
决策树是梯度提升树和随机森林的基础构建块,它们是表格数据中最流行的两种机器学习模型。 要了解决策树的工作原理以及如何解释您的模型,可视化是必不可少的。
TensorFlow 最近发布了一个新的 教程,展示了如何使用 dtreeviz,一个最先进的可视化库,来可视化和解释 TensorFlow 决策森林树。
dtreeviz 库首次发布于 2018 年,现在是最受欢迎的决策树可视化库。该库一直在不断更新和改进,并且有一个庞大的用户社区可以 提供支持并回答问题。有一个有用的 YouTube 视频 和文章介绍了 dtreeviz 的设计。
让我们演示如何使用 dtreeviz 来解释决策树预测。
从基本层面上讲,决策树是一种机器学习模型,它通过检查和压缩训练数据到二叉树中,来学习观察结果和目标值之间的关系。 决策树中的每个叶子负责做出特定的预测。 对于回归树,预测是一个值,例如价格。 对于分类树,预测是一个目标类别,例如癌症或非癌症。
从决策树的根到特定叶子预测器的任何路径都会经过一系列(内部)决策节点。 每个决策节点将单个特征的值与其在训练期间学习到的特定分割点值进行比较。 进行预测意味着从根向下遍历树,比较特征值,直到我们到达一个叶子。 考虑以下简单的决策树,它试图根据两个特征(腿的数量和眼睛的数量)来对动物进行分类。
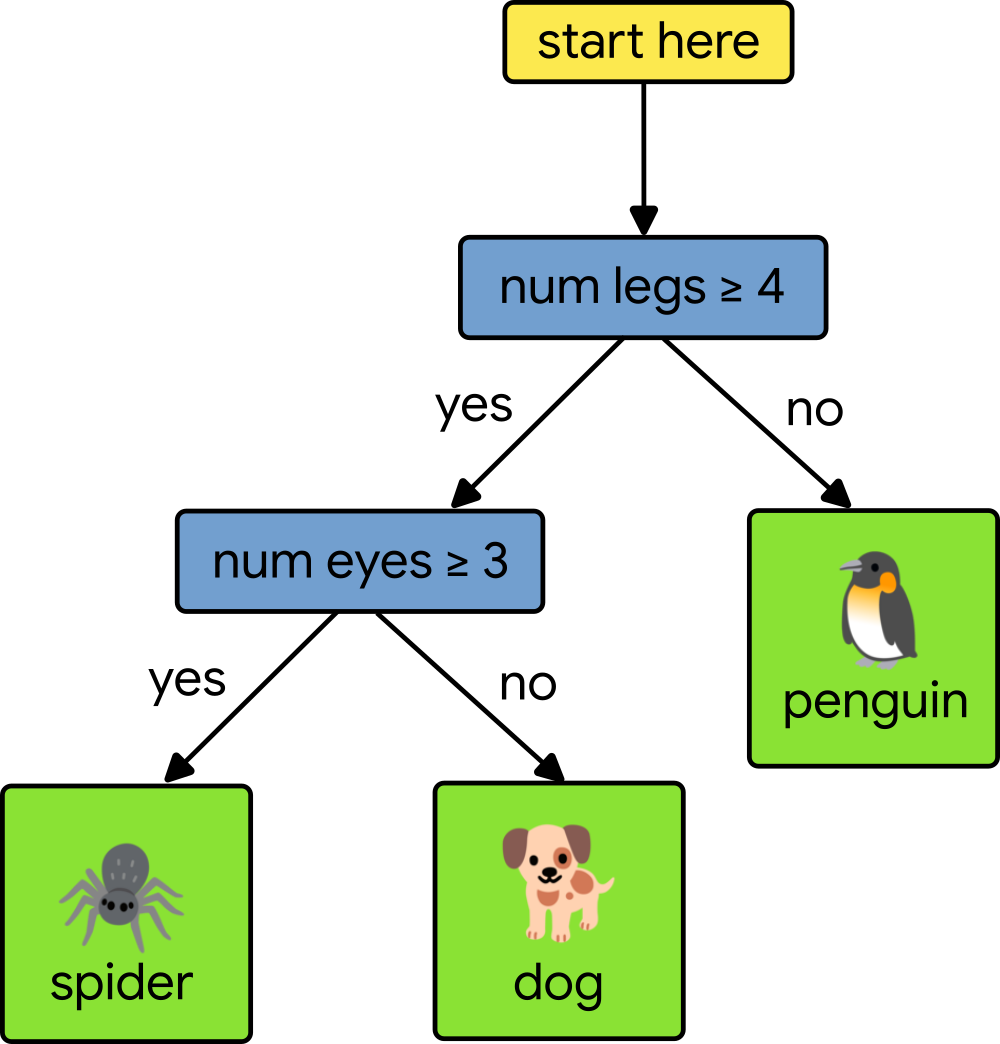 |
假设我们的测试动物有四条腿和两只眼睛。 为了对测试动物进行分类,我们从树的根开始,并将我们的测试动物的腿的数量与四进行比较。 由于腿的数量等于四,因此我们向左移动。 接下来,我们将眼睛的数量测试到三。 由于我们的测试动物只有两只眼睛,因此我们向右移动,到达一个叶子节点,它给了我们一个狗的预测。 要了解更多信息,请查看此 关于决策树的课程。
