作者:Jen Person,开发者倡导者
我一直想知道为什么匿名会让人们说出他们在现实生活中永远不敢说的话,而且视频和文章的评论区经常充满毒性!如果您对内容审核感兴趣,您可以使用机器学习来帮助检测您认为应该删除的有毒帖子。
机器学习是各种自然语言处理任务的强大工具,包括翻译、情感分析和预测文本。但也许您会觉得它超出了您的工作范围。毕竟,当您使用 JavaScript 构建网站时,您没有时间收集和验证数据,使用 Python 训练模型,然后在 Python 上实现一些后端来运行该模型。并非 Python 有什么问题——只是如果您是 Web 开发人员,它可能不是您的首选语言。
幸运的是,TensorFlow.js 允许您在 每个人最喜欢的语言:JavaScript 中的网站上运行机器学习模型。此外,TensorFlow.js 提供了针对 Web 上常见用例的几个 预训练模型。只需几行代码,您就可以将 ML 的强大功能添加到您的网站!甚至有一个预训练模型可以帮助您审核书面内容,这也是我们今天要讨论的内容。
存在一个针对内容审核效果良好的现成预训练模型:TensorFlow.js 文本毒性分类器模型。使用此模型,您可以根据各种不希望出现的标签(包括身份攻击、侮辱和淫秽内容)评估文本。您可以尝试一下 演示 看看分类器的实际效果。我承认我玩得有点过瘾,测试了一下哪些内容会被标记为有害。例如

我建议您在此处停止,并使用文本毒性分类器演示玩一玩。最好看看模型检查哪些文本类别,并确定哪些类别您想要从自己的网站中过滤掉。此外,如果您想知道上面引述的内容被标记了哪些类别,您需要进入演示页面才能看到标题。
在您对文本毒性分类器模型进行充分的辱骂后,请返回这篇博文,了解如何在自己的代码中使用它。
这最初是一个包含客户端和服务器端代码的单一教程,但内容有点长,所以我决定将其拆分成两个部分。将教程分离,可以更容易地找到您感兴趣的部分,如果您只想实现其中一部分。在这篇文章中,我将介绍使用基本网站通过 TensorFlow.js 进行 **客户端** 审核的实现步骤。在第 2 部分中,我将展示如何使用 Firebase 的 Cloud Functions 在 **服务器端** 实现相同的模型。
在客户端审核内容,可以为您的用户提供更快的反馈循环,允许您在有害言论开始之前阻止它。它还可以节省后端成本,因为不恰当的评论无需写入数据库、评估,然后删除。
我使用 Firebase 文本审核示例 作为我的演示网站的基础。它看起来像这样
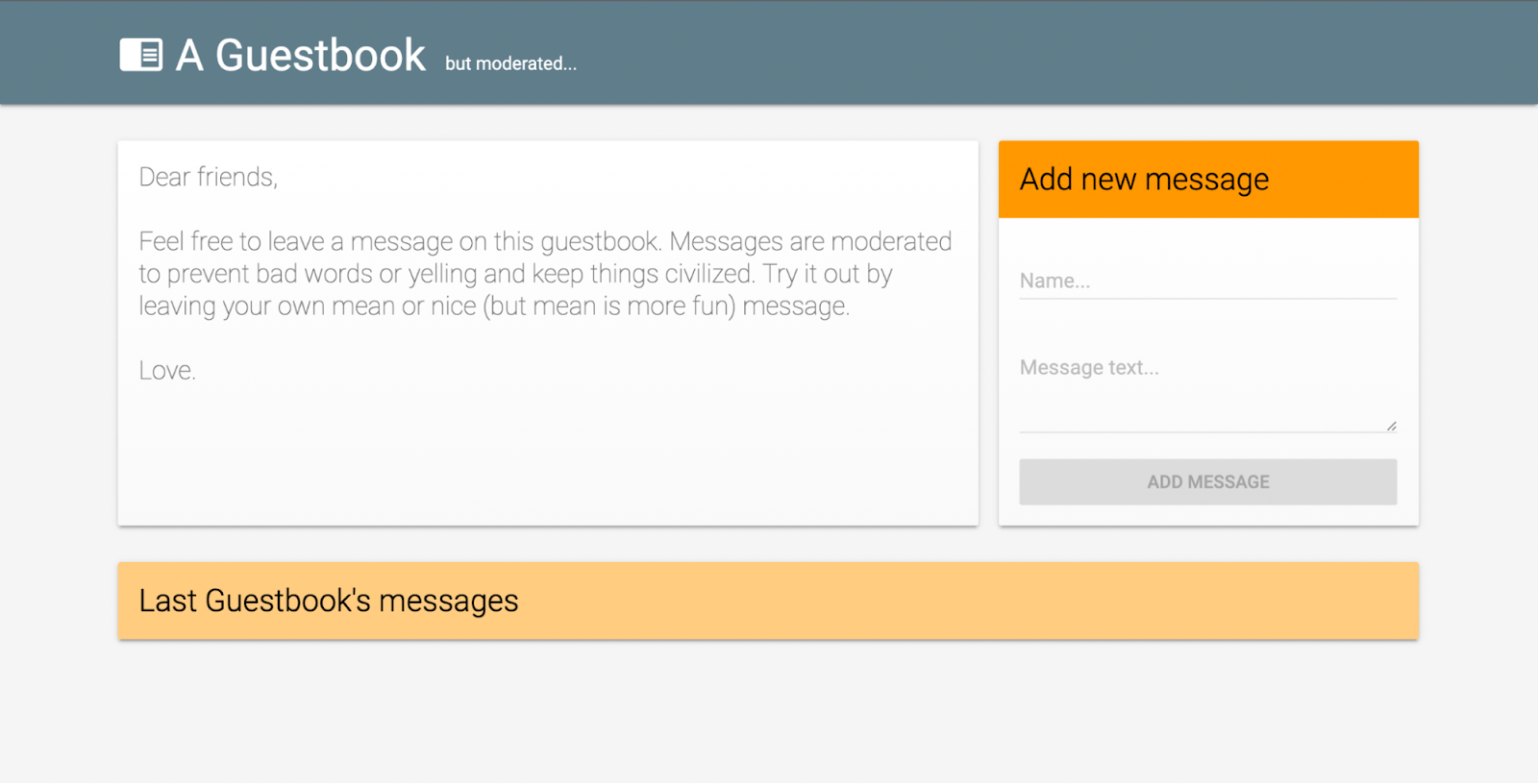
请记住,TensorFlow.js 不需要 Firebase。您可以使用最适合您的应用程序需求的任何托管、数据库和后端解决方案。我只是倾向于使用 Firebase,因为我已经很熟悉它了。而且坦率地说,TensorFlow.js 和 Firebase 协同工作得很好!Firebase 演示中的网站通过基本留言簿展示了内容审核,它使用通过 实时数据库触发的 Cloud Function 实现的服务器端内容审核系统。如果这听起来像是很多行话,不用担心。我将逐步指导您了解在自己的代码中使用 TensorFlow.js 模型需要了解的具体内容。也就是说,如果您想构建我制作的这个特定示例,最好看一下 GitHub 上的 Firebase 示例。
如果您要与我一起构建示例,请克隆 Cloud Functions 示例 存储库。然后更改到文本审核应用程序的目录。
此项目要求您安装 Firebase CLI。如果您没有安装,可以使用以下 npm 命令安装它
安装完成后,使用以下命令登录
运行此命令将应用程序连接到您的 Firebase 项目
从这里,您可以从列表中选择您的项目,将 Firebase 连接到现有的 Google Cloud 项目,或创建一个新的 Firebase 项目。项目配置完成后,使用以下命令部署实时数据库安全规则和 Firebase 托管
