作者:Google Cloud ML 专家 Jeremy Wortz 和机器学习专家 Jordan Totten

来自 Google Cloud AI 和机器学习 的交叉发布
在之前的一篇 博文 中,我们概述了在 Google Cloud 上实施推荐系统的三种方法,包括 (1) 使用 Recommendations AI 的全托管解决方案,(2) 来自 BigQuery ML 的矩阵分解,以及 (3) 使用双塔编码器和 Vertex AI Matching Engine 的自定义深度检索技术。在这篇博文中,我们将深入探讨选项 (3),并演示如何通过使用 Vertex AI 从头开始实施端到端的候选检索工作流来构建播放列表推荐系统。具体来说,我们将涵盖
- 检索模型的演变以及为什么双塔编码器在深度检索任务中很受欢迎
- 使用 Spotify 百万播放列表数据集 (MPD) 构建播放列表延续用例
- 使用 TensorFlow Recommenders (TFRS) 库开发自定义双塔编码器
- 在 Vertex AI Matching Engine 中使用近似最近邻 (ANN) 索引提供候选嵌入
所有相关代码可以在此 GitHub 存储库 中找到。
为了满足低延迟服务要求,大规模推荐器通常部署到生产环境中作为 多阶段系统。第一阶段(候选检索)的目标是从大型(>100M 个元素)候选项目语料库中筛选出相关的子集(约数百个)项目,供下游排序和过滤任务使用。为了优化此检索任务,我们考虑两个核心目标
- 在模型训练期间,找到将所有知识编译到
查询、候选嵌入中的最佳方法。- 在模型服务期间,以足够快的速度检索相关项目以满足延迟要求
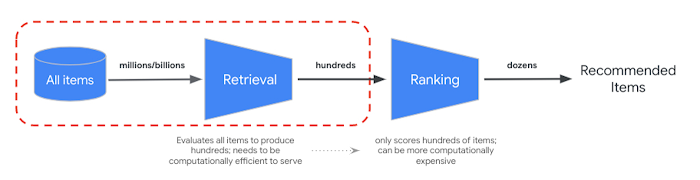 |
| 图 1:多阶段推荐系统的概念组件;这篇博文的重点是第一阶段,候选检索。 |
双塔架构在检索任务中很受欢迎,因为它们捕获了查询和候选实体的语义,并将它们映射到一个共享的 嵌入空间,以便语义上相似的实体聚集在一起。这意味着,如果我们计算给定查询的 向量嵌入,我们可以搜索嵌入空间以找到最接近(最相似)的候选。由于这些基于神经网络的检索模型利用元数据、上下文和特征交互,因此它们可以生成高度信息丰富的嵌入,并提供灵活性以适应各种业务目标。
 |
