https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhPgzXuw86PD1HNCCIhrah5h-OLyLNYYyTOnYclaxK5V-nxZvM4VD5qPlqm04cyUYPI8XMoP22aQ3rtz4TyySQIDNleKUDAnbf94PrHY_yXA4OX0LZyI_ljw0rXipCv5Y419LW_cmNt0w0lzep5GfJ5KzUaR23wsXqpewIRKiyRDFbO-2HffMx6p2LX/w660-h196/Tensorflow-Jax-on-the-Web-01.png

发布者 Andreas Steiner 和 Marc van Zee,Google Research,Brain 团队
简介
在这篇博文中,我们将展示如何使用 TensorFlow.js 将基于 Python 的 JAX 函数和 Flax 机器学习模型转换为在浏览器中运行。我们制作了三个 JAX 到 TensorFlow.js 转换的例子,每个例子的复杂度递增:
- 简单的 JAX 函数
- 在 MNIST 数据集上训练的图像分类 Flax 模型
- 完整的图像/文本 Vision Transformer (ViT) 演示,它被用于 Google AI 博客文章 Locked-Image Tuning: Adding Language Understanding to Image Models (演示的预览见下图 1)
对于每个例子,都有 Google Colab 笔记本供您使用,您可以自行尝试 JAX 到 TensorFlow.js 的转换。
 |
| 图 1. TensorFlow.js 模型将用户提供的文本提示与预计算的图像嵌入相匹配 (自己试试)。请参阅下文的 示例 3:LiT 演示 以了解实现细节。 |
背景:JAX 和 TensorFlow.js
JAX 是一个类似 NumPy 的库,由 Google Research 开发,用于高性能计算。它使用
XLA 编译针对 GPU 和
TPU 优化的程序。Flax 是一个基于 JAX 之上的流行神经网络库。研究人员一直在使用 JAX/Flax 来训练具有数十亿个参数的超大型模型(如用于语言理解和生成的
PaLM,或用于图像生成的
Imagen),充分利用了现代硬件。如果您不熟悉 JAX 和 Flax,可以从
这个 JAX 101 教程 和
这个 Flax 入门示例 开始。
TensorFlow 最初是作为 ML 库在 2015 年底开始的,此后已发展成为一个丰富的生态系统,其中包括用于将 ML 管道投入生产的工具 (
TFX)、数据可视化 (
TensorBoard)、将 ML 模型部署到边缘设备 (
TensorFlow Lite) 以及在 Web 浏览器或任何能够执行 JavaScript 的设备上运行的设备 (
TensorFlow.js)。在 JAX 或 Flax 中开发的模型可以通过将这样的模型首先转换为 TensorFlow
SavedModel 格式,然后使用与它们在 TensorFlow 中本机开发时相同的工具来利用这个丰富的生态系统。
现在,通过新的 Python API —
tfjs.converters.convert_jax() — 使得 TensorFlow.js 更加容易,该 API 允许用户将用 Python 编写的 JAX 模型直接转换为 Web 格式 (
.json),以便模型可以在浏览器中与 Tensorflow.js 一起使用。
要了解如何执行 JAX 到 TensorFlow.js 的转换,请查看以下三个示例。
示例 1:转换简单的 JAX 函数
在这个入门示例中,您将使用
converters.convert_jax() 转换一些简单的 JAX 函数。
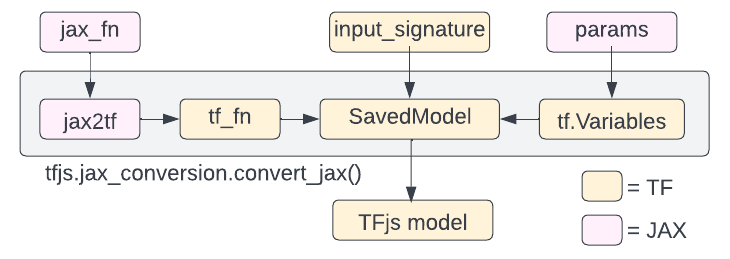
在内部,此函数执行以下操作
- 它转换为 Tensorflow SavedModel 格式,其中包含完整的 TensorFlow 程序,包括训练参数(即,
tf.Variables) 和计算。 - 然后,它从该 SavedModel 中构建 TensorFlow.js 模型(有关更多详细信息,请参考图 2)。
要将 Flax 模型转换为 TensorFlow.js,您需要以下几件事
- 运行模型前向传递的函数。
- 模型参数(这通常是一个类似字典的结构)。
- 输入函数的形状和数据类型的规范。
以下示例使用单个参数 weight 并实现函数 prod,该函数将输入与参数相乘(在一个真实的示例中,params 将包含神经网络中使用的所有模块的权重)
|
def prod(params, xs):
return params['weight'] * xs
|
让我们用一些值调用这个函数,并验证输出是否合理
|
params = {'weight': np.array([0.5, 1])}
# 这代表 3 个输入的批次,每个输入长度为 2。
xs = np.arange(6).reshape((3, 2))
prod(params, xs)
|
这将产生以下输出,其中每个批次元素都按元素乘以
[0.5, 1]
|
[[0. 1.]
