https://blog.tensorflowcn.cn/2022/09/fast-reduce-and-mean-in-tensorflow-lite.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjSWMVCl2We_NSDS2a3pt9rcN01yn5qsfD6AxqPHZa6gRCaF8k_0rwvgLpFBl9qQTjeLX0Q08Q7tejJjRC6Lc6cHHwPm4F54T7X2oFe0IE6ry1GoNS96cjP0qI2IBLcxqWk6iZsmbXehucFCjMTV7AIvFtUS_L21RCxnti0iBse0ZZ-vUlwCed0pfsn/s1600/tensorflow-Fast-Reduce-and-Mean-in-TensorFlow-Lite-02.png

作者:Alan Kelly,软件工程师

我们很高兴地宣布 TensorFlow Lite 2.10 版本已经优化了 Reduce 操作(All、Any、Max、Min、Prod、Sum)和 Mean 操作。这些常见的操作符用标量替换多维张量的其中一个或多个维度。Reduce 的 Sum、Product、Min、Max、Bitwise And、Bitwise Or 和 Mean 变体都可用。Reduce 现在对所有可能的输入都很快。
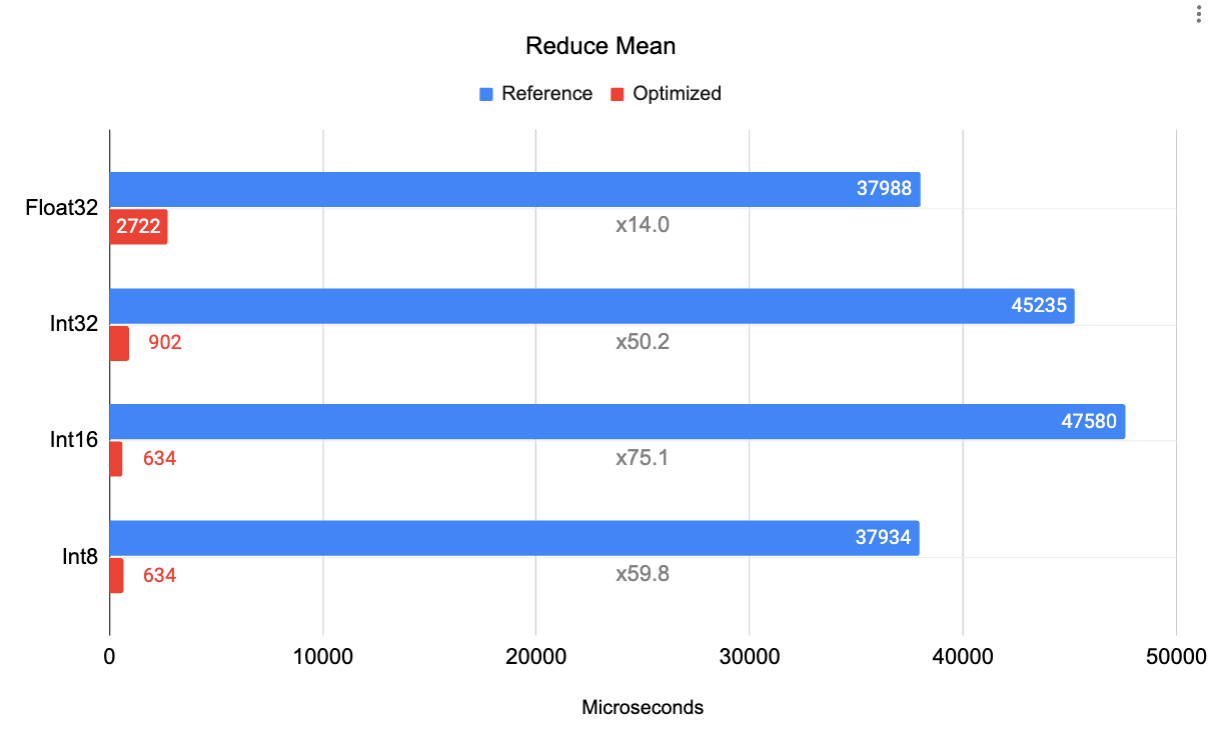 |
| 在 Google Pixel 6 Pro Cortex A55(小核心)上对 Reduce Mean 操作进行基准测试。输入张量是形状为 [32, 256, 5, 128] 的 4D 张量,在轴 [1, 3] 上进行降维,输出是形状为 [32, 5] 的 2D 张量。
|
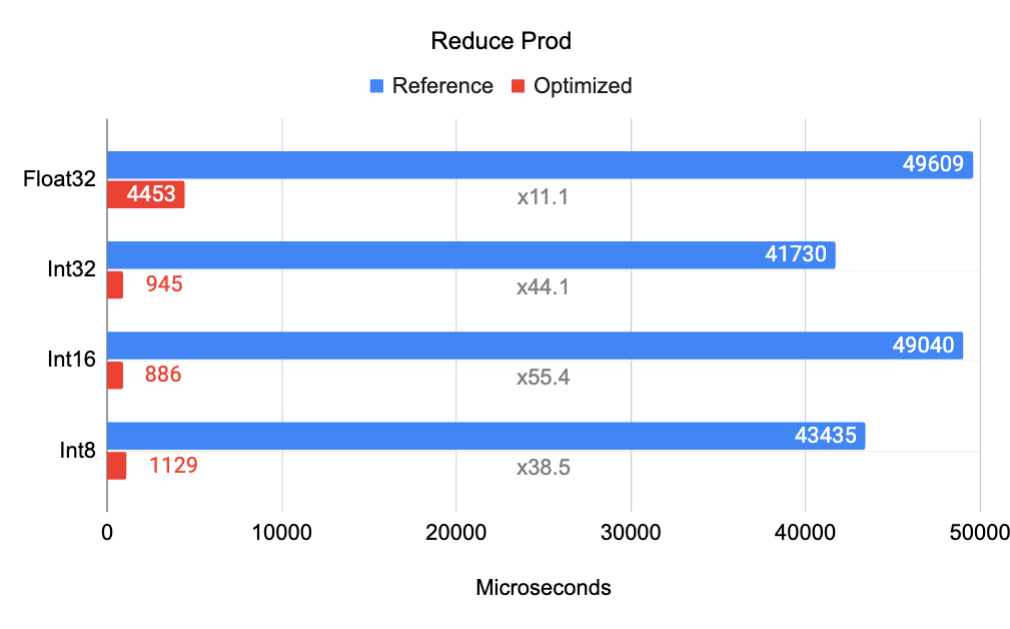 |
| 在 Google Pixel 6 Pro Cortex A55(小核心)上对 Reduce Prod 操作进行基准测试。输入张量是形状为 [32, 256, 5, 128] 的 4D 张量,在轴 [1, 3] 上进行降维,输出是形状为 [32, 5] 的 2D 张量。
|
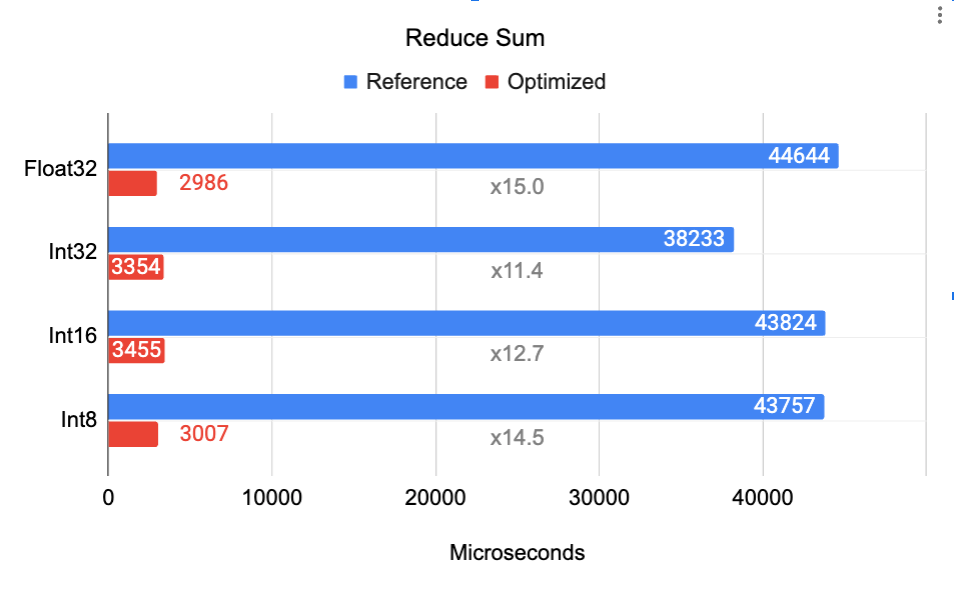 |