| 图 2:双塔编码器模型是嵌入式搜索的一种特定类型,其中一个深度神经网络塔生成查询嵌入,另一个塔计算候选嵌入。计算两个嵌入向量的 点积 来确定候选与查询的接近程度(相似度)。来源:宣布 ScaNN:高效向量相似性搜索。 |
虽然这些功能有助于实现有用的查询、候选嵌入,但我们仍然需要解决检索延迟要求。为此,双塔架构提供了另一个优势:能够解耦查询和候选项目的推断。这种解耦意味着所有候选项目的嵌入都可以预先计算,从而将服务计算减少到 (1) 将查询转换为嵌入向量,以及 (2) 搜索相似的向量(在预先计算的候选者中)。
当候选数据集扩展到数百万(或数十亿)个向量时,相似性搜索通常会成为模型服务的计算瓶颈。将搜索放松为近似距离计算会导致显着的延迟改进,但我们需要最大限度地减少对搜索精度(即相关性、召回率)的负面影响。
在论文 使用各向异性向量量化加速大规模推理 中,Google 研究人员通过一种新颖的压缩算法解决了这种速度-精度权衡,与 以前最先进的方法 相比,该算法提高了检索的相关性和速度。在 Google,这种技术被广泛采用,以支持搜索、YouTube、广告、Lens 等领域的深度检索用例。虽然它在开源库 (ScaNN) 中可用,但实施、调整和扩展它仍然具有挑战性。为了帮助团队利用这项技术,而无需运营开销,Google Cloud 通过 Vertex AI Matching Engine 提供了这些功能(以及更多功能)作为托管服务。
本文的目的是演示如何使用 Vertex AI 实现这些深度检索技术,并讨论团队需要为其用例评估的决策和权衡。
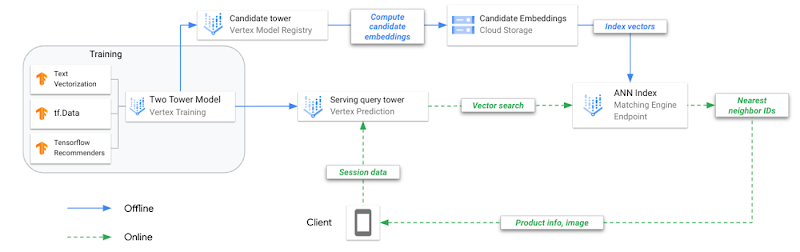 |
| 图 3:在 Vertex AI 上进行双塔训练和部署的参考架构。 |
为了更好地理解双塔架构的优势,让我们回顾一下候选检索中的三个关键建模里程碑。
传统的检索系统高度依赖于基于标记的匹配,其中候选者是使用 n 元语法倒排索引检索的。这些系统具有可解释性,易于维护(例如,无需训练数据),并且能够实现高精度。但是,它们通常会遇到召回率差(即,难以找到给定查询的所有相关候选者)的问题,因为它们寻找的是具有关键字精确匹配的候选者。虽然它们仍然被用于某些搜索用例,但如今许多检索任务要么被嵌入式技术改编,要么被嵌入式技术取代。
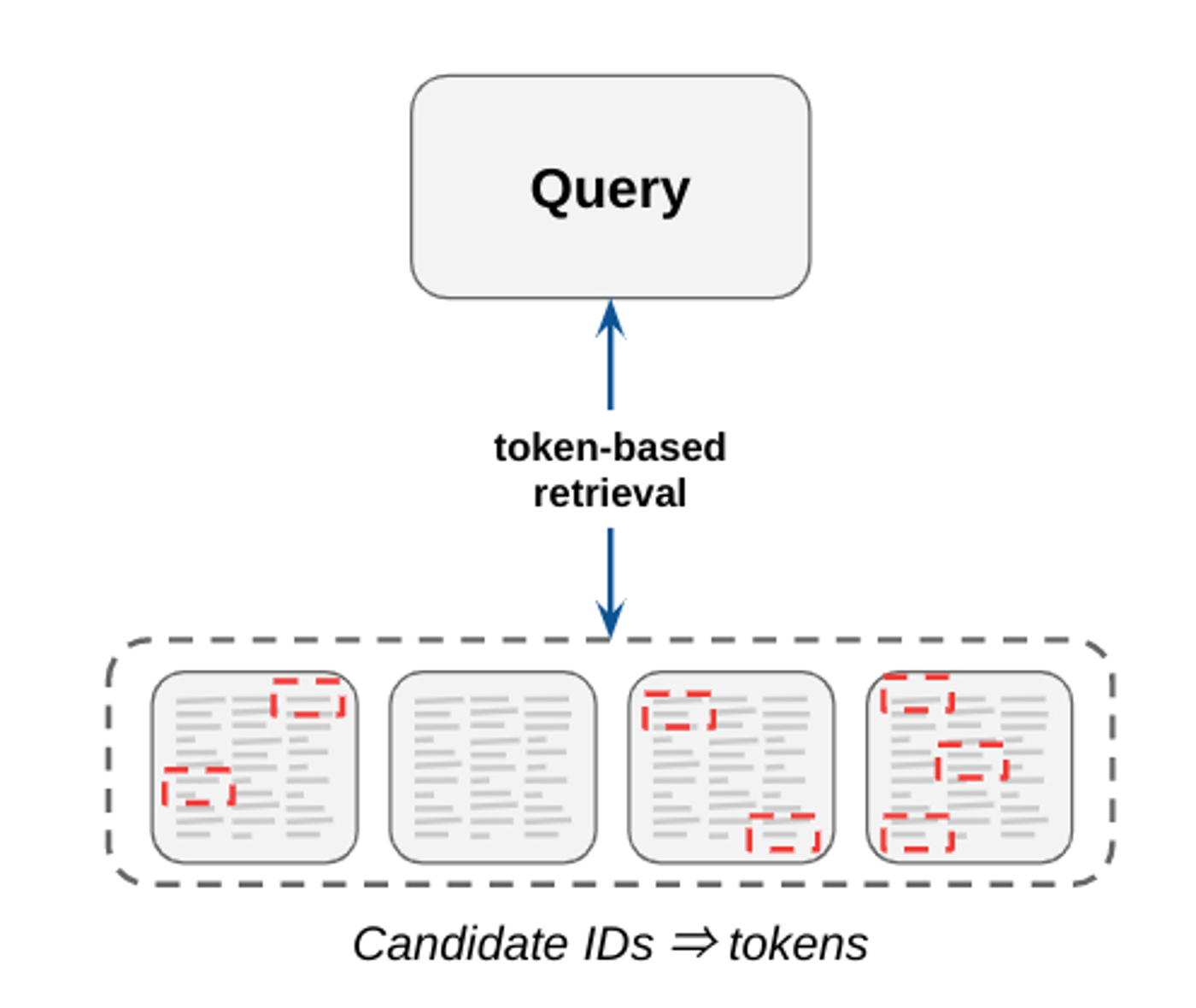 |
| 图 4:基于标记的匹配通过匹配查询和候选项目中找到的关键字来选择候选项目。 |