[1. 3.]
[2. 5.]]
|
接下来,让我们使用 convert_jax 将其转换为 TensorFlow.js,并使用辅助函数 get_tfjs_predict_fn(可在 Colab 中找到),让我们可以验证 JAX 函数和 Web 模型的输出是否匹配。(注意:此辅助函数仅在 Colab 中有效,因为它使用一些工具使用 Javascript 运行 Web 模型。)
|
tfjs.converters.convert_jax(
prod,
params,
input_signatures=[tf.TensorSpec((3, 2), tf.float32)],
model_dir=model_dir)
tfjs_predict_fn = get_tfjs_predict_fn(model_dir)
tfjs_predict_fn(xs) # 与 JAX 的输出相同。
|
在 Tensorflow 中,通常通过将 `input_signature` 中的动态维度值设置为 `None` 来支持动态形状。此外,还应传递参数 `polymorphic_shapes` 以指定动态维度的名称。请注意,[多态性](https://github.com/google/jax/tree/main/jax/experimental/jax2tf#shape-polymorphic-conversion "多态性") 是类型论中的一个术语,但在这里我们使用它来表示该函数适用于多个相关形状,例如,适用于多个批次大小。这对于 JAX 函数中的形状检查是必要的(有关更多示例,请参阅 [Colab](https://colab.sandbox.google.com/github/andsteing/JaxOnTheWeb/blob/main/converting-a-simple-jax-function.ipynb "Colab"),有关此表示法的更多文档,请参阅 [此处](https://github.com/google/jax/blob/main/jax/experimental/jax2tf/README.md#shape-polymorphic-conversion "此处"))。
|
tfjs.converters.convert_jax(
prod,
params,
input_signatures=[tf.TensorSpec((None, 2), tf.float32)],
polymorphic_shapes=['(b, 2)')],
model_dir=model_dir)
tfjs_predict_fn = get_tfjs_predict_fn(model_dir)
tfjs_predict_fn(np.array([[1., 2.]])) # 输出: [[0.5, 2. ]]
|
示例 2:MNIST 模型

让我们使用前面相同的转换代码片段,但这次我们将使用 TensorFlow.js 来运行真正的机器学习模型。Flax 提供了一个
Colab 示例,其中包含一个 MNIST 分类器,我们将以此作为起点。
克隆存储库后,可以使用以下命令训练模型
|
train_ds, test_ds = train.get_datasets()
state = train.train_and_evaluate(config, workdir=f'./workdir')
|
这会产生一个
state.apply_fn,它可以用来计算输入图像的 logits。请注意,该函数需要第一个参数为模型权重
state.params。给定一个形状为 [
batch_size, 28, 28, 1] 的输入图像批次,这将生成每个模型(形状为 [
batch_size, 10 ])对十个标签的概率分布的 logits。
|
logits = state.apply_fn({'params': state.params}, imgs)
|
然后,MNIST 模型的
state.apply_fn() 转换方式与上一节完全相同——毕竟,它是一个