为了解释决策树预测,我们使用 dtreeviz 来可视化树中每个决策节点如何分割特定特征的域,以及每个叶子中训练实例的分布。 例如,以下是来自训练在 企鹅 数据集上的随机森林的分类树的前几层
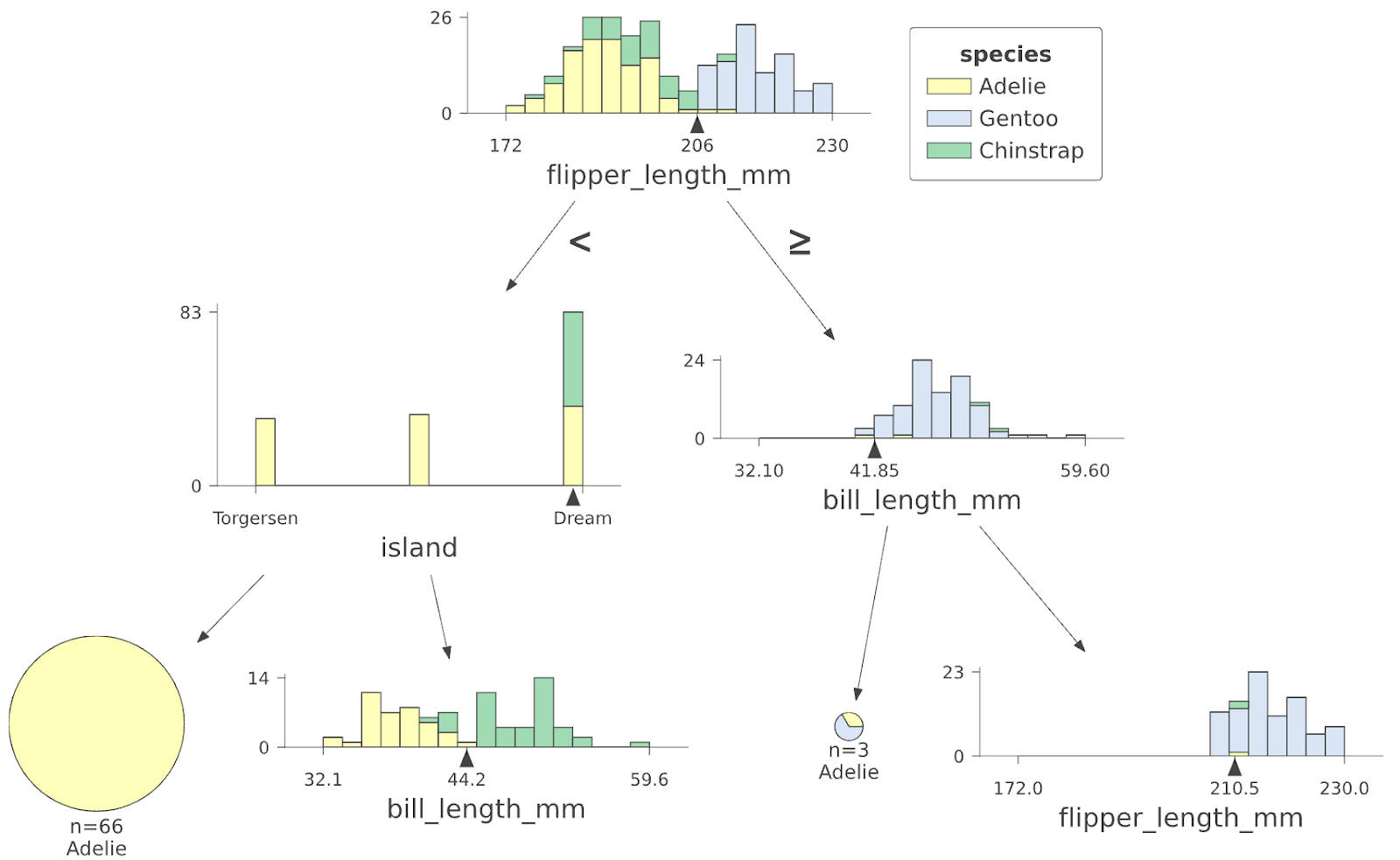 |
为了对测试企鹅进行预测,这棵决策树首先测试 flipper_length_mm 特征,如果它小于 206,它就会向下到左侧,然后测试 island 特征; 否则,如果 flipper 长度大于或等于 206,它将向下到右侧,并测试 bill_length_mm 特征。(查看 教程 以了解可视化元素的描述。)
用于生成该树的代码很短。 给定一个名为 cmodel 的分类器模型,我们收集并封装有关数据和模型的所有信息,然后要求 dtreeviz 可视化该树
penguin_features = [f.name for f in cmodel.make_inspector().features()]