基于分解的检索引入了一种简单的基于嵌入的模型,该模型通过捕获查询、候选对之间的相似性并将其映射到共享的嵌入空间来提供更好的 泛化。这种 协同过滤 技术的主要优势之一是,嵌入是根据隐式查询-候选交互自动学习的。从根本上讲,这些模型对完整的查询-候选交互(共现)矩阵进行分解,以生成查询和候选者的较小、密集嵌入表示,其中这些嵌入向量的乘积是对交互矩阵的良好近似。想法是,通过将完整矩阵压缩成 k 维,模型可以学习描述查询、候选对的 k 个主要潜在因素,这些因素与建模任务有关。
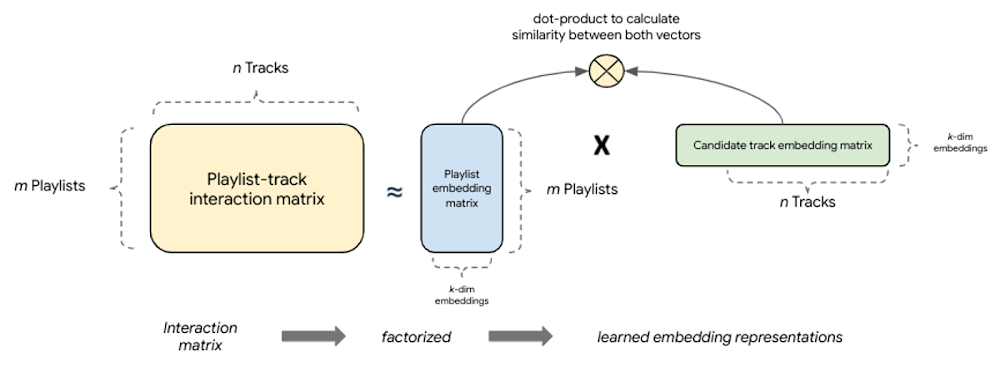 |
| 图 5:基于分解的模型将查询-候选交互矩阵分解成两个较低秩矩阵的乘积,这些矩阵捕获查询-候选交互。 |
检索的最新建模范式通常被称为神经深度检索 (NDR),它生成相同的嵌入表示,但使用深度学习来创建它们。NDR 模型(如双塔编码器)通过使用连续的网络层处理输入特征来应用深度学习,以学习数据的层次表示。实际上,这会导致一个神经网络充当信息蒸馏管道,其中原始的、多模态特征被反复转换,使得有用信息被放大,无关信息被过滤。这导致了一个高度表达的模型,能够学习非线性关系和更复杂的特征交互。
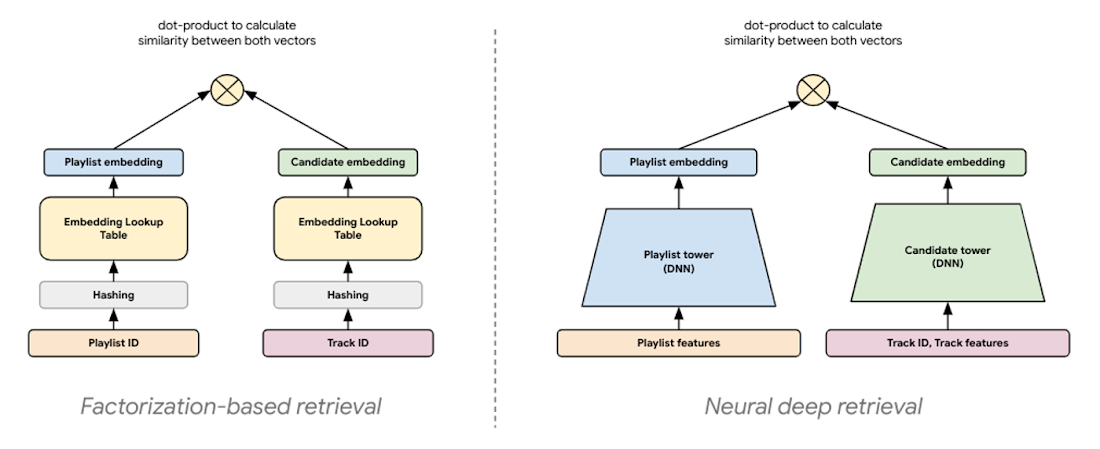 |
| 图 6:NDR 架构(如双塔编码器)在概念上与分解模型类似。两者都是基于嵌入的检索技术,计算查询和候选者的低维向量表示,其中这两个向量的相似度是通过计算它们的 点积 来确定的。 |
在双塔架构中,每个塔都是一个神经网络,它处理查询或候选输入特征以生成这些特征的嵌入表示。由于嵌入表示只是长度相同的向量,因此我们可以计算这两个向量的 点积 来确定它们的接近程度。这意味着嵌入空间的方向由训练示例中每个查询、候选对的点积决定。
除了提高表达能力和泛化能力外,这种架构还为服务提供了优化机会。由于每个塔只使用其各自的输入特征来生成向量,因此训练好的塔可以单独投入使用。解耦塔的推理以进行检索意味着当我们在野外遇到它的配对时,我们可以预先计算我们想要查找的内容。这也意味着我们可以对每个推理任务进行不同的优化。
- 使用训练好的候选塔运行批预测作业,以预先计算所有候选的嵌入向量,并附加 NVIDIA GPU 以加速计算。
- 将预先计算好的候选嵌入压缩到针对低延迟检索优化的 ANN 索引;将索引部署到端点以进行服务。
