 时间序列数据在应用机器学习中无处不在。数据通常会随时间变化,或者仅在特定时间点可用或有价值。例如,市场价格和天气状况不断变化。时间序列数据在决策任务中也往往具有高度区分性。例如,两次心跳之间的变化率和间隔提供了有关一个人身体健康的宝贵见解,而网络日志的时间模式用于检测配置问题和入侵。因此,在 ML 应用中结合时间序列数据和时间信息至关重要。
时间序列数据在应用机器学习中无处不在。数据通常会随时间变化,或者仅在特定时间点可用或有价值。例如,市场价格和天气状况不断变化。时间序列数据在决策任务中也往往具有高度区分性。例如,两次心跳之间的变化率和间隔提供了有关一个人身体健康的宝贵见解,而网络日志的时间模式用于检测配置问题和入侵。因此,在 ML 应用中结合时间序列数据和时间信息至关重要。 |
时间序列是时间序列数据最常用的表示形式。它们由均匀采样的值组成,这对于表示聚合信号很有用。但是,时间序列有时不足以表示可用数据的丰富性。相反,多元时间序列可以一起表示多个信号,而时间序列或事件集可以表示非均匀采样的测量值。多索引时间序列可用于表示不同时间序列之间的关系。在这篇博文中,我们将使用多元多索引时间序列,也称为事件集。别担心,它们并不像听起来那么复杂。
让我们从一个简单的示例开始。我们从一家虚构的在线商店收集了销售记录。每当客户购买商品时,我们都会记录以下信息:购买时间、客户 ID、购买的商品和商品价格。
数据集存储在一个 CSV 文件中,每行代表一个交易
$ head -n 5 sales.csv timestamp,client,product,price 2010-10-05 11:09:56,c64,p35,405.35 2010-09-27 15:00:49,c87,p29,605.35 2010-09-09 12:58:33,c97,p10,108.99 2010-09-06 12:43:45,c60,p85,443.35
|
查看数据对于理解数据和发现潜在问题至关重要。我们的首要任务是将销售数据加载到一个 EventSet 中并绘制它。
# 导入 Temporian import temporian as tp # 加载 CSV 数据集 sales = tp.from_csv("/tmp/sales.csv") # 打印有关 EventSet 的详细信息 sales |
这段代码片段加载并打印数据

# 绘制 EventSet 的 "price" 特征 sales["price"].plot() |
 |
我们已经展示了如何在短短几行代码中加载和可视化时间数据。但是,生成的绘图非常繁忙,因为它在同一个视图中显示了所有客户的所有交易。
对时间数据的常见操作是计算移动总和。让我们计算并绘制过去七天每笔交易的销售总额。移动总和可以使用 moving_sum 运算符计算。
weekly_sales = sales["price"].moving_sum(tp.duration.days(7)) weekly_sales.plot() |
 |
在前面的步骤中,我们计算了整个商店的总销售额移动总和。但是,如果我们想分别计算每个产品或客户的销售额滚动总和呢?