penguin_label = "species" # 分类目标标签的名称
viz_cmodel = dtreeviz.model(cmodel,
tree_index=3, # 从森林中选择树
X_train=train_ds_pd[penguin_features],
y_train=train_ds_pd[penguin_label],
feature_names=penguin_features,
target_name=penguin_label,
class_names=classes)
viz_cmodel.view()以下是来自训练在 鲍鱼 数据集上的随机森林的回归树的前几层
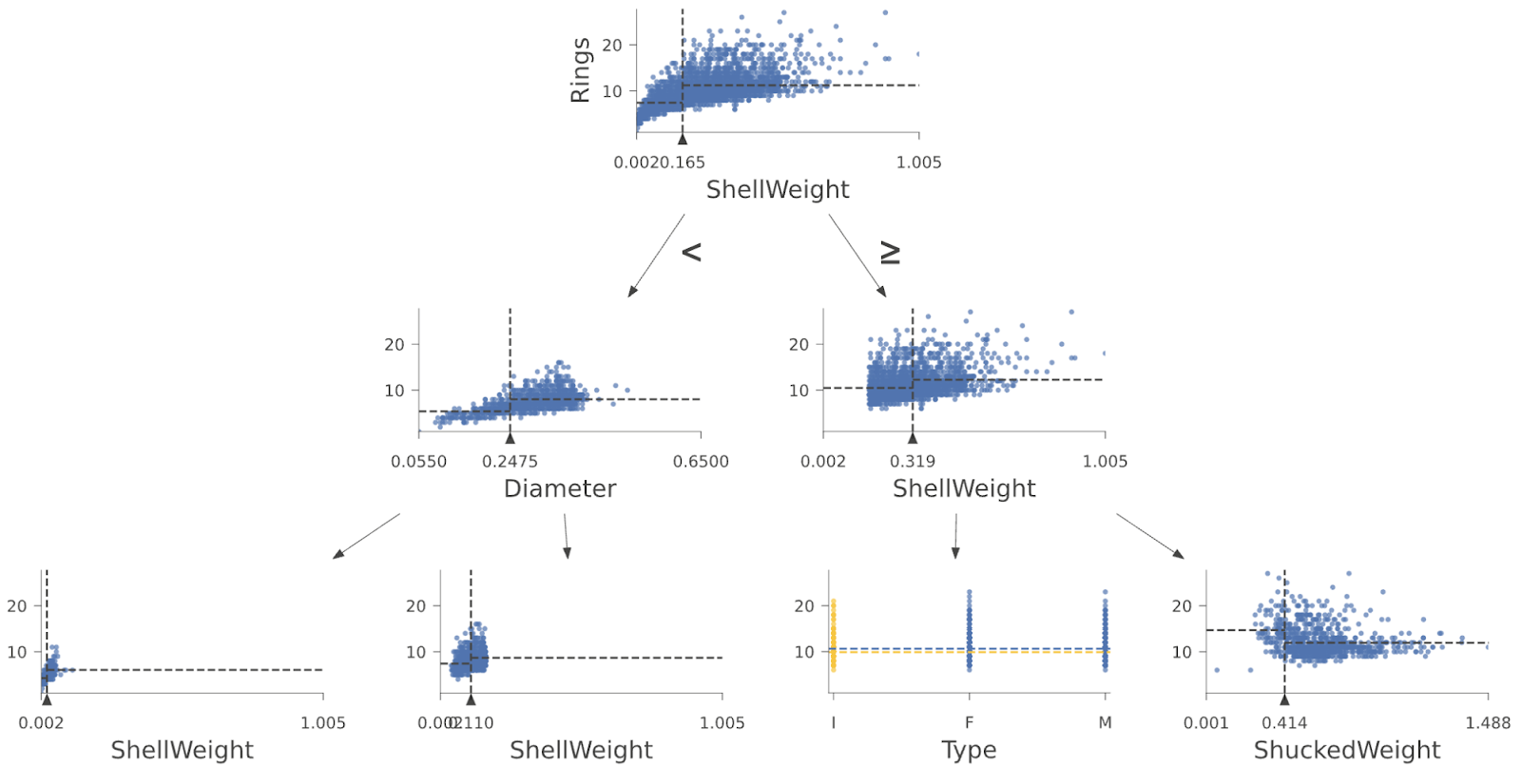 |
另一个有用的解释工具是可视化特定测试实例(特征向量)如何从根到特定叶子蜿蜒穿过树。 通过查看决策树在进行预测时所采取的路径,我们可以了解为什么测试实例以特定方式被分类。 