纯函数,它以
params 和
images 作为输入,并返回
logits
|
tfjs.converters.convert_jax(
state.apply_fn,
{'params': state.params},
input_signatures=[tf.TensorSpec((1, 28, 28, 1), tf.float32)],
model_dir=tfjs_model_dir,
)
|
在 JavaScript 端,您可以异步加载模型,在
status 文本中显示简单的进度更新,确保在传输模型权重时提供一些反馈。
|
tf.loadGraphModel(modelDir + '/model.json', {
onProgress: p => status.innerText = `loading model: ${Math.round(p*100)}%`
})
|
最小 UI 从
此片段 加载,在回调函数中,您可以调用 TensorFlow.js 模型并输出预测。函数参数
img 是长度为
28*28 的
Uint8Array,它首先被转换为 TensorFlow.js
tf.tensor,然后计算模型输出,并通过
tf.softmax() 函数将其转换为概率。然后,通过调用
.dataSync() 同步等待计算的输出值,并在显示之前将其转换为 JavaScript 数组。
|
ui.onUpdate(img => {
const imgs = tf.tensor(img).cast('float32').reshape([1, 28, 28, 1])
const logits = model.predict(imgs)
const preds = tf.softmax(logits)
const { values, indices } = tf.topk(preds, 10)
ui.showPreds([...values.dataSync()], [...indices.dataSync()])
})
|
然后 Colab 启动了一个 Web 服务器并将端口进行隧道连接,因此您可以扫描手机上的二维码并直接连接到演示。尽管训练报告显示在测试集上的准确率约为 99.1%,但您会发现模型很容易被人类眼睛很容易识别但模型难以识别的数字所迷惑,因为模型只看到了来自 MNIST 数据集的数字(图 3)。
 |
图 3. 我们来自 Colab 的模型在 MNIST 测试数据集上的准确率为 99.1%,但仍令人惊讶地难以识别手写数字。左侧,模型预测了各种数字,而不是“一”。右侧,“一”的绘制方式更像是训练集中的数据。
示例 3:LiT 演示使用 TensorFlow.js 模型编写更现实的应用程序则更加复杂。本节将介绍用于创建 Google AI 博客文章 锁定图像微调:为图像模型添加语言理解功能 中的演示应用程序的主要步骤。请参考该文章以了解 ML 模型实现的技术细节。同时,请确保查看最终的 LiT 演示。 调整模型在开始实现 ML 演示之前,认真考虑不同的选项及其各自的优缺点是一个好时机。
总的来说,您有两种选择:在服务器端基础设施上运行 ML 模型,或在边缘(即访问用户的设备上)运行 ML 模型。 - 在服务器上运行模型的优势在于它可以使用与开发模型时完全相同的框架/代码。像 Streamlit 或 Gradio 这样的库使得围绕此类集中托管模型快速构建交互式 Web 应用程序变得非常容易。运行模型的服务器可能相当强大,使用大量 RAM 和加速器来实时运行最先进的 ML 模型,并且即使是最小的移动设备也能加载此类网站。
- 在设备上运行演示会限制您可以使用的模型的大小,但它具有令人信服的优势
- 从不将数据发送到设备之外,这对隐私和降低延迟都很重要。
- 自由扩展:例如,一个普通的 Web 服务器(例如在 GitHub Pages 上运行的服务器)可以免费为数百或数千个用户提供服务。在这样的规模上在服务器端基础设施上运行一个强大的模型将非常昂贵(巨大的计算量并不便宜)。
