发布者 Chansung Park 和 Sayak Paul(ML 和云 GDE)
生成式 AI 模型,例如 稳定扩散1,允许任何人都从自然语言文本提示生成高质量图像,从而在不同行业中实现不同的用例。这些类型的模型使人们不仅可以从图像生成这些图像,还可以使用其他输入(例如分割图、其他图像、深度图等)对其进行条件化。在许多方面,最终的稳定扩散系统(例如 此)通常非常完整。一个人提供一个自由形式的文本提示来启动生成过程,最终生成一个图像(或连续模态中的任何数据)。
在这篇文章中,我们将讨论 TensorFlow Serving(TF Serving)和 Google Kubernetes Engine(GKE)如何通过在线部署来服务这样的系统。稳定扩散只是 TF 和 GKE 可以通过在线部署来服务的众多此类系统中的一个例子。我们首先将稳定扩散分解为主要组件,以及它们如何影响随后的部署考虑因素。然后,我们将深入研究部署特定的部分,例如 TF Serving 部署和 k8s 集群配置。我们的代码在 此存储库 中开源。
让我们深入了解。
稳定扩散包含三个子模型
- CLIP 的文本塔作为文本编码器,
- 扩散模型(UNet)和
- 变分自动编码器的解码器
从输入文本提示生成图像时,首先使用文本编码器将提示嵌入到潜在空间中。然后采样初始噪声,该噪声与文本嵌入一起馈送到扩散模型。然后,使用扩散模型以连续方式对该噪声进行去噪——即所谓的“扩散”过程。此步骤的输出是去噪潜在变量,并将其馈送到解码器以进行最终图像生成。图 1 提供了概述。
(有关稳定扩散的更完整概述,请参阅 这篇文章。)
 |
| 图 1. 稳定扩散架构 |
如上所述,稳定扩散的三个子模型按顺序工作。在单个服务器上运行所有三个模型(构建最终的稳定扩散系统)并整体服务该系统很常见。
但是,由于每个组件都是一个独立的深度学习模型,因此每个组件都可以独立提供服务。这特别有用,因为每个组件都有不同的硬件要求。这也可能带来潜在的资源利用率改进。文本编码器仍然可以在中等 CPU 上运行,而其他两个应该在 GPU 上运行,特别是 UNet 应该使用更大尺寸的 GPU(约 3.4 GB)提供服务。
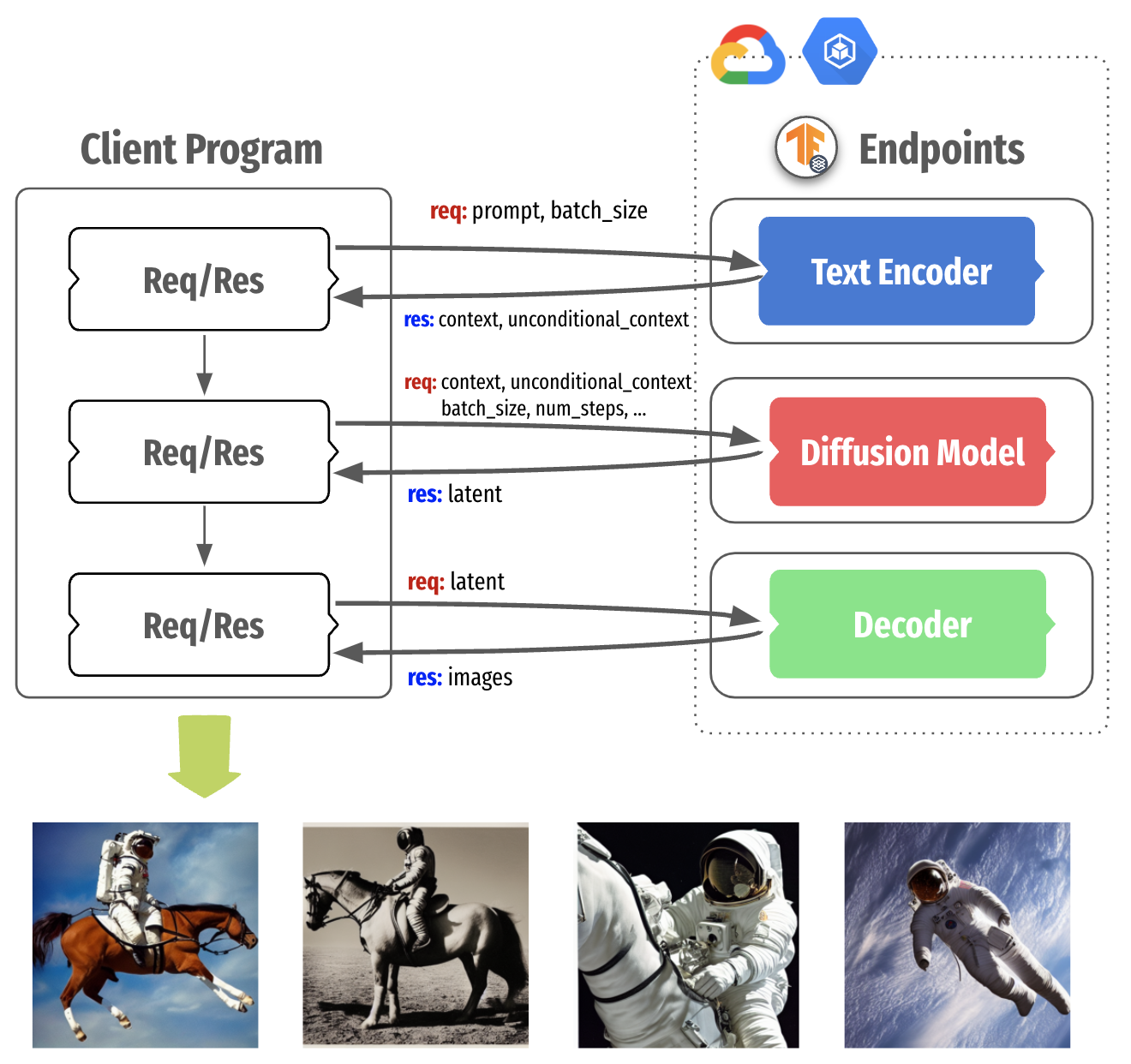 |
| 图 2. 将稳定扩散分解为三个部分 |
图 2 显示了稳定扩散服务架构,该架构将每个组件打包到一个单独的容器中,并使用 TensorFlow Serving,它在 GKE 集群上运行。这种分离在考虑本地计算能力和图 3 所示的稳定扩散微调性质时带来了更多控制。
注意:TensorFlow Serving 是一种灵活的高性能机器学习模型服务系统,专为生产环境而设计,在行业中被广泛采用。使用它的好处包括 GPU 服务支持、动态批处理、模型版本控制、RESTful 和 gRPC API,仅举几例。
在现代个人设备(例如台式机和移动电话)中,它们通常配备中等 CPU,有时还配备 GPU/NPU。在这种情况下,我们可以在云中使用高容量 GPU 有选择地运行 UNet 和/或解码器,同时在用户的设备上本地运行文本编码器。总的来说,这种方法使我们能够灵活地构建稳定扩散系统,以最大限度地提高资源利用率。
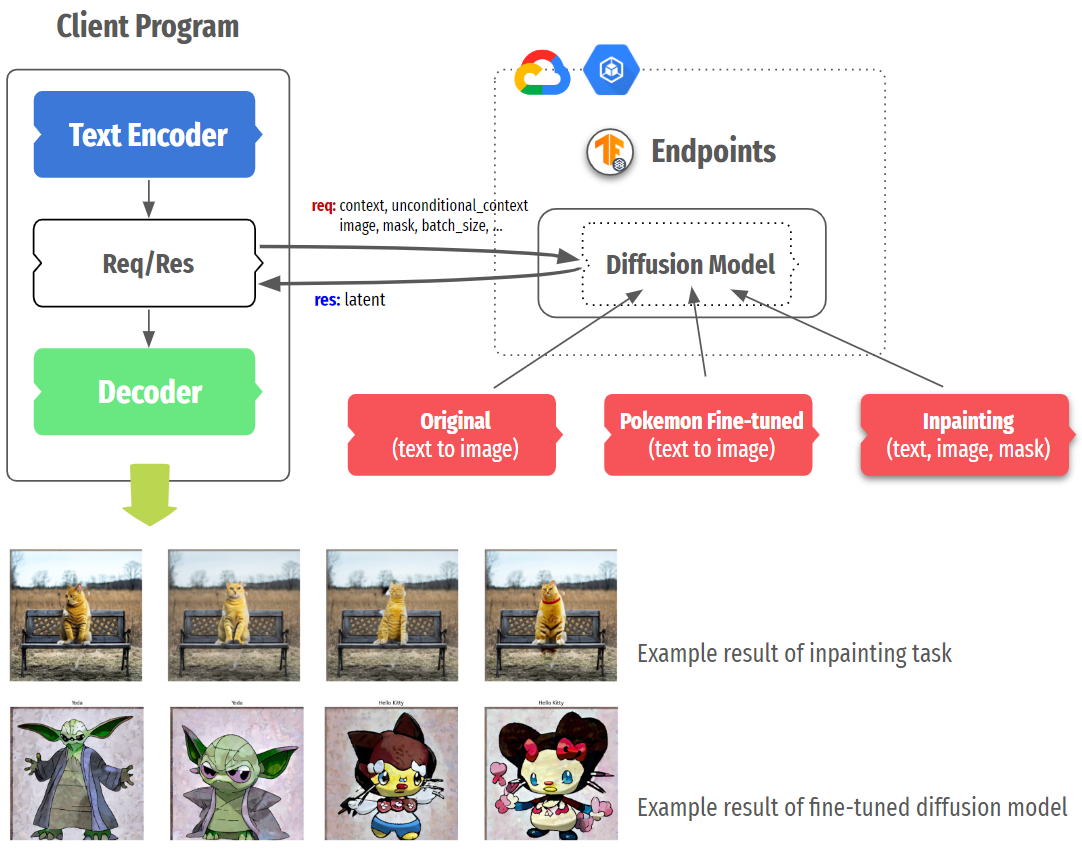 |
| 图 3. 稳定扩散的灵活服务结构 |
另一个需要考虑的情况是微调的稳定扩散。DreamBooth、Textual Inversion 或风格迁移等许多变体表明,仅修改一个或两个组件(通常是文本编码器和 UNet)就可以生成具有新概念或不同风格的图像。在这种情况下,我们可以有选择地在单独的实例上部署更多特定微调模型,或替换现有模型而不影响其他部分。
为了使用 TF Serving 提供 TensorFlow/Keras 模型,应该以 SavedModel 格式 保存该模型。之后,可以通过 TF Serving(一种专为生产环境而设计的高性能机器学习模型服务系统)提供服务。创建 SavedModel 的潜在非平凡部分可以分为三个部分
- 定义基础模型的适当输入签名规范,
- 使用基础模型执行计算,以便所有内容都可以在本机 TensorFlow 中编译,以及
- 在
SavedModel图本身中包含大多数预处理和后处理操作,以减少训练/服务偏差(这是可选的,但强烈推荐)。
