用 Firestore 的网站,请告诉我。
不要只消除 - 审核!
我喜欢原始的 Firebase 审核示例的一点是它会对文本进行消毒,而不是直接删除帖子。您可以先将文本通过消毒器处理,然后再使用文本毒性模型检查是否有毒性语言。如果消毒后的文本被认为是合适的,那么它可以覆盖原始文本。如果它仍然不符合良好话语的标准,那么您仍然可以删除它。这可能会挽救一些原本会被删除的帖子。
名称的意义是什么?
您可能已经注意到我的审核功能不扩展到名称字段。这意味着即使是一个半路出家的恶意用户也可以轻松地绕过过滤器,将所有脏话塞到那个名称字段里。这是一个很好的观点,我相信您会对用户交互的所有字段使用某种审核。也许您使用身份验证方法来识别用户,这样他们就不会被提供用于输入名称的字段。总之,您明白了:我没有在名称字段中添加审核,但在生产环境中,您绝对需要对所有字段进行审核。
打造更好的契合度
当您在网站上测试真实世界的文本样本时,您可能会发现文本毒性分类器模型并不完全适合您的需求。由于每个社交空间都是独一无二的,您将需要包含和排除特定的语言。您可以通过使用您提供的新数据训练模型来满足这些需求。
如果您喜欢这篇文章,并且想了解更多关于 TensorFlow.js 的知识,那么您可以做很多事情