作者:Wei Wei,开发者倡导者

在我们的上一篇博文中 使用 TensorFlow 构建棋盘游戏应用程序:新的 TensorFlow Lite 参考应用程序,我们向您展示了如何使用 TensorFlow 和 TensorFlow Agents 训练一个强化学习 (RL) 代理来玩一个简单的棋盘游戏“Plane Strike”。我们还将训练后的模型转换为 TensorFlow Lite,然后将其部署到一个功能齐全的 Android 应用程序中。在这篇博文中,我们将演示一条新的路径:使用 Flax/JAX 训练相同的 RL 代理,并将其部署到我们之前构建的同一 Android 应用程序中。完整的代码已在 tensorflow/examples 存储库中开源,供您参考。
为了刷新您的记忆,我们基于 RL 的代理需要根据人类玩家的棋盘位置预测打击位置,以便它可以在人类玩家之前完成游戏。有关更详细的游戏规则,请参阅我们之前的 博客。
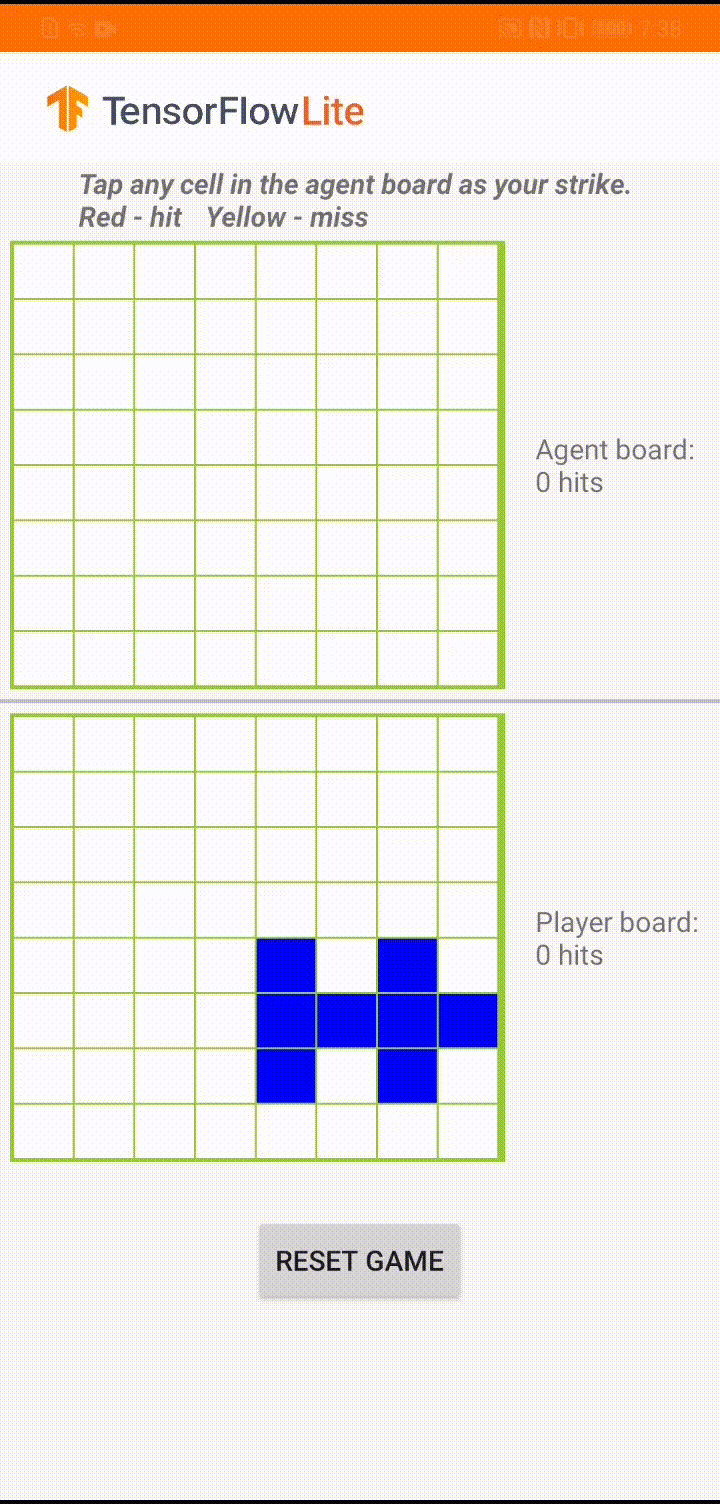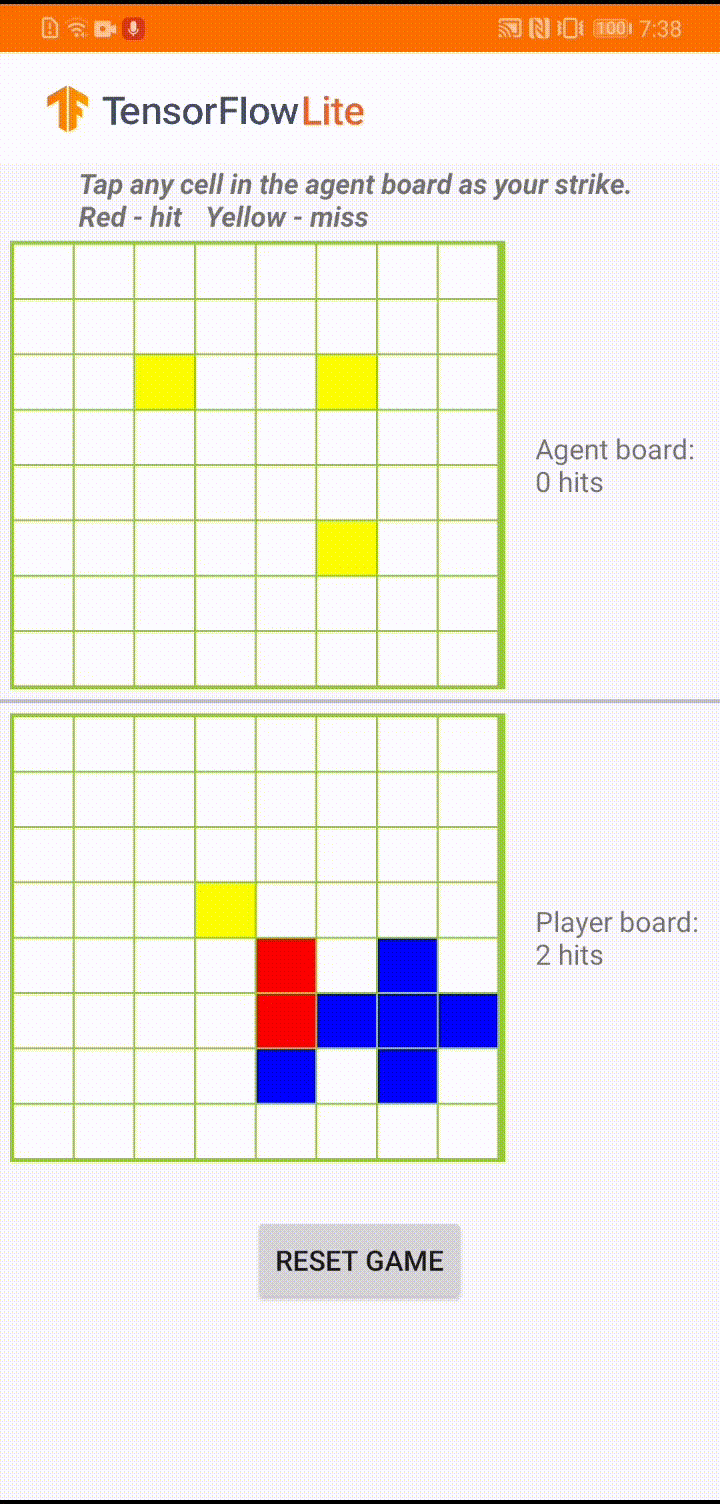