- 将训练好的查询塔部署到端点,以实时将查询转换为嵌入,并附加 NVIDIA GPU 以加速计算。
训练双塔模型并使用 ANN 索引对其进行服务,这与训练和服务传统机器学习 (ML) 模型不同。为了说明这一点,让我们回顾一下实施此技术的关键步骤。
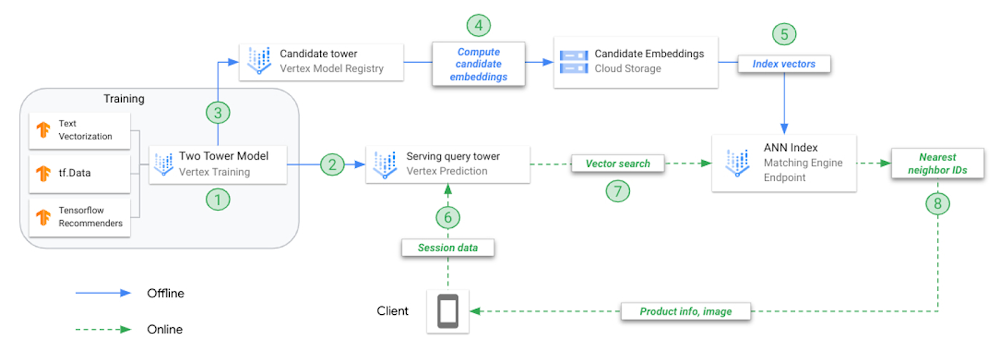 |
| 图 7:在 Vertex AI 上进行双塔训练和部署的参考架构。 |
- 离线训练组合模型(双塔);每个塔分别保存以用于不同的任务。
- 将查询塔上传到 Vertex AI 模型注册表并部署到在线端点。
- 将候选塔上传到 Vertex AI 模型注册表。
- 请求候选塔预测每个候选曲目的嵌入,并将嵌入保存在 JSON 文件中。
- 从嵌入 JSON 创建 ANN 服务索引,将其部署到在线索引端点。
- 用户应用程序使用 playlist 数据调用 endpoint.predict(),模型返回表示该播放列表的嵌入向量。
- 使用播放列表嵌入向量来搜索 N 个最近邻居(候选曲目)。
- 匹配引擎返回 N 个最近邻居的产品 ID。
在本例中,我们使用 MPD 来构建推荐用例,即播放列表延续,其中为给定的播放列表(查询)推荐候选曲目。此数据集可公开获得,并为此演示提供了几个好处。
- 包括实体之间的真实关系(例如,播放列表、曲目、艺术家),这些关系很难复制。
- 足够大,可以复制生产中可能发生的扩展性问题。
- 各种特征表示和数据类型(例如,播放列表和曲目 ID、原始文本、数值、日期时间);能够使用来自 Spotify Web 开发者 API 的其他元数据来丰富数据集。
- 团队可以通过收听检索到的候选曲目来分析建模决策的影响(例如,为自己的 Spotify 播放列表生成推荐)。
为推荐系统创建训练示例是一项非平凡的任务。与任何 ML 用例一样,训练数据应准确地反映我们试图解决的潜在问题。未能做到这一点会导致模型性能低下以及对用户体验的意外后果。来自 用于 YouTube 推荐的深度神经网络 论文的其中一项教训强调,过度依赖“点击率”等特征会导致推荐点击诱饵(即用户很少完成的视频),而“观看时间”等特征则更好地反映了用户的参与度。
训练示例应代表数据中的语义匹配。对于播放列表延续,我们可以将语义匹配视为将播放列表(即一组曲目、元数据等)与足以使用户保持参与其聆听会话的曲目配对。我们的训练示例的结构如何影响这一点?