为了使 KerasCV 中提供的 稳定扩散类 与 TF Serving 兼容,我们需要首先隔离该类的子网络(如上所述)。回想一下,我们这里有三个子网络:文本编码器、扩散模型和解码器。然后,我们必须将这些网络序列化为 SavedModel。
扩散系统还涉及迭代采样,其中噪声向量逐渐转变为图像。KerasCV 的稳定扩散类 实现 了使用非 TensorFlow 操作的采样过程。因此,我们需要消除这些操作,并确保它以纯 TensorFlow 实现,以便实现端到端兼容性。这是我们在整个项目中最具挑战性的一个方面。
由于文本编码器和解码器的序列化非常简单,因此我们将在本文中跳过它们,而是重点介绍扩散模型的序列化,包括采样过程。您可以在 此处 找到一个端到端的笔记本。
我们首先为要序列化的 SavedModel 定义一个输入签名字典。在这种情况下,输入包括
context,表示使用文本编码器提取的输入文本提示的嵌入unconditional_context,表示所谓的“空提示”的嵌入(参见 无分类器引导)num_steps,表示反向扩散过程的采样步数batch_size,表示要返回的图像数量
from keras_cv.models.stable_diffusion.constants import ALPHAS_CUMPROD_TF import tensorflow as tf IMG_HEIGHT = 512 IMG_WIDTH = 512 MAX_PROMPT_LENGTH = 77 ALPHAS_CUMPROD_TF = tf.constant(ALPHAS_CUMPROD_TF) UNCONDITIONAL_GUIDANCE_SCALE = 7.5 HIDDEN_DIM = 768 SEED = None signature_dict = { "context": tf.TensorSpec(shape=[None, MAX_PROMPT_LENGTH, HIDDEN_DIM], dtype=tf.float32, name="context"), "unconditional_context": tf.TensorSpec( shape=[None, MAX_PROMPT_LENGTH, HIDDEN_DIM], dtype=tf.float32, name="unconditional_context" ), "num_steps": tf.TensorSpec(shape=[], dtype=tf.int32, name="num_steps"), "batch_size": tf.TensorSpec(shape=[], dtype=tf.int32, name="batch_size"), } |
接下来,我们实现涉及预训练扩散模型的迭代逆扩散过程。diffusion_model_exporter() 以该模型作为参数。serving_fn() 是我们用于导出最终 SavedModel 的函数。大部分代码来自原始 KerasCV 实现 这里,只是所有操作都在原生 TensorFlow 中实现。
def diffusion_model_exporter(model: tf.keras.Model): @tf.function def get_timestep_embedding(timestep, batch_size, dim=320, max_period=10000): ... @tf.function(input_signature=[signature_dict]) def serving_fn(inputs): img_height = tf.cast(tf.math.round(IMG_HEIGHT / 128) * 128, tf.int32) img_width = tf.cast(tf.math.round(IMG_WIDTH / 128) * 128, tf.int32) batch_size = inputs["batch_size"] num_steps = inputs["num_steps"] context = inputs["context"] unconditional_context = inputs["unconditional_context"] latent = tf.random.normal((batch_size, img_height // 8, img_width // 8, 4)) timesteps = tf.range(1, 1000, 1000 // num_steps) alphas = tf.map_fn(lambda t: ALPHAS_CUMPROD_TF[t], timesteps, dtype=tf.float32) alphas_prev = tf.concat([[1.0], alphas[:-1]], 0) index = num_steps - 1 latent_prev = None for timestep in timesteps[::-1]: latent_prev = latent t_emb = get_timestep_embedding(timestep, batch_size) unconditional_latent = model( [latent, t_emb, unconditional_context], training=False ) latent = model([latent, t_emb, context], training=False) latent = unconditional_latent + UNCONDITIONAL_GUIDANCE_SCALE * ( latent - unconditional_latent ) a_t, a_prev = alphas[index], alphas_prev[index] pred_x0 = (latent_prev - tf.math.sqrt(1 - a_t) * latent) / tf.math.sqrt(a_t) latent = ( latent * tf.math.sqrt(1.0 - a_prev) + tf.math.sqrt(a_prev) * pred_x0 ) index = index - 1 return {"latent": latent} return serving_fn |
然后,我们可以像这样将扩散模型序列化为 SavedModel
tf.saved_model.save( diffusion_model, path_to_serialize_the_model, signatures={"serving_default": diffusion_model_exporter(diffusion_model)}, ) |
这里,diffusion_model 是预训练的扩散模型,初始化如下
from keras_cv.models.stable_diffusion.diffusion_model import DiffusionModel diffusion_model = DiffusionModel(IMG_HEIGHT, IMG_WIDTH, MAX_PROMPT_LENGTH) |
成功创建 TensorFlow SavedModel 后,使用 TensorFlow Serving 将其部署到 GKE 集群非常简单,步骤如下。
- 编写基于 TensorFlow Serving 基本镜像的 Dockerfile
- 创建具有附加加速器的 GKE 集群
- 将 NVIDIA GPU 驱动程序安装守护程序应用于每个节点以安装驱动程序
- 编写带有 GPU 分配的部署清单
- 编写服务清单以公开部署
- 应用所有清单
将 SavedModel 包裹在 TensorFlow Serving 中的最简单方法是利用预构建的 TensorFlow Serving Docker 镜像。根据您部署到的机器的配置,您应该选择 tensorflow/serving:latest 或 tensorflow/serving:latest-gpu。由于除了特定于 GPU 的配置外,所有步骤都相同,因此我们将通过扩散模型部分的示例来解释此部分。