您用于演示的模型由两部分组成:图像编码器和文本编码器(见图 4)。
对于计算图像嵌入,您使用一个大型模型,而对于文本嵌入则使用一个小模型。为了使演示运行得更快并产生更好的结果,昂贵的图像嵌入是预先计算的,因此 Tensorflow.js 模型只需要计算文本嵌入,然后比较图像和文本嵌入以计算相似度。 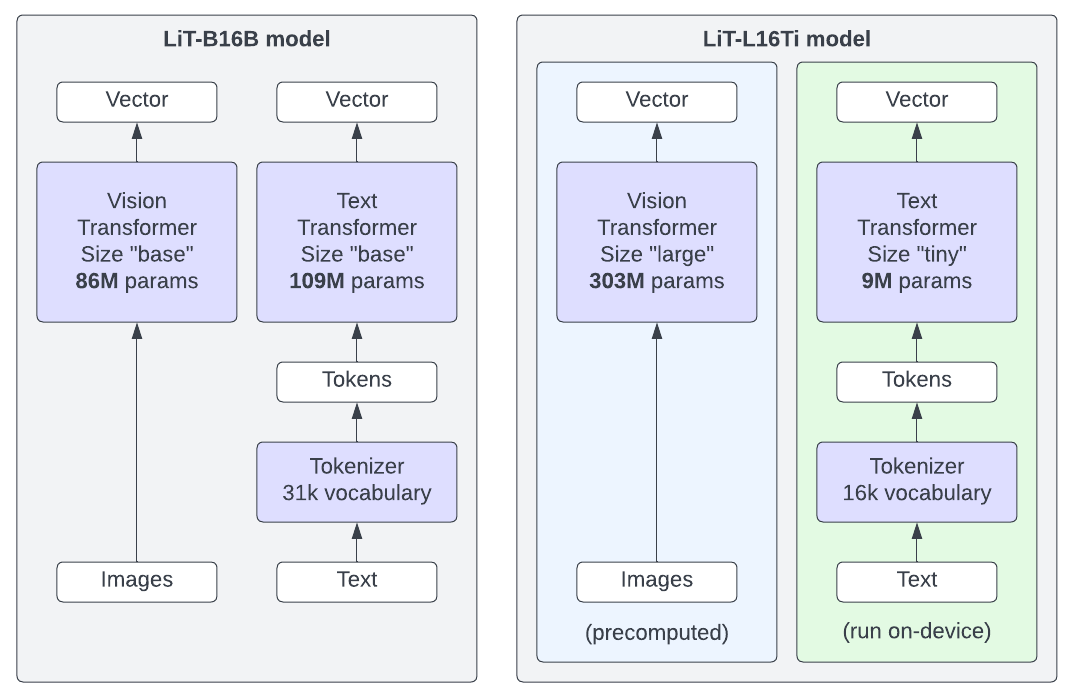 | | 图 4. 像 LiT(或 CLIP)这样的图像/文本模型包含两个编码器,可以分别用于创建图像和文本的向量表示。通常,图像和文本编码器的大小相似(LiT-B16B 模型,左图)。对于演示,我们使用大型图像编码器预先计算图像嵌入,然后使用小型文本编码器(LiT-L16Ti 模型,右图)在设备上运行文本推理。 |
对于演示,我们现在可以免费获得这些强大的 ViT-Large 图像表示,因为我们可以为所有演示图像预先计算它们。这使得我们能够以有限的计算预算制作出令人信服的演示。除了“小型”文本编码器之外,我们还为相同的图像嵌入准备了一个“小型”文本编码器(LiT-L16S),它表现略好,但使用更多带宽来下载模型权重,并且需要更多 GPU 内存才能在设备上运行。我们使用来自 此 Colab 的代码评估了不同的模型
| 图像编码器 | 文本编码器 | 零样本性能 | 模型 | 参数 | FLOPs | 参数 | FLOPs | CIFAR-100 | ImageNet | LiT-B16B | 86M (344 MB) | 36B | 109M (436 MB) | 2.7B | 79.2% | 71.7% | LiT-L16S (“小型”文本编码器) | 303M (1.2 GB) | 123B | 28M (111 MB) | 0.7B | 75.8% | 60.7% | LiT-L16Ti(“小型”文本编码器) | 303M (1.2 GB) | 123B | 9M (36 MB) | 0.2B | 73.2% | 53.4% |
请注意,“零样本性能”仅应视为一个代理。最终,模型的性能需要足以满足演示的需要,在本例中,我们的手动测试表明,即使是最小的文本转换器也能够计算出足以满足演示需求的相似度。接下来,我们使用此 TensorFlow.js 基准测试工具 在不同平台上测试了小型和小型文本编码器的性能(使用“自定义模型”选项,并在 WebGL 后端上对 5x16 个令牌进行基准测试)
| LiT-L16T(“小型”文本编码器) - 基准测试 | LiT-L16S(“小型”文本编码器) - 基准测试 |
| 加载时间 | 预热 | 平均/10 | 峰值内存 | 加载时间 | 预热 | 平均/10 | 峰值内存 | MacBook Pro(Intel i7 2.6GHz / Radeon Pro 5300M) | 1.1s | 0.15s | 0.12s | 33.9 MB | 3.9s | 0.8s | 0.8s | 122 MB | iPad Air(第四代) | 1.3s | 0.6s | 0.5s | 33.9 MB | 2.7s | 2.4s | 2.5s | 141 MB | Samsung S21 G5(手机) | 2.0s | 1.3s | 1.1s | 33.9 MB | - | - | - | - |
请注意,由于模型无法装入内存,上述表格中“Samsung S21 G5”的“小型”文本编码器模型结果缺失。就性能而言,带有“微型”文本编码器的模型产生的结果在大约 0.1-1 秒内,即使在测试过的最小平台上,感觉也相当快。
Lit-LiT 网络应用 |
|
<lit-demo-app></lit-demo-app>
|
此网络组件在
lit-demo-app.ts 中定义,位于
src/components 子目录中,与所有其他网络组件(图像轮播、模型控件等)并排。
对于实际的图像/文本相似性计算,组件
image-prompts.ts 调用模块
src/lit_demo/compute.ts 中的函数,该模块包装了所有 TensorFlow.js 特定代码。