此时无需部署 Cloud Functions,因为我们将完全更改示例代码。
请注意,按原样编写的 Firebase 文本审核示例使用 Blaze(按使用付费) Firebase 计划。如果您选择遵循此演示,包括服务器端组件,则可能需要将您的项目从 Spark 升级到 Blaze。如果您通过 Google Cloud 在项目中设置了计费帐户,那么您已经升级并可以正常使用!最重要的是,如果您还没有准备好升级您的项目,请不要部署示例的 Cloud Functions 部分。您仍然可以使用 **不含 Cloud Functions 的客户端审核**。
为了在示例中实现客户端审核,我在 Firebase 文本审核示例的 index.html 和 main.js 文件中添加了一些代码。使用 TensorFlow.js 模型时,有三个主要步骤需要实现:安装所需的组件、加载模型,然后运行预测。让我们为每个步骤添加代码。
添加所需的 TensorFlow.js 依赖项。我在 HTML 中将依赖项添加为脚本标签,但如果您在 Web 应用程序中使用捆绑器/转译器,则可以使用 Node.js。
将以下代码添加到 Guestbook() 函数中,以加载文本毒性模型。Guestbook() 函数是原始 Firebase 示例的一部分。它初始化 Guestbook 组件,并在页面加载时调用。
模型的 threshold 是您要用来将模型的预测设置为 true 或 false 的最小预测置信度 - 也就是说,模型对文本是否包含给定类型的有害内容的置信度。阈值的范围是 0-1.0。在本例中,我将阈值设置为 .9,这意味着如果模型对其发现有 90% 的把握,它将预测 true 或 false。您需要决定什么阈值适合您的用例。您甚至可能想尝试使用 文本毒性分类器演示 和一些可能出现在您网站上的短语来确定模型如何处理它们。
toxicity.load 加载模型,传递阈值。加载完成后,它将 toxicity_model 设置为 model 值。
添加一个 checkContent 函数,在点击“添加消息”时对消息运行模型预测。
这个函数执行以下操作
toxicity_model 有值,则 load() 函数已完成模型加载。messages 的数组中,因为数组是 classify 函数接受的对象类型。messages 数组调用 classify。predictions 是一个对象数组,每个对象代表不同的语言标签。您可能只想了解特定标签,而不是遍历所有标签。例如,如果您的用例是用于托管说唱战斗的文字记录的网站,您可能不希望检测和删除侮辱性言论。match 值为true,则模型已检测到给定类型的有害语言。如果检测到有害语言,则函数返回 true。由于内容已被认定为不合适,因此无需继续检查其余结果。true,则函数返回false,这意味着未发现任何不良语言。匹配标签也可以为null。在这种情况下,其值不是true,因此被视为可接受的语言。我会在以后的文章中详细介绍null 选项。在saveMessage 函数中添加对checkContent 的调用。
经过一些简单的输入值检查后,消息框的内容将传递给checkContent 函数。
如果内容通过了检查,则消息将写入实时数据库。否则,将显示一个提示消息作者保持友善的 Snackbar。 Snackbar 并没有什么特别之处,所以我不会在这里包含代码。您可以在完整的示例代码中查看它,或者自行实现 Snackbar。
如果您一直在自己的代码中进行操作,请在您的项目文件夹中运行此终端命令来部署网站
 | ||
不可接受的消息会被拒绝
| ||
验证这段代码是否正常运行真的让我感到不舒服。我不得不编造一个模型认为不合适的侮辱,然后不断地在网站上写它。从我的工作电脑上。我知道没有人能看到,但还是。这绝对是我工作中比较奇怪的一部分! 下一步 |