我们知道测试了哪些特征以及针对什么范围的值。 想象一下被银行拒绝贷款。 查看决策树可以告诉我们确切的原因(例如,信用评分过低或债务收入比过高)。 以下是一个示例,展示了决策树对特定企鹅实例做出的决策,其中路径以橙色框突出显示,测试实例特征显示在左下方
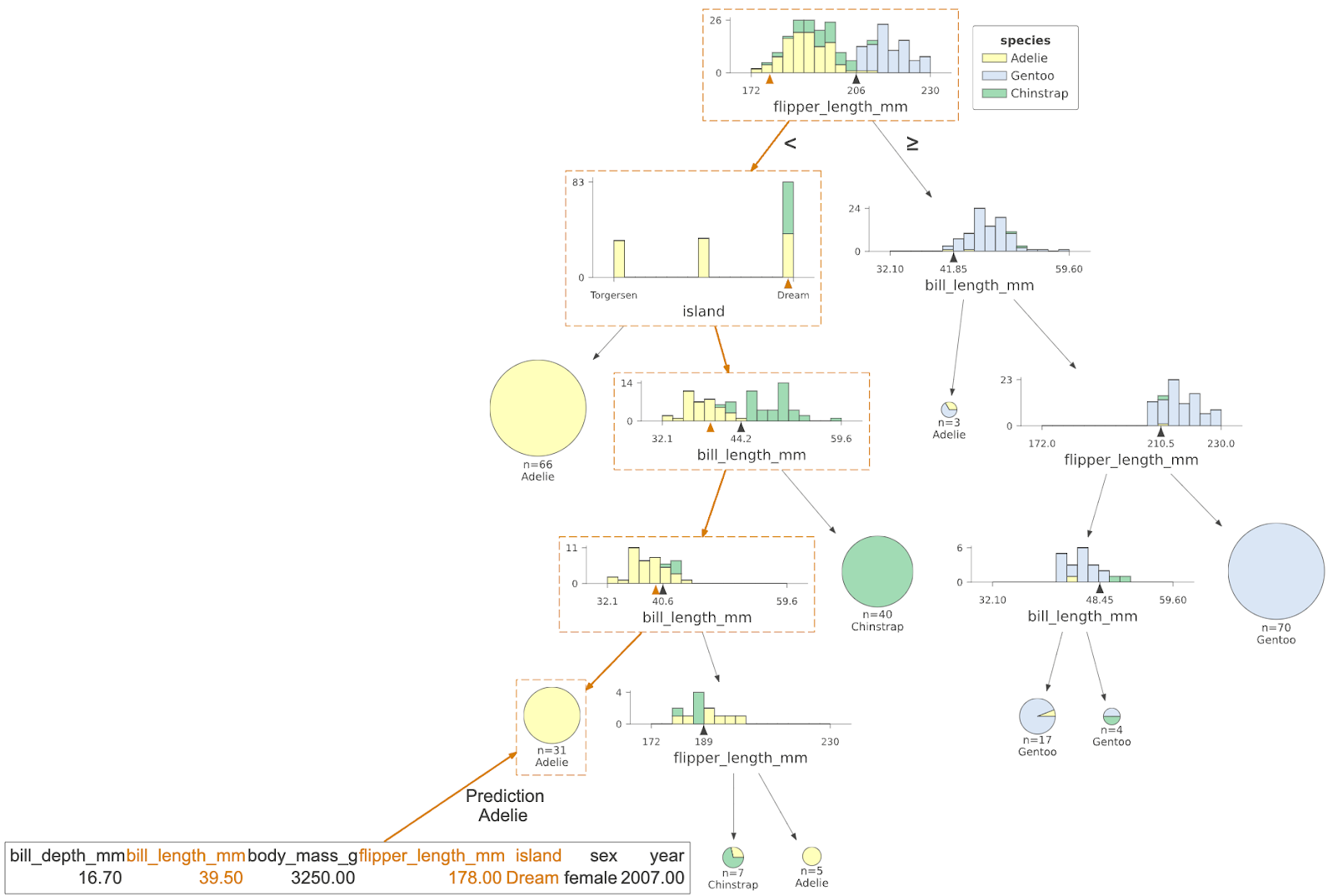 |
您还可以通过调用 viz_cmodel.ctree_leaf_distributions() 来查看有关叶子内容的信息。 例如,以下是一个图表,显示了企鹅数据集的叶子 ID 与每个类别的样本数之间的关系
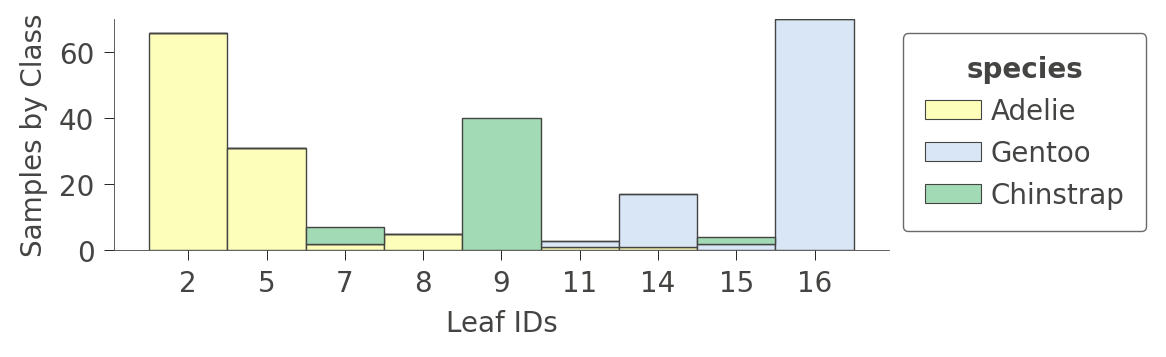 |
对于回归器,叶子图显示了每个叶子中实例的目标(预测)变量的分布,例如以下图表显示了来自鲍鱼决策树的图表
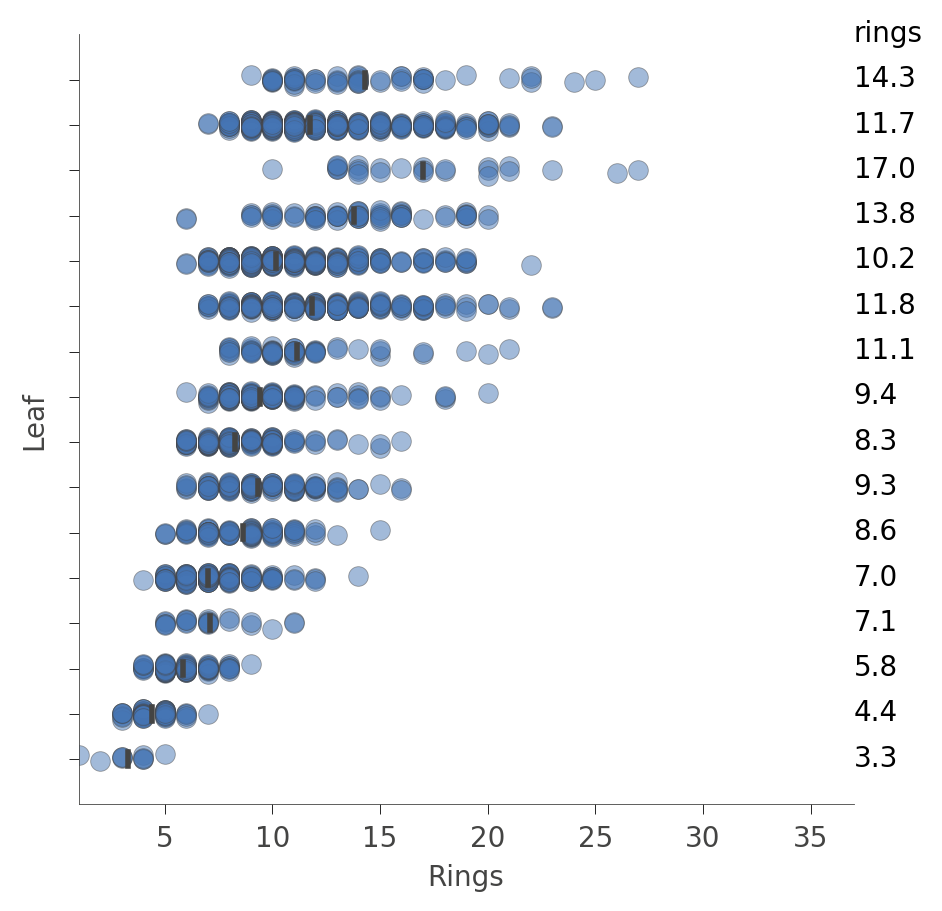 |
该图中的每“行”代表一个特定的叶子,蓝色圆点表示与该叶子相关的实例在训练过程中预测的 rings 值的分布。
该库可以做更多的事情; 这只是一小部分。 您的下一步是查看 教程! 然后,在您自己的树模型上尝试 dtreeviz。 为了更深入地了解决策树是如何构建的以及它们如何划分特征空间以进行预测,您可以观看 YouTube 视频 或有关 dtreeviz 设计 的文章。 享受!


2023 年 6 月 6 日 — 由 Terence Parr,Google 发表决策树是梯度提升树和随机森林的基础构建块,它们是表格数据中最流行的两种机器学习模型。 要了解决策树的工作原理以及如何解释您的模型,可视化是必不可少的。TensorFlow 最近发布了一个新的 教程,展示了如何使用 dtreeviz,一个最先进的可视化库,来可视化和解释 TensorFlow 决策森林树。…





