
快速傅里叶变换 是一种重要的信号处理方法,广泛应用于加速卷积、提取特征和模型正则化等多个方面。分布式快速傅里叶变换(Distributed FFT)提供了一种在处理图像类数据集的模型中计算傅里叶变换的方法,这些数据集太大,无法放入单个加速器设备的内存中。在之前的 Google 研究论文“TPU 上的大规模离散傅里叶变换”中,Tianjian Lu 实施了一种分布式 FFT 算法,作为 TensorFlow v1 的一个库。这项工作展示了 TensorFlow v2 中通过新的 TensorFlow 分布式 API DTensor 添加的原生支持的分布式 FFT。
DTensor 是 TensorFlow 的扩展,用于同步分布式计算。它通过称为 单程序多数据 (SPMD) 扩展的程序和张量。DTensor 为机器学习中广泛使用的传统数据和模型并行模式提供统一的 API。
分布式 FFT 的 API 接口与 TensorFlow 中的原始 FFT 相同。用户只需将分片张量作为输入传递给 TensorFlow 中现有的 FFT 操作,例如 tf.signal.fft2d。分布式 FFT 的输出也会被分片。
import TensorFlow as tf from TensorFlow.experimental import dtensor # Set up devices device_type = dtensor.preferred_device_type() if device_type == 'CPU': cpu = tf.config.list_physical_devices(device_type) tf.config.set_logical_device_configuration(cpu[0], [tf.config.LogicalDeviceConfiguration()] * 8) if device_type == 'GPU': gpu = tf.config.list_physical_devices(device_type) tf.config.set_logical_device_configuration(gpu[0], [tf.config.LogicalDeviceConfiguration(memory_limit=1000)] * 8) dtensor.initialize_accelerator_system() # Create a mesh mesh = dtensor.create_distributed_mesh(mesh_dims=[('x', 1), ('y', 2), ('z', 4)], device_type=device_type) # Set up a distributed input Tensor input = tf.complex( tf.random.stateless_normal(shape=(2, 2, 4), seed=(1, 