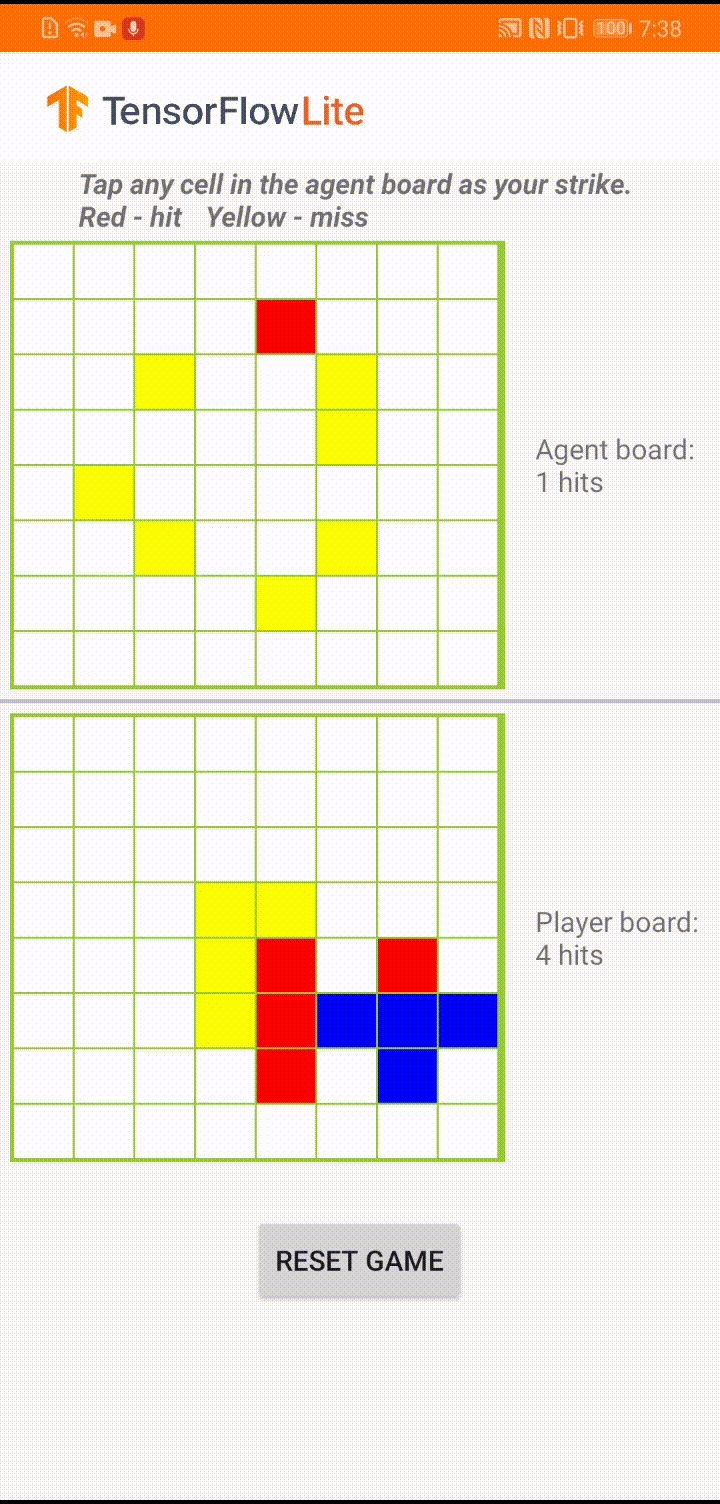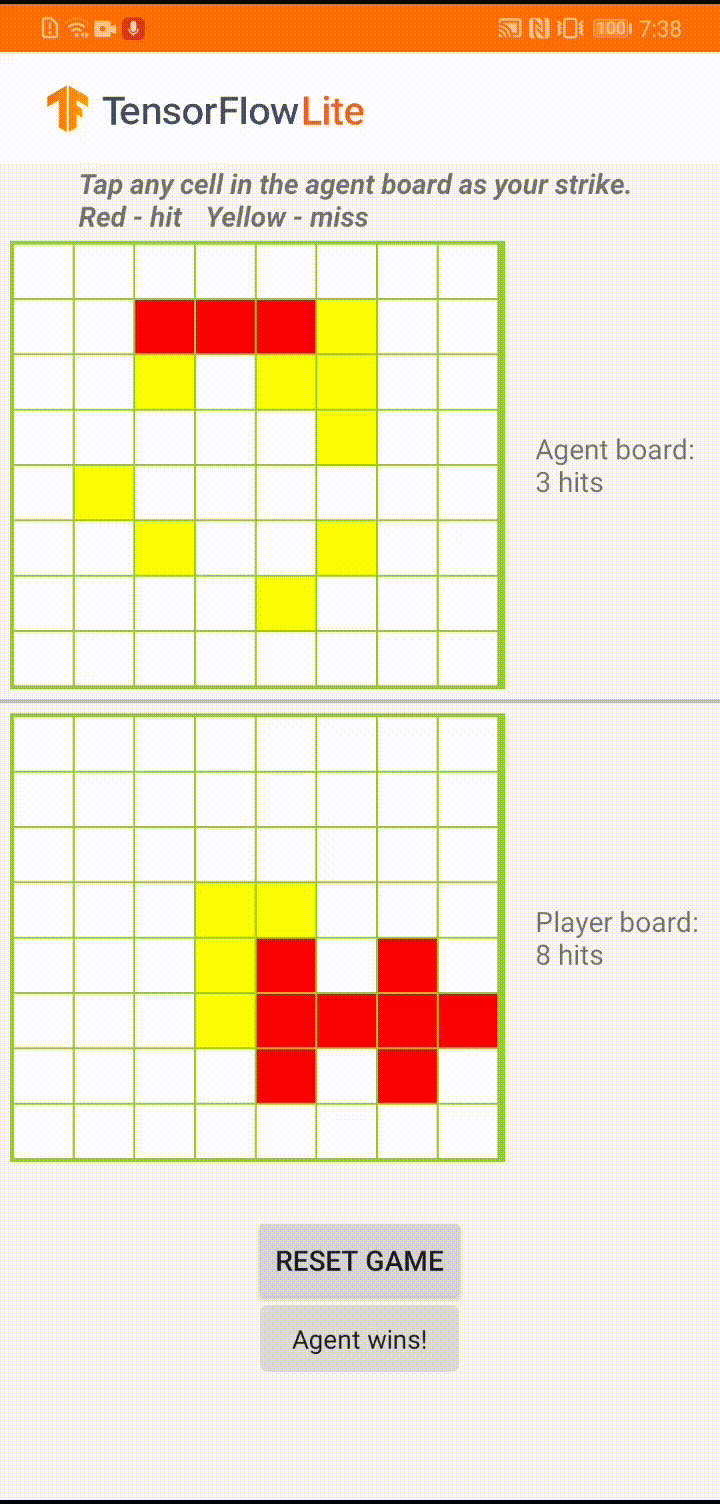 |
| “Plane Strike”中的演示游戏玩法 |
.png)
其中
我们将一个 3 层 MLP 定义为我们的策略网络,它预测代理的下一个打击位置。

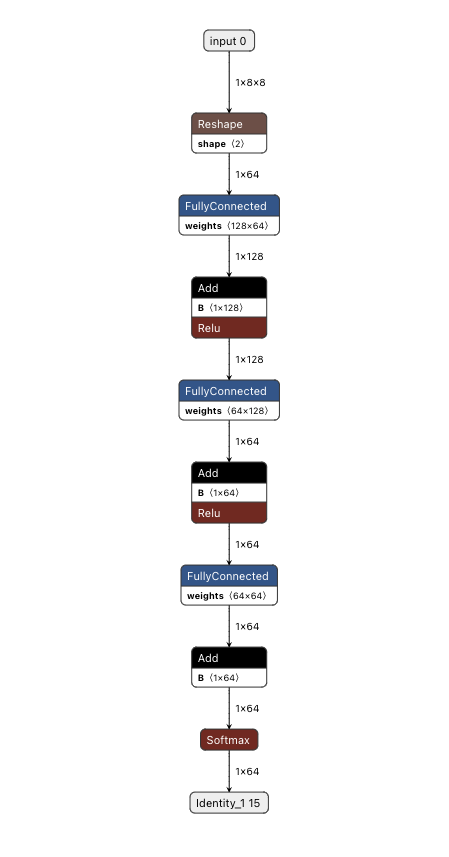 |
| 使用 Netron 可视化由 Flax/JAX 转换的 TFLite 模型 |

2022 年 10 月 3 日 — 作者:Wei Wei,开发者倡导者在我们之前的博文 使用 TensorFlow 构建棋盘游戏应用程序:新的 TensorFlow Lite 参考应用程序中,我们向您展示了如何使用 TensorFlow 和 TensorFlow Agents 训练一个强化学习 (RL) 智能体来玩简单的棋盘游戏“飞机攻击”。我们还将训练后的模型转换为 TensorFlow Lite,然后将其部署到功能齐全的 Android a…