对于这项任务,我们可以使用索引。
# 按 "product" 对数据进行索引 sales_per_product = sales.add_index("product") # 为每个产品计算移动总和 weekly_sales_per_product = sales_per_product["price"].moving_sum( tp.duration.days(7) ) # 绘制结果 weekly_sales_per_product.plot() |
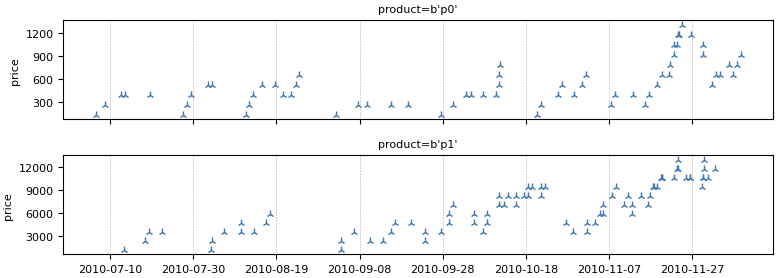 |
我们的数据集包含单个客户交易。要将此数据与机器学习模型一起使用,通常将它聚合到时间序列中,在时间序列中,数据按时间均匀采样。例如,我们可以每周汇总销售额,或计算每天过去一周的总销售额。
但是,请注意,将交易数据聚合到时间序列中可能会导致一些数据丢失。例如,单个交易时间戳和值将丢失。这是因为聚合的时间序列将仅代表每个时间段的总销售额。
让我们分别为每个产品计算每天过去一周的总销售额。
# 数据每天采样 daily_sampling = sales_per_product.tick(tp.duration.days(1)) weekly_sales_daily = sales_per_product["price"].moving_sum( tp.duration.days(7), sampling=daily_sampling, # 新功能 ) weekly_sales_daily.plot() |
 |
数据准备阶段完成后,可以将数据导出到 Pandas DataFrame 作为最后一步。
tp.to_pandas(weekly_sales_daily) |

Temporian 的一个关键应用是为机器学习模型清理数据并进行特征工程。它非常适合预测、异常检测、欺诈检测以及其他数据持续产生的任务。
在本例中,我们展示了如何训练一个 TensorFlow 模型来预测每个产品的下一天销售额,方法是使用过去每个产品的销售额。我们将向模型提供不同级别的销售额汇总以及日历信息。
首先,让我们扩充我们的数据集,并将其转换为与表格 ML 模型兼容的数据集。
sales_per_product = sales.add_index("product") # 每天创建一个示例 daily_sampling = sales_per_product.tick(tp.duration.days(1)) # 计算不同窗口长度的移动总和。 # 机器学习模型能够选择重要的特征。 features = [] for w in [3, 7, 14, 28]: features.append(sales_per_product["price"] .moving_sum( tp.duration.days(w), sampling=daily_sampling) .rename(f"moving_sum_{w}")) # 星期几等日历信息 # 对人类活动非常有参考意义。 features.append(daily_sampling.calendar_day_of_week()) # 标签是未来一天延迟/泄露的每日销量。 label = (sales_per_product["price"] .leak(tp.duration.days(1)) .moving_sum( tp.duration.days(1), sampling=daily_sampling, ) .rename("label")) # 收集特征和标签。 dataset = tp.glue(*features, label) dataset |
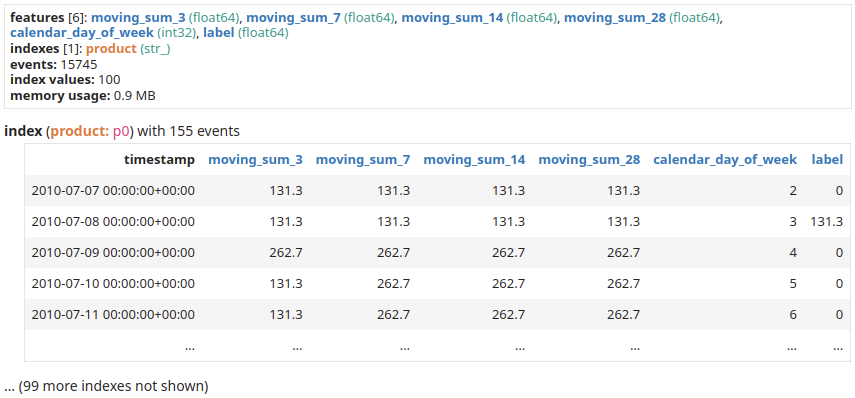 |
然后我们可以将数据集从 EventSet 转换为 TensorFlow 数据集格式,并训练随机森林。