- 训练数据来自正向
查询,候选对。- 在训练期间,我们将查询和候选特征分别通过其各自的塔进行前向传播,以生成两个向量表示,从中我们计算代表其相似度的点积。
- 训练后,在服务之前,调用候选塔来预测(预先计算)所有候选项目的嵌入。
- 在服务时,模型处理给定播放列表的特征并生成向量嵌入。
- 播放列表的向量嵌入用于在预先计算的候选索引中查找最相似的向量。
- 嵌入空间中候选向量和播放列表向量的放置,以及它们之间的距离,由训练示例中反映的语义关系定义。
最后一点很重要。由于我们的嵌入空间的质量决定了我们检索的成功,因此创建此嵌入空间的模型需要从最好地说明给定播放列表与相似曲目之间关系的训练示例中学习。
这种高度依赖于配对数据选择的相似性概念突出了准备描述语义匹配的特征的重要性。在播放列表标题,曲目标题 对上训练的模型将以与在聚合的播放列表音频特征,曲目音频特征 对上训练的模型不同的方式定位候选曲目。
从概念上讲,由播放列表标题,曲目标题 对组成的训练示例将创建一个嵌入空间,其中所有属于相同或相似标题的播放列表(例如,海滩氛围 和海滩曲调)的曲目将比属于不同播放列表标题的曲目(例如,海滩氛围 对锻炼曲调)更靠近在一起;而由聚合的播放列表音频特征,曲目音频特征 对组成的示例将创建一个嵌入空间,其中所有属于具有相似音频特征的播放列表(例如,乐器即兴演奏的现场录音 和高能量乐器)的曲目将比属于具有不同音频特征的播放列表(例如,乐器即兴演奏的现场录音 对带有大量歌词的原声曲目)的曲目更靠近在一起。
这些示例的直觉是,当我们将丰富的曲目-播放列表特征结构化为描述曲目在特定播放列表中出现的格式时,我们可以将这些数据馈送到一个双塔模型,该模型可以学习父播放列表和子曲目之间的所有利基关系。现代深度检索系统通常会考虑用户资料、历史参与度和上下文。虽然在本例中我们没有用户和上下文数据,但它们可以轻松地添加到查询塔中。
在使用 TFRS 构建检索模型时,两个塔是使用 模型子类化 实现的。每个塔都单独构建为一个可调用对象,以处理输入特征值、将其传递给特征层并连接结果。这意味着塔只是生成一个连接的向量(即查询或候选的表示;无论塔代表什么)。首先,我们定义塔的基本结构并将其作为子类化的 Keras 模型实现。
class Playlist_Tower(tf.keras.Model): ''' produced embedding represents the features of a Playlist known at query time ''' def __init__(self, layer_sizes, vocab_dict): super().__init__() # TODO: build sequential model for each feature here def call(self, data): ''' defines what happens when the model is called ''' all_embs = tf.concat( [ # TODO: concatenate output of all features defined above ], axis=1) # pass output to dense/cross layers if self._cross_layer is not None: cross_embs = self._cross_layer(all_embs) return self.dense_layers(cross_embs) else: return self.dense_layers(all_embs) |
我们通过为每个由该塔处理的特征创建 Keras 顺序模型来进一步定义子类化的塔。