默认情况下,TensorFlow Serving 在 /models 下识别嵌入模型,因此整个 SavedModel 文件夹树应放置在 /models/{model_name}/{version_num} 中。单个 TensorFlow Serving 实例可以服务多个模型的多个版本,因此这就是为什么我们需要这样的 {model_name}/{version_num} 文件夹结构。可以通过设置一个特殊的环境变量 MODEL_NAME 来公开 SavedModel 作为 API,该变量用于 TensorFlow Serving 来查找要服务的模型。
FROM tensorflow/serving:latest-gpu ... RUN mkdir -p /models/text-encoder/1 RUN cp -r tfs-diffusion-model/* /models/diffusion-model/1/ ENV MODEL_NAME=diffusion-model ... |
下一步是创建 GKE 集群。您可以使用 Google Cloud Console 或 gcloud 容器 CLI 来完成此操作,如下所示。如果您希望每个节点都有加速器可用,则可以使用 --accelerator=type={ACCEL_TYPE}, count={ACCEL_NUM} 选项指定要在每个节点上附加多少个哪种 GPU。
$ gcloud container clusters create {CLUSTER_NAME} \ --machine-type={MACHINE_TYPE} \ # n1-standard-4 --accelerator=type={GPU_TYPE},count={GPU_NUM} \ # nvidia-tesla-v100, 1 ... |
集群创建成功后,如果集群中的节点附加了加速器,则应正确安装相应的驱动程序。这可以通过运行一个特殊的 DaemonSet 来完成,该 DaemonSet 尝试在每个节点上安装驱动程序。如果驱动程序未成功安装,并且您尝试应用需要加速器的 Deployment 清单,则 Pod 的状态将保持为 Pending。
DRIVER_URL = https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml kubectl apply -f $DRIVER_URL |
使用 kubectl get pods -A 命令确保所有 Pod 都已启动并运行。然后,我们就可以应用准备好的 Deployment 清单。以下是以扩散模型为例的 Deployment 清单,您需要考虑的唯一因素是指定 Deployment 的 Pod 应该使用哪些资源。由于扩散模型需要在加速器上运行,因此需要设置 resources:limits:nvidia.com/gpu: {ACCEL_NUM}。
此外,如果您想同时暴露 gRPC 和 RestAPI,则需要为两者设置容器端口。默认情况下,TensorFlow Serving 通过 8500 和 8501 分别暴露这两个端点,因此应指定这两个端口。
apiVersion: apps/v1 kind: Deployment ... spec: containers: - image: {IMAGE_URI} ... args: ["--rest_api_timeout_in_ms=1200000"] ports: - containerPort: 8500 name: grpc - containerPort: 8501 name: restapi resources: limits: nvidia.com/gpu: 1 |
需要注意的是,--rest_api_timeout_in_ms 标志在参数中设置了一个很大的数字。大型模型运行推理需要很长时间。由于该标志默认设置为 5000 毫秒,即 5 秒,有时在推理完成之前就会发生超时。您可以通过实验找出合适的数字,但我们只是将此数字设置为足够大的数字以确保项目顺利演示。
最后一步是将准备好的清单文件应用到预配的 GKE 集群。这可以通过 kubectl apply -f 命令轻松完成。此外,您也可以根据需要应用服务和入口。由于我们只是为了演示目的使用了普通的 LoadBalancer 类型的服务,所以这里没有列出。您可以在附带的 GitHub 仓库 中找到所有 Dockerfile,以及部署和服务清单。