| 在 Google Pixel 6 Pro Cortex A55(小核心)上对 Reduce Sum 操作进行基准测试。输入张量是形状为 [32, 256, 5, 128] 的 4D 张量,在轴 [0, 2] 上进行降维,输出是形状为 [256, 128] 的 2D 张量。 |
这些速度提升默认情况下在所有架构上使用最新版本的 TFLite 即可获得。
它是如何工作的?
为了理解这些改进是如何实现的,我们需要从不同的角度看待这个问题。让我们以一个形状为 [3, 2, 5] 的 3D 张量为例。
让我们使用 Reduce Max 在轴 [0] 上对这个张量进行降维。这将给我们一个形状为 [2, 5] 的输出张量,因为维度 0 将被移除。输出张量中的每个元素将包含沿维度 0 的相同位置上的三个元素中的最大值。所以第一个元素将是 max{0, 10, 20} = 20。这将给出以下输出
为了简化,让我们将原始的 3D 张量重新整形为一个形状为 [3, 10] 的 2D 张量。这与原始张量完全相同,只是可视化方式不同。
通过对维度 0 取每列的最大值,对它进行降维,得到
然后我们将其重新整形回原始形状 [2, 5]
这演示了如何简单地改变我们可视化张量的方式,就能显著简化实现。在本例中,维度 1 和 2 是相邻的,并没有被降维。这意味着我们可以将它们折叠成一个大小为 2 x 5 = 10 的更大的维度,将 3D 张量转换为 2D 张量。对于被降维的相邻维度,我们也可以这样做。
让我们来看看同一个形状为 [3, 2, 5] 的 3D 张量的所有可能的 Reduce 排列。
在所有 8 个排列中,只有两个 3D 排列在我们重新可视化输入张量后仍然存在。对于任何数量的维度,只有两种可能的降维排列:行或列。所有其他排列都简化为更低的维度。
这就是高效且简单的降维操作符的诀窍,因为我们不再需要计算输入和输出张量索引,而且我们的内存访问模式更加缓存友好。
这也允许编译器自动向量化整数降维。编译器不会自动向量化浮点数,因为浮点数加法不具有交换性。你可以在这里查看移除冗余轴的代码
这里,以及降维代码
这里。
改变我们可视化张量的方式是一个强大的代码简化和优化技术,被许多 TensorFlow Lite 操作符所使用。
下一步
我们一直在努力添加新的操作符,并加快现有操作符的速度。我们很乐意听到你的模型如何从这项工作中受益。可以通过
TensorFlow 论坛 与我们联系。感谢您的阅读!