# 特征:pl_name_src self.pl_name_src_text_embedding = tf.keras.Sequential( [ tf.keras.layers.TextVectorization( vocabulary=vocab_dict['pl_name_src'], ngrams=2, name="pl_name_src_textvectorizor" ), tf.keras.layers.Embedding( input_dim=MAX_TOKENS, output_dim=EMBEDDING_DIM, name="pl_name_src_emb_layer", mask_zero=False ), tf.keras.layers.GlobalAveragePooling1D(name="pl_name_src_1d"), ], name="pl_name_src_text_embedding" ) |
由于播放列表的STRUCT 中表示的特征是序列特征(列表),因此我们需要重新整形嵌入层输出并使用 2D 池化(与对非序列特征应用的 1D 池化相反)。
# 特性:artist_genres_pl self.artist_genres_pl_embedding = tf.keras.Sequential( [ tf.keras.layers.TextVectorization( ngrams=2, vocabulary=vocab_dict['artist_genres_pl'], name="artist_genres_pl_textvectorizor" ), tf.keras.layers.Embedding( input_dim=MAX_TOKENS, output_dim=EMBED_DIM, name="artist_genres_pl_emb_layer", mask_zero=False ), tf.keras.layers.Reshape([-1, MAX_PL_LENGTH, EMBED_DIM]), tf.keras.layers.GlobalAveragePooling2D(name="artist_genres_pl_2d"), ], name="artist_genres_pl_emb_model" ) |
一旦两个塔构建完成,我们使用 TFRS 基础模型类(tfrs.models.Model)来简化组合模型的构建。我们在类的 __init__ 中包含每个塔,并定义 compute_loss 方法
class TheTwoTowers(tfrs.models.Model): def __init__(self, layer_sizes, vocab_dict, parsed_candidate_dataset): super().__init__() self.query_tower = Playlist_Tower(layer_sizes, vocab_dict) self.candidate_tower = Candidate_Track_Tower(layer_sizes, vocab_dict) self.task = tfrs.tasks.Retrieval( metrics=tfrs.metrics.FactorizedTopK( candidates=parsed_candidate_dataset.batch(128).map( self.candidate_tower, num_parallel_calls=tf.data.AUTOTUNE ).prefetch(tf.data.AUTOTUNE) ) ) def compute_loss(self, data, training=False): query_embeddings = self.query_tower(data) candidate_embeddings = self.candidate_tower(data) return self.task( query_embeddings, candidate_embeddings, compute_metrics=not training, candidate_ids=data['track_uri_can'], compute_batch_metrics=True ) |
我们可以通过在连接后的嵌入层之后添加稠密层来增加每个塔的深度。由于这将强调学习连续的特征表示层,因此可以提高模型的表达能力。
类似地,我们可以在嵌入层之后添加深度层和交叉层,以更好地对特征交互进行建模。交叉层对显式特征交互进行建模,然后与对隐式特征交互进行建模的深度层相结合。这些参数通常会导致更好的性能,但会显着增加模型的计算复杂度。我们建议评估不同的深度层和交叉层实现(例如,并行与堆叠)。有关更多详细信息,请参阅 TFRS 深度交叉网络 指南。
由于基于分解的模型提供了一种纯粹的协同过滤方法,因此 NDR 架构的先进特征处理允许我们将此扩展到还包含 基于内容的过滤 方面。通过包含描述播放列表和轨道的附加特征,我们为 NDR 模型提供了学习有关 播放列表,轨道 对的语义概念的机会。能够包含标签特征(即,有关候选轨道的特征)也意味着我们训练的候选塔可以计算出在训练期间未观察到的候选轨道的嵌入向量(即,冷启动)。从概念上讲,我们可以将这种新的候选轨道嵌入视为汇集从具有相同或相似特征值的候选轨道中学到的所有基于内容和协同过滤的信息。
有了这种添加多模态特征的灵活性,我们只需要将它们处理以生成具有相同维度的嵌入向量,这样它们就可以连接并馈送到后续的深度层和交叉层。这意味着如果我们将预训练的嵌入用作输入特征,我们将将其传递到连接层(见图 8)。
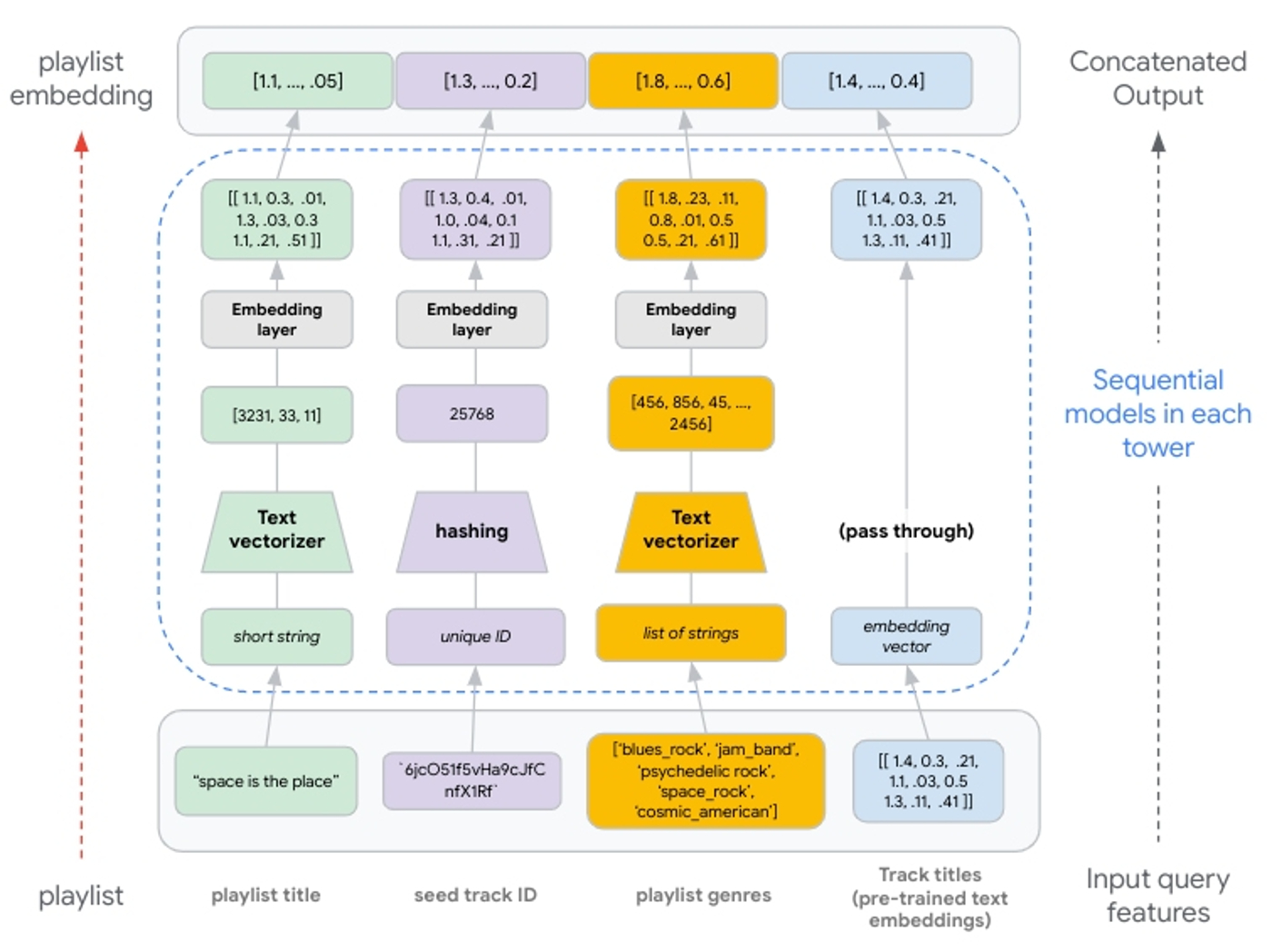 |
| 图 8:从输入到连接输出的特征处理说明。文本特征通过 n 元语法生成。n 元语法的整数索引传递到嵌入层。哈希生成最多 1,000,000 的唯一整数;传递到嵌入层的数值。如果使用预训练的嵌入,则这些嵌入在连接到其他嵌入表示之前无需转换即可通过塔。 |
当需要快速性能时,通常建议使用哈希,并且优于字符串查找,因为它跳过了查找表的需要。为哈希层设置适当的 bin 大小至关重要。当唯一值多于哈希 bin 时,值开始被放置到相同的 bin 中,这会对我们的推荐产生负面影响。这通常被称为哈希冲突,可以在构建模型时通过为唯一值分配足够的 bin 来避免。有关更多详细信息,请参阅 将分类特征转换为嵌入。
文本特征的关键在于理解使用 TextVectorization 层创建额外的 NLP 特征是否有所帮助。如果从文本特征中得出的额外上下文很少,则对模型训练的成本可能不值得。此层需要从源数据集中进行调整,这意味着该层需要扫描训练数据以创建前 N 个 n 元语法(由 max_tokens 设置)的查找字典。
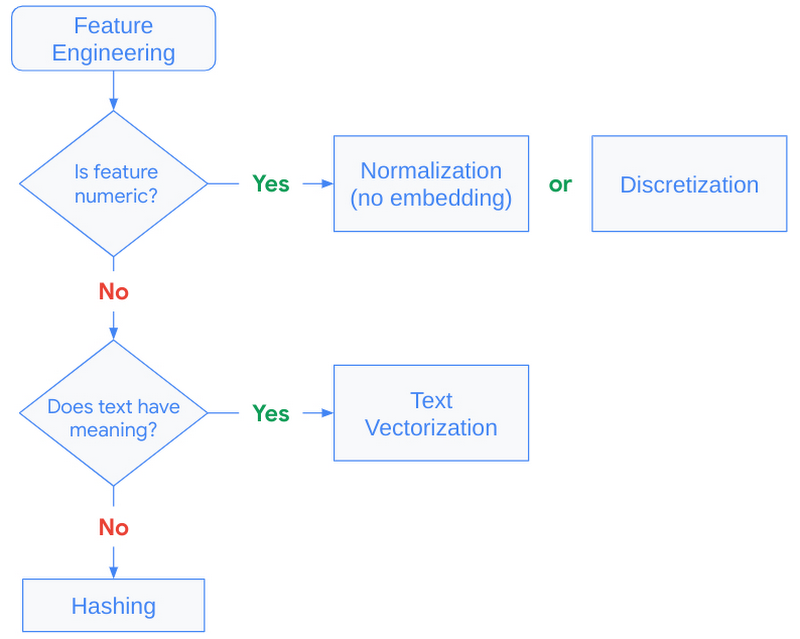 |
| 图 9:指导特征工程策略的决策树。 |
到目前为止,我们已经讨论了如何将查询和候选映射到共享嵌入空间。现在让我们讨论如何最好地利用这个共享嵌入空间来实现高效的服务。
回想一下,在服务时,我们将使用经过训练的查询塔来计算查询(播放列表)的嵌入,并在最近邻搜索中使用此嵌入向量来查找最相似的候选(轨道)嵌入。并且,由于候选数据集可以增长到数百万或数十亿个向量,因此这种最近邻搜索通常成为低延迟推理的计算瓶颈。
