
大型语言模型 (LLM) 正在席卷全球,这得益于它们强大的文本生成、语言翻译和以连贯且信息丰富的方式回答问题的能力。在 2023 年的 Google I/O 上,我们发布了 PaLM API 作为“公开预览”,以便许多开发人员可以开始使用它构建应用程序。虽然 PaLM API 已经拥有关于其 广泛使用和最佳实践 的出色文档,但在这篇博客中,我们将采取更集中的方法来探讨如何利用 LLM 来增强您的 ML 系统在实际应用中的应用:推荐系统。
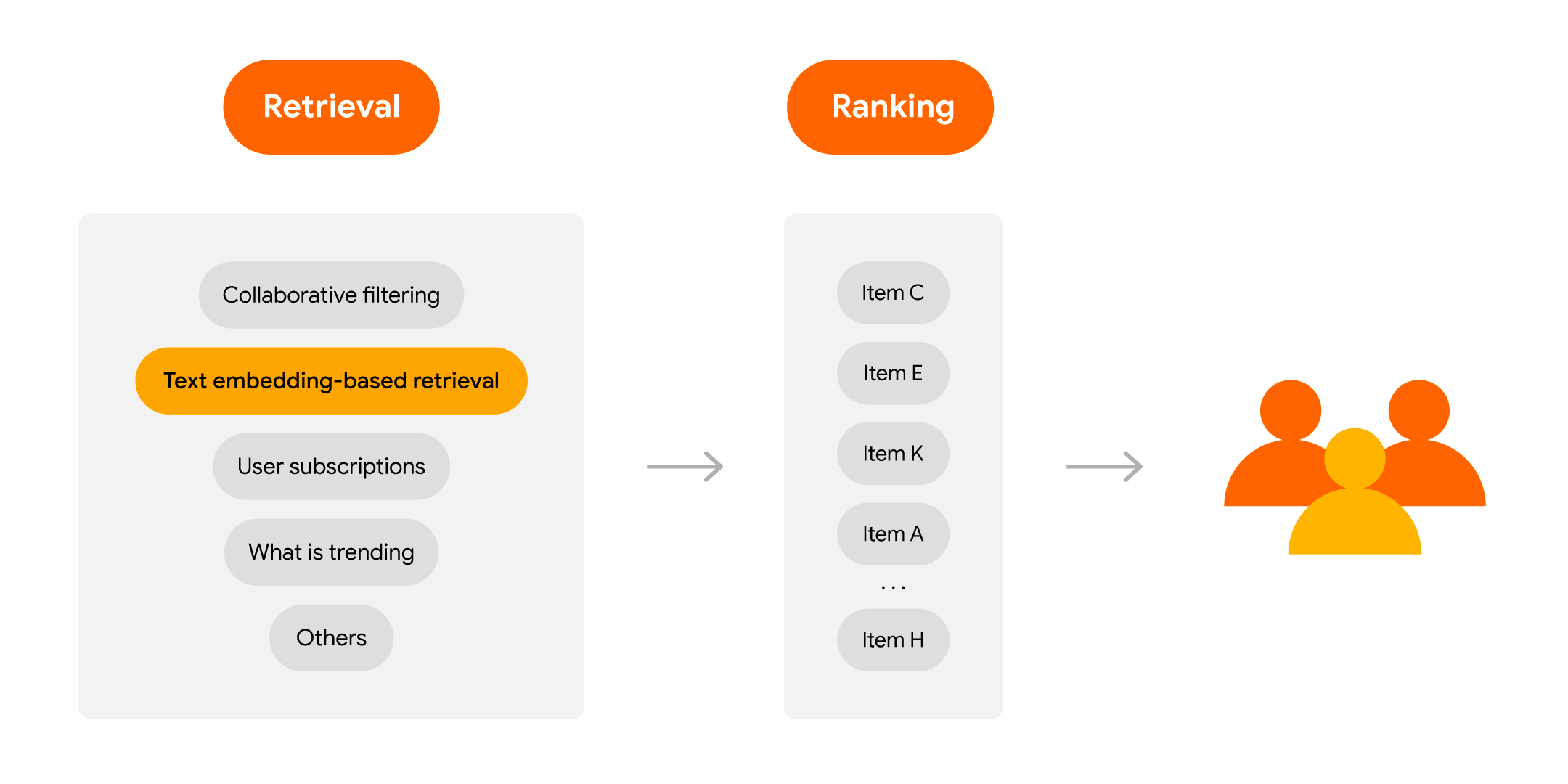
作为回顾,现代推荐系统通常遵循检索-排序架构,这使它们能够有效且高效地过滤和排序相关项目,以最大限度地提高生产中的效用。您可以通过此 codelab 来学习如何使用 TensorFlow 和 Flutter 构建一个完整的电影推荐系统。
 |
我们将讨论如何将 LLM 集成到此检索-排序管道中。
如果您已经可以访问 Bard,您可以要求它以对话的方式为您创建推荐。以下是如何向 Bard 索取电影推荐的示例
 |
作为开发人员,您可以使用 PaLM API 聊天服务 在您自己的应用程序中构建类似的功能,只需付出最小的努力
prompt = """您是一名电影推荐者,您的工作是根据用户输入推荐新电影。因此,对于用户 42,他今晚想看一些具有艺术元素的剧情片。您能推荐三个吗?仅输出标题。不要包括其他文本.""" response = palm.chat(messages=prompt) print(response.last) # 当然,以下是我向用户 42 推荐的三个具有艺术元素的剧情片: # # 1. 生命之树 (2011) # 2. 20 世纪的女人 (2016) # 3. 佛罗里达乐园 (2017) # # 希望您喜欢这些电影! |
PaLM API 还允许您帮助您的用户继续探索并以对话的方式交互式地细化推荐(例如,要求用另一部电影替换佛罗里达乐园),这就是 聊天服务 的设计目的。这种对话式推荐界面(想想在您的购物应用程序中引导客户的知识渊博的聊天机器人)为用户提供了流畅且个性化的体验,有时会成为您现有推荐界面的非常吸引人的补充。
如果您的系统知道您的用户可能喜欢什么,推荐会更有用。找出用户兴趣的一种方法是查看他们的历史活动,然后进行推断。这通常被称为“顺序推荐”,因为推荐器会查看已交互项目的序列,并推断出要推荐的内容。通常,您需要使用一个 ML 库(即 TensorFlow Recommenders)来实现这一点。但现在有了 LLM 的强大功能,您也可以使用 PaLM API 文本服务 来实现。