|
export class Model {
/** 对文本进行标记。 */
tokenize(texts: string[]): tf.Tensor { /* ... */ }
/** 计算文本嵌入。 */
embed(tokens: tf.Tensor): tf.Tensor {
return this.model!.execute({inputs: tokens}) as tf.Tensor;
}
/** 计算文本/预计算图像嵌入的相似度。 */
computeSimilarities(texts: string[], imgidxs: number[]) {
const textEmbeddings = this.embed(this.tokenize(texts));
const imageEmbeddingsTransposed = tf.transpose(
tf.concat(imgidxs.map(idx => tf.slice(this.zimgs!, idx, 1))));
return tf.matMul(textEmbeddings, imageEmbeddingsTransposed);
}
/** 对 `computeSimilarities()` 应用 softmax。 */
computeProbabilities(texts: string[], imgidx: number): number[] {
const sims = this.computeSimilarities(texts, [imgidx]);
const row = tf.squeeze(tf.slice(tf.transpose(sims), 0, 1));
return [...tf.softmax(tf.mul(this.def!.temperature, row)).dataSync()];
}
}
|
Colab 中导出的
data/ 目录的父目录在
src/lit/constants.ts 文件中的 baseUrl 中引用。默认情况下,它引用的是官方演示中的模型。当将
baseUrl 替换为不同的服务器时,请确保启用
跨源资源共享。
除了完整的应用程序外,还可以将不包含 UI 的功能部分导出为单个 JavaScript 文件,该文件可以静态链接。查看文件
playground.html 作为示例,并参考
README.md 中的说明了解如何在部署应用程序之前编译整个应用程序或功能部分。
|
<!-- 加载全局符号 `lit`。 -->
<script src="exports_bin.js"></script>
<script>
async function demo() {
lit.setBaseUrl('https://google-research.github.io/vision_transformer/lit');
const model = new lit.Model('tiny');
await model.load();
console.log(model.computeProbabilities(['a dog', 'a cat'], /*imgIdx=*/1);
}
demo();
</script>
|
结论
在本文中,您学习了如何将 JAX 函数和 Flax 模型转换为 TensorFlow.js 格式,该格式可以在浏览器或能够运行 JavaScript 的设备上执行。
第一个示例演示了如何将 JAX 函数转换为 TensorFlow.js 模型,该模型可以加载到 Colab 中进行验证,或在任何具有现代 Web 浏览器的设备上运行 - 这与可以应用于更复杂的 Flax 模型的转换完全相同。第二个示例展示了如何在 Colab 中训练 ML 模型,并在手机上对其进行交互式测试。第三个示例提供了一个
完整模板 用于运行设备上 ML 模型(查看
实时演示)。我们希望此应用程序可以作为使用 TensorFlow.js 的 JAX 模型的客户端演示的良好起点。