一旦所有 TensorFlow Serving 实例都部署完毕,我们就可以通过调用它们的端点来生成图像。我们将展示如何通过 RestAPI 来实现,但您也可以使用 gRPC 通道来完成相同操作。图像生成过程可以分为以下步骤:
- 为您的选择的提示准备标记。
- 将标记发送到文本编码器端点。
- 将从文本编码器获取的上下文和无条件上下文发送到扩散模型端点。
- 将从扩散模型获取的潜变量发送到解码器端点。
- 绘制生成的图像。
由于将标记器嵌入到文本编码器本身并非易事,我们需要为您的选择的提示准备标记。KerasCV 库在 keras_cv.models.stable_diffusion.clip_tokenizer 模块中提供了 SimpleTokenizer,因此您只需将提示传递给它即可。由于扩散模型被设计为接受 77 个标记,因此标记将用 MAX_PROMPT_LENGTH 填充,直到达到 77 个长度。
注意:由于 KerasCV 带有许多我们标记不需要的模块,因此不建议导入整个库。相反,您可以在您的环境中简单地复制 SimpleTokenizer 的代码。由于不兼容问题,当前标记器无法作为文本编码器 SavedModel 的一部分进行发布。
from keras_cv.models.stable_diffusion.clip_tokenizer import SimpleTokenizer MAX_PROMPT_LENGTH = 77 PADDING_TOKEN = 49407 tokenizer = SimpleTokenizer() prompt = "photograph of an astronaut riding a horse in a green desert" tokens = tokenizer.encode(prompt) tokens = tokens + [PADDING_TOKEN] * (MAX_PROMPT_LENGTH - len(tokens)) |
准备好了标记后,我们可以简单地将它传递给扩散模型的端点。标题和调用所有端点的方式相同,因此在接下来的步骤中我们将省略它。请记住您正确设置了 ADDRESS 和 MODEL_NAME,它们与我们在每个 Dockerfile 中设置的相同。
import requests ADDRESS = ENDPOINT_IP_ADDRESS headers = {"content-type": "application/json"} payload = ENDPOINT_SPECIFIC response = requests.post( f"http://{ADDRESS}:8501/v1/models/{MODEL_NAME}:predict", data=payload, headers=headers ) |
如您所见,每个负载都依赖于上游任务。例如,我们将标记传递给文本编码器的端点,将从文本编码器获取的上下文和 unconditional_context 传递给扩散模型的端点,将从扩散模型获取的潜变量传递给解码器的端点。signature_name 应该与我们在使用签名参数创建 SavedModel 时相同。
import json BATCH_SIZE = 4 payload_to_text_encoder = json.dumps( { "signature_name": "serving_default", "inputs": { "tokens": tokens, "batch_size": BATCH_SIZE } }) # json_response is from the text_encoder's response # json_response = json.loads(response.text) payload_to_diffusion_model = json.dumps( { "signature_name": "serving_default", "inputs": { "batch_size": BATCH_SIZE, "context": json_response['outputs']['context'], "num_steps": num_steps, "unconditional_context": json_response['outputs']['unconditional_context'] } }) # json_response is from the diffusion_model's response # json_response = json.loads(response.text) payload_to_decoder = json.dumps( { "signature_name": "serving_default", "inputs": { "latent": json_response['outputs'], } }) |