prompt = """你是一个电影推荐者,你的工作是根据用户观看的电影序列推荐新电影。你特别关注电影的顺序,因为它很重要。用户 42 按顺序观看了以下电影:“Margin Call”、“The Big Short”、“Moneyball”、“The Martian”,推荐三部电影并按优先级排序。仅限标题。不要包含任何其他文本。""" response = palm.generate_text( model="models/text-bison-001", prompt=prompt, temperature=0 ) print(response.result) # 1. The Wolf of Wall Street # 2. The Social Network # 3. Inside Job |
本示例使用 4 部已观看的电影提示 文本服务,并要求 PaLM API 根据过去电影的顺序生成新的推荐。
在现代推荐引擎的排名阶段,需要根据某些标准对候选列表进行排序。这通常使用学习排名库(例如,TensorFlow Ranking)来预测排序来完成。现在你可以使用 PaLM API 来做到这一点。以下是一个预测电影评分的示例
prompt = """你是一个电影推荐者,你的工作是根据用户对电影的先前评分预测用户的评分(从 1 到 5,5 为最高)。用户 42 对以下电影进行了评分:“Moneyball” 4.5 “The Martian” 4 “Pitch Black” 3.5 “12 Angry Men” 5 预测用户对“The Matrix”的评分。仅输出评分。不要包含其他文本。""" response = palm.generate_text(model="models/text-bison-001", prompt=prompt) print(response.result) # 4.5 |
PaLM API 预测了《黑客帝国》的高分。你可以要求 PaLM API 对一组候选电影逐一预测评分,然后按顺序排序,最后做出最终推荐;这个过程被称为 “逐点排名”。你甚至可以使用 PaLM API 来进行 成对排名 或 列表式排名,如果你相应地调整提示。
有关使用 LLM 进行评分预测的更全面研究,你可以参考谷歌的这篇 论文。
在这一点上你可能会问:到目前为止,所有用例都涉及 LLM 已经知道的知名电影,所以也许候选项目需要在 LLM 中提前捕获(在训练阶段)?如果我有 LLM 事先不知道的私人物品怎么办?我该如何使用 PaLM API 呢?