import tensorflow_decision_forests as tfdf def extract_label(example): example.pop("timestamp") # 不要使用时间戳作为特征 label = example.pop("label") return example, label tf_dataset = tp.to_tensorflow_dataset(dataset).map(extract_label).batch(100) model = tfdf.keras.RandomForestModel(task=tfdf.keras.Task.REGRESSION,verbose=2) model.fit(tf_dataset) |
就这样,我们训练了一个模型来预测销量。现在我们可以查看模型的变量重要性,以了解哪些特征最重要。
model.summary() |
在摘要中,我们可以找到 INV_MEAN_MIN_DEPTH 变量重要性
Type: "RANDOM_FOREST" Task: REGRESSION ... Variable Importance: INV_MEAN_MIN_DEPTH: 1. "moving_sum_28" 0.342231 ################ 2. "product" 0.294546 ############ 3. "calendar_day_of_week" 0.254641 ########## 4. "moving_sum_14" 0.197038 ###### 5. "moving_sum_7" 0.124693 # 6. "moving_sum_3" 0.098542
|
我们看到 moving_sum_28 是重要性最高的特征(0.342231)。这表明过去 28 天的销量总和对模型非常重要。为了进一步改进我们的模型,我们应该添加更多的时间聚合特征。 product 特征也很重要。
为了更好地了解模型本身,我们可以绘制随机森林中的其中一棵树。
tfdf.model_plotter.plot_model_in_colab(model, tree_idx=0, max_depth=2) |
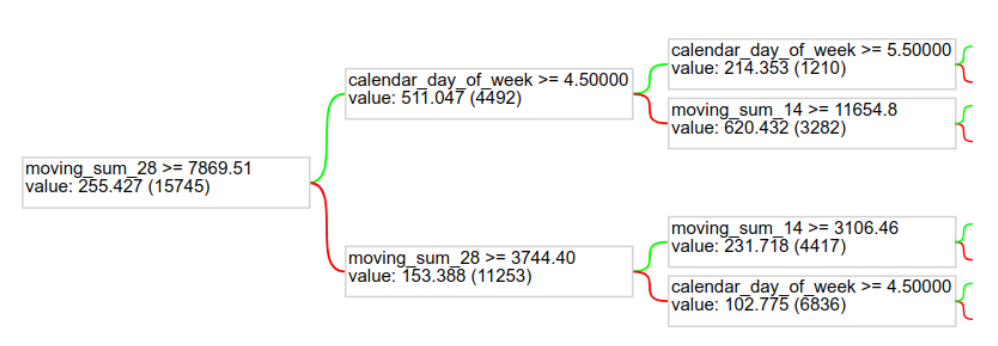 |
我们演示了一些简单的 数据预处理。如果您想查看其他在不同数据领域上处理时间数据的示例,请查看 Temporian 教程。值得注意的是
- 心率分析 ❤️ 检测单个心跳并从 Physionet 中的原始心电图信号中提取与心率相关的特征。
- M5 竞赛 🛒 预测 M5 Makridakis 预测竞赛中的零售销量。
- 贷款结果预测 🏦 准备关系型 SQL 数据以预测已完成贷款的结果。
- 检测支付卡欺诈 💳 实时检测欺诈性支付卡交易。
- 有监督和无监督异常检测 🔎 执行数据分析和特征工程以检测一组服务器资源使用指标中的异常。
我们演示了如何在 TensorFlow 中使用 Temporian 库处理交易等时间数据。现在您也可以尝试一下!
- 加入 我们的 Discord 服务器,分享您的反馈或寻求帮助。
- 阅读 3 分钟了解 Temporian 指南,以快速入门。
- 查看 用户指南。
- 访问 GitHub 仓库。
要了解有关使用 TensorFlow Decision Forests 进行模型训练的更多信息
- 访问 官方网站。
- 按照 初学者笔记本。
- 查看 各种指南和教程。
- 查看 TensorFlow 论坛。


2023 年 9 月 11 日 — 发布者:Google:Mathieu Guillame-Bert、Richard Stotz、Robert Crowe、Luiz GUStavo Martins (Gus)、Ashley Oldacre、Kris Tonthat、Glenn Cameron 和 Tryolabs:Ian Spektor、Braulio Rios、Guillermo Etchebarne、Diego Marvid、Lucas Micol、Gonzalo Marín、Alan Descoins、Agustina Pizarro、Lucía Aguilar、Martin Alcala Rubi时间数据 在应用机器学习应用中无处不在。数据通常会随时间变化……