2), dtype=tf.float32), tf.random.stateless_normal(shape=(2, 2, 4), seed=(2, 4), dtype=tf.float32)) init_layout = dtensor.Layout(['x', 'y', 'z'], mesh) d_input = dtensor.relayout(input, layout=init_layout) # Run distributed fft2d. DTensor determines the most efficient # layout of of d_output. d_output = tf.signal.fft2d(d_input) |
以下实验表明,分布式 FFT 可以通过利用多个设备的内存来处理比非分布式 FFT 更多的数据。这种权衡是在通信和数据转置上花费额外的时间,从而减慢计算速度。
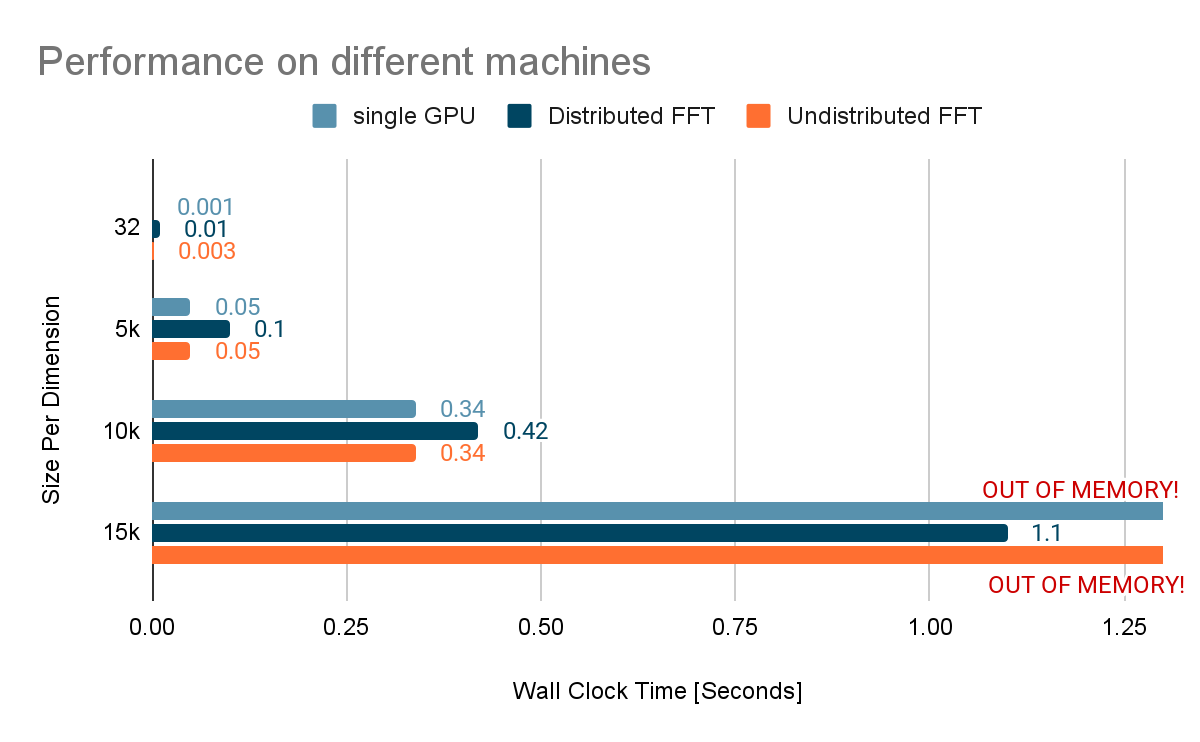 |
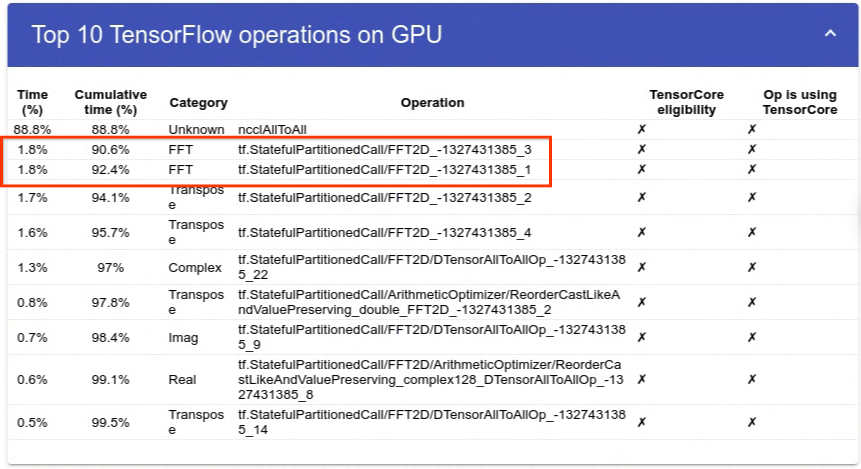
这一现象在 10K*10K 分布式 FFT 实验的分析结果中得到了详细的展示。TensorFlow 中分布式 FFT 的当前实现遵循简单的 shuffle+local FFT 方法,这也是其他流行的分布式 FFT 库(如 FFTW 和 PFFT)使用的。值得注意的是,两个本地 FFT 操作仅占总时间的 3.6%(15 毫秒)。这大约是非分布式 fft2d 的时间的 1/3。大部分计算时间都花在了数据洗牌上,由 ncclAllToAll 操作表示。请注意,这些实验是在 8xV100 GPU 系统上进行的。
 |
该功能是新的,我们采用了一种最简单的分布式 FFT 算法。一些微调或提高性能的想法是
- 切换到不同的 DFT/FFT 算法。
- 根据特定的 FFT 大小调整 NCCL 通信设置,可以提高网络带宽的利用率,并提高速度。
- 减少集体操作的数量,以最大限度地减少带宽需求。
- 使用 N 维本地 FFT,而不是多个 1 维本地 FFT。
尝试新的分布式 FFT!我们欢迎您在 TensorFlow 论坛 上提供反馈,并期待与您合作提高性能。您的意见将非常宝贵!


2023 年 8 月 24 日 — 由 Google 实习生 - DTensor 团队的 孙瑞娇 发表快速傅里叶变换 是一种重要的信号处理方法,广泛应用于加速卷积、提取特征和模型正则化等多个方面。分布式快速傅里叶变换(Distributed FFT)提供了一种在处理图像类数据集的模型中计算傅里叶变换的方法,这些数据集太大,无法放入单个加速器设备的内存中。在之前的 Google 研究论文“TPU 上的大规模离散傅里叶变换”中,Tianjian Lu 实施了一种分布式 FFT 算法,作为 TensorFlow v1 的一个库。这项工作展示了 TensorFlow v2 中通过新的 TensorFlow 分布式 API DTensor 添加的原生支持的分布式 FFT。