解码器端点的最终响应包含一个包含像素值的列表,因此我们需要将其转换为您的选择的环境能够识别为图像的格式。为了演示,我们使用了 tf.convert_to_tensor() 实用函数,它将 Python 列表转换为 TensorFlow 的张量。但是,您也可以使用您最熟悉的方法在不同的语言中绘制图像。
import matplotlib.pyplot as plt def plot_images(images): plt.figure(figsize=(20, 20)) for i in range(len(images)): ax = plt.subplot(1, len(images), i + 1) plt.imshow(images[i]) plt.axis("off") plot_images( tf.convert_to_tensor(json_response["outputs"]).numpy() ) |
 |
| 图 4. 使用三个 TensorFlow Serving 端点生成的图像 |
通过将 `SavedModel` 编译为 XLA 兼容,我们可以获得 17% 到 25% 的加速。需要注意的是,Stable Diffusion 类别的各个子网络是完全 XLA 兼容的。但在我们的例子中,`SavedModel` 还包含了一些重要的原生 TensorFlow 操作,例如反向扩散过程。
对于部署目的,这种加速可能会有很大影响。要了解更多信息,请查看以下存储库:https://github.com/sayakpaul/xla-benchmark-sd。
在这篇博文中,我们探讨了 Stable Diffusion 是什么,它如何被分解成文本编码器、扩散模型和解码器,以及为什么它可能对更好地利用资源有利。此外,我们还具体演示了如何通过创建 `SavedModel`,将它们容器化为 TensorFlow Serving,将它们部署在 GKE 集群上,并运行图像生成,来部署分解后的 Stable Diffusion。我们使用了基础版的 Stable Diffusion,但您可以随意尝试用 修复 或 精调的宝可梦扩散模型 替换唯一的扩散模型。
CLIP: 连接文本和图像,OpenAI,https://openai.com/research/clip。
插图版 Stable Diffusion,Jay Alammar,https://jalammar.github.io/illustrated-stable-diffusion/。
Stable Diffusion,Stability AI,https://stability.ai/stable-diffusion。
我们感谢 ML 开发者计划团队 为支持我们的实验提供了 Google Cloud 积分。我们感谢 Robert Crowe 为我们提供了有益的反馈和指导。
___________
1 Stable Diffusion 不属于也不由 Google 运营。它由 Stability AI 提供。有关更多信息,请访问其网站:https://stability.ai/blog/stable-diffusion-public-release.

2023 年 4 月 28 日 — 作者:Chansung Park 和 Sayak Paul(ML 和 Cloud GDE) 像 Stable Diffusion1 这样的生成式 AI 模型允许任何人从自然语言文本提示生成高质量的图像,从而在不同行业实现不同的用例。这些类型的模型允许人们不仅从图像生成这些图像,还可以用其他输入(例如分割图、其他图像……)来对它们进行条件化。