许多最先进的技术通过压缩候选向量来解决计算瓶颈,这样就可以在比穷举搜索所需时间少得多的时间内执行 ANN 计算。Google Research 提出的新颖压缩算法修改了这些技术,以同时优化最近邻搜索的准确性。他们提出的技术的详细信息在这里描述,但从根本上说,他们的方法试图压缩候选向量,以使向量之间的原始距离得以保留。与之前的解决方案相比,这会导致向量与其最近邻的相对排名更加准确,即最大限度地减少了模型从训练数据中学习到的向量相似性的扭曲。
Matching Engine 是一种托管解决方案,它利用这些技术来实现高效的向量相似性搜索。它为客户提供高度可扩展的向量数据库和 ANN 服务,同时减轻了开发和维护类似解决方案(如开源的ScaNN 库)的运营开销。它包含几个简化生产部署的功能,包括
- 大规模:支持包含高达 10 亿个嵌入向量的庞大嵌入数据集
- 增量更新:根据向量数量,完整索引重建可能需要数小时。通过增量更新,客户可以进行小的更改而无需构建新索引(有关更多详细信息,请参见更新和重建活动索引)
- 动态重建:当索引超出其原始配置时,Matching Engine 会定期重新组织索引和服务结构,以确保最佳性能
- 自动扩展:底层基础设施会自动扩展,以确保大规模的一致性能
- 过滤和多样性:能够为每个向量包含多个限制和拥挤标签。在查询推断时,使用布尔谓词来过滤和使检索到的候选者多样化(有关更多详细信息,请参见过滤向量匹配)
在创建 ANN 索引时,Matching Engine 使用Tree-AH 策略来构建候选索引的分布式实现。它结合了两种算法
- 用于分层组织嵌入空间的分布式搜索树。此树的每一层都是下一层中节点的聚类,其中最终的叶级是候选嵌入向量的聚类
- 用于快速点积近似算法的非对称哈希 (AH),用于对查询向量和搜索树节点之间的相似性进行评分
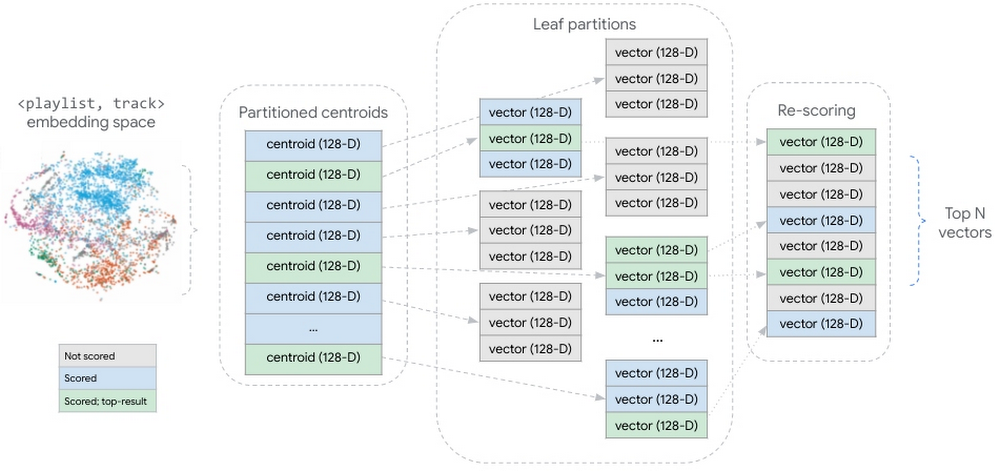 |
| 图 10:分区的候选向量数据集的概念表示。在查询推断期间,对所有分区质心进行评分。在与查询向量最相似的质心中,对所有候选向量进行评分。对评分的候选向量进行聚合和重新评分,返回前 N 个候选向量。 |
这种策略将我们的嵌入向量分片到分区中,其中每个分区都由它包含的向量的质心表示。这些分区质心的聚合形成一个更小的数据集,总结了更大的分布式向量数据集。在推断时,Matching Engine 会对所有分区质心进行评分,然后对质心与查询向量最相似的分区内的向量进行评分。
在本博文中,我们深入了解了使用TensorFlow Recommenders 和Vertex AI Matching Engine 的候选检索工作流程的关键组件。我们更详细地研究了双塔架构的基础概念,探讨了查询和候选实体的语义,并讨论了诸如训练示例的结构之类的内容如何影响候选检索的成功。
在后续文章中,我们将演示如何在 Google Cloud 上使用 Vertex AI 和其他服务来大规模实施这些技术。我们将展示如何利用 BigQuery 和 Dataflow 来构建训练示例并将它们转换为TFRecords 以进行模型训练。我们将概述如何构建 Python 应用程序以使用 Vertex AI Training 服务训练双塔模型。我们将详细介绍操作化已训练的塔的步骤。

2023 年 5 月 2 日 — 作者:Jeremy Wortz,Google Cloud ML 专家 & Jordan Totten,机器学习专家 转载自 Google Cloud AI & Machine Learning在之前的一篇博文中,我们概述了在 Google Cloud 上实现推荐系统的三种方法,包括 (1) 使用Recommendations AI 的完全托管解决方案,(2) 来自BigQuery ML 的矩阵分解,以及 (3) 自定义深度检索…