不用担心。在这种情况下,用于嵌入的 PaLM API 可以帮助你。基本思想是将与你的项目相关的文本(例如,产品描述、电影情节)嵌入到向量中,并使用 最近邻搜索 技术(即,使用 TensorFlow 中的 tf.math.top_k 操作进行暴力搜索或 Google ScaNN/Chroma 进行近似搜索)来识别类似的项目进行推荐,根据用户查询。让我们通过一个简单的示例来了解一下。
假设你正在构建一个新闻应用程序,并且希望在每篇新闻文章的底部向用户推荐类似的新闻。首先,你可以通过调用 PaLM API 嵌入服务来嵌入所有新闻文章,如下所示
embedding = palm.generate_embeddings(model='embedding-gecko-001', text='示例新闻文章文本')['embedding'] |
为了简单起见,让我们假设你将所有新闻文本及其嵌入存储在一个简单的 Pandas DataFrame 中,其中包含 2 列:news_text 和 embedding。然后你可以使用以下方法向用户推荐有趣的新闻
def recommend_news(query_text, df, topk=5): """ 基于用户查询推荐新闻 """ query_embedding = palm.generate_embeddings(model='embedding-gecko-001', text=query_text) dot_products = np.dot(np.stack(df['embedding']), query_embedding['embedding']) result = tf.math.top_k(dot_products, k=topk) indices = result.indices.numpy() return df.loc[indices]['news_text'] recommend_news('当前正在阅读的新闻', dataframe, 5) |
recommend_news 函数计算查询嵌入与所有新闻文章的预先计算的嵌入之间的 点积相似性,然后识别 5 篇与用户正在阅读的内容最相似的新闻文章。
这种方法通常是一种快速有效的生成候选者并根据项目相似性创建推荐的方法。它可能足以满足许多用例,并且在 项目冷启动情况 中特别有用。
在实践中,现代大型推荐系统的候选者生成阶段通常包含多个来源。例如,您可以使用文本嵌入式检索、协同过滤、用户订阅(例如,YouTube 上关注账号的新上传内容)、实时趋势项目(例如,突发新闻)等的混合器。因此,利用 PaLM API 嵌入服务 可以为现有推荐系统中的检索阶段提供有益的补充。
 |
此外,您还可以将文本嵌入用作推荐模型中的侧边特征。文本嵌入通过描述文本捕获候选项目的语义信息,并可能有助于提高模型精度。例如,在这个 TensorFlow Recommenders 特征预处理教程 中,如果您使用 LLMs 预先计算了电影剧情的文本嵌入,当连接所有嵌入时,将它们注入模型作为侧边特征非常容易。
class MovieModel(tf.keras.Model): # ...... def call(self, inputs): return tf.concat( [ self.title_embedding(inputs["movie_title"]), self.title_text_embedding(inputs["movie_title"]), inputs["movie_plot_embedding"], # inject movie plot embedding ], axis=1, ) |
默认的 PaLM Embedding 服务会为任何文本返回一个包含 768 个浮点数的向量,这可能太多了。您可以通过使用电影情节嵌入矩阵初始化 tf.keras.layers.Embedding 层,然后在其之上叠加一个全连接层来将维度降低到更少的维度,从而减少维度。
我们分享了几个关于利用大型语言模型来增强推荐系统的想法。很明显,这仅仅是触及了表面,因为这里还有很多没有涵盖的内容。还要注意,它们可能还需要很长时间才能投入生产(即延迟和成本问题)。但我们希望这篇博文能激发您开始思考如何使用大型语言模型改进您自己的推荐系统。
最后,我们将在 2023 年 6 月 9 日举办关于推荐系统的在线开发者峰会。如果您想了解更多关于 Google 与构建推荐系统相关的产品,请随时报名参加 这里。


2023 年 6 月 6 日 — 作者:魏伟,开发者倡导者大型语言模型 (LLM) 正在席卷全球,这得益于它们强大的生成文本、翻译语言和以连贯且信息丰富的方式回答问题的能力。在 2023 年的 Google I/O 大会上,我们发布了 PaLM API 作为“公开预览版”,以便许多开发者可以开始使用它构建应用程序。虽然 PaLM API 已经拥有出色的文档 o…





