https://blog.tensorflowcn.cn/2023/01/using-tensorflow-for-deep-learning-on-video-data.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhKHNOUbpdNnbCJlx09qc6mN3yrB4eNoncZu8UigwPTzh_BFW96PUuCs0vhwOA9DxcyuxtBx2PVYSmVwy6FSlz-7FzFGT3ORyuDsSrzLnhKBCVnOyjh49f1Gf1iKo37F4J1mBQrnqCFf4Wc-doztvHhHdprVn_lhSsU5s024rleybRQGcfDpXUoGBo1/s1600/image1.png
作者:Shilpa Kancharla
视频数据包含丰富的 信息,并且比图像数据具有更复杂和更大的结构。能够使用深度学习以内存效率的方式对视频进行分类可以帮助我们更好地理解数据中的内容。在 tensorflow.org 上,我们发布了一系列有关如何加载、预处理和分类视频数据的教程。以下是这些教程的快速链接
- 加载视频数据
- 使用 3D 卷积神经网络进行视频分类
- 用于流式动作识别的 MoViNet
- 使用 MoViNet 进行视频分类的迁移学习
在这篇博文中,我们认为深入了解一些教程的某些部分会很有趣,并讨论如何将这些部分结合起来构建您自己的模型,这些模型可以使用 TensorFlow 以内存效率的方式处理视频或三维数据(例如 MRI 扫描),例如利用 Python 生成器和调整大小,或对数据进行下采样。
 |
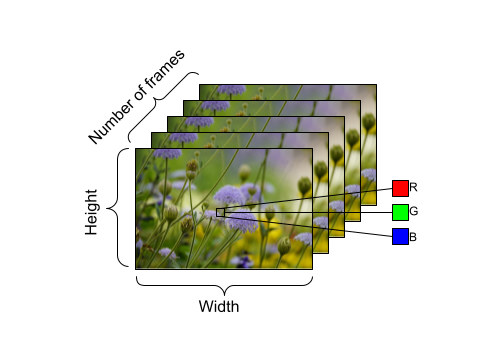
视频数据的形状示例,具有以下维度
帧数(时间) x 高度 x 宽度 x 通道。 |
FrameGenerator 用于加载视频数据
从 加载视频数据 教程中,让我们借此机会谈谈大多数这些教程的主要工作原理: FrameGenerator 类。通过这个类,我们可以生成视频的张量表示和视频的标签或类别。
class FrameGenerator:
def __init__(self, path, n_frames, training = False):
""" Returns a set of frames with their associated label.
Args:
path: Video file paths.
n_frames: Number of frames.
training: Boolean to determine if training dataset is being created.
"""
self.path = path
self.n_frames = n_frames
self.training = training
self.class_names = sorted(set(p.name for p in self.path.iterdir() if p.is_dir()))
self.class_ids_for_name = dict((name, idx) for idx, name in enumerate(self.class_names))
def get_files_and_class_names(self):
video_paths = list(self.path.glob('*/*.avi'))
classes = [p.parent.name for p in video_paths]
return video_paths, classes
def __call__(self):
video_paths, classes = self.get_files_and_class_names()
pairs = list(zip(video_paths, classes))
if self.training:
random.shuffle(pairs)
for path, name in pairs:
video_frames = frames_from_video_file(path, self.n_frames)
label = self.class_ids_for_name[name] # Encode labels
yield video_frames, label |
创建生成器类后,我们使用 from_generator() 函数将数据馈送到我们的深度学习模型。具体来说, from_generator() API 将创建一个数据集,其内容由生成器生成。与将整个数据序列存储在内存中相比,使用 Python 生成器可能更节省内存。考虑创建一个类似于 FrameGenerator 的生成器类,并使用 from_generator() API 将数据加载到您的 TensorFlow 和 Keras 模型中。
output_signature = (tf.TensorSpec(shape = (None, None, None, 3), dtype = tf.float32),
tf.TensorSpec(shape = (), dtype = tf.int16))
train_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['train'], 10, training=True), output_signature = output_signature) |
einops 库用于调整视频数据大小 |
对于第二个有关
使用 3D 卷积神经网络进行视频分类 的教程,让我们讨论一下
einops 库的使用及其如何集成到由 TensorFlow 支持的 Keras 模型中。此库有助于执行灵活的张量运算,不仅可以与 TensorFlow 一起使用,还可以与 JAX 一起使用。具体来说,在本教程中,我们使用它来帮助调整数据在创建的 (2+1)D 卷积神经网络中的大小。在本教程中,我们想对视频数据进行下采样。下采样特别有用,因为它允许我们的模型检查帧的特定部分以检测可能特定于该视频中某个特征的模式。通过下采样,可以丢弃非必要信息。它将允许降维,从而实现更快的处理。
我们使用 parse_shape() 和 rearrange() 函数来自 einops 库。parse_shape() 函数在此处用于将轴的名称映射到其相应的长度。它将返回包含此信息的字典,称为 old_shape。接下来,我们使用 rearrange() 函数,它允许您重新排列多维张量的轴。传入张量,以及您尝试重新排列的轴的名称。
符号 b t h w c -> (b t) h w c 表示我们想将批次大小(用 b 表示)和时间(用 t 表示)维度压缩在一起,将这些数据传递到 Keras Resizing 层对象中。当我们实例化 ResizeVideo 类时,我们将传入我们想要调整帧大小的宽度和高度值。完成调整大小后,我们再次使用 rearrange() 函数(使用符号 (b t) h w c -> b t h w c)来解压缩批次大小和时间维度。
class ResizeVideo(keras.layers.Layer):
def __init__(self, height, width):
super().__init__()
self.height = height
self.width = width
self.resizing_layer = layers.Resizing(self.height, self.width)
def call(self, video):
"""
Use the einops library to resize the tensor.
Args:
video: Tensor representation of the video, in the form of a set of frames.
Return:
A downsampled size of the video according to the new height and width it should be resized to.
"""
# b stands for batch size, t stands for time, h stands for height,
# w stands for width, and c stands for the number of channels.
old_shape = einops.parse_shape(video, 'b t h w c')
images = einops.rearrange(video, 'b t h w c -> (b t) h w c')
images = self.resizing_layer(images)
videos = einops.rearrange(
images, '(b t) h w c -> b t h w c',
t = old_shape['t'])
return videos |
接下来是什么?
这些只是您利用 TensorFlow 以内存效率的方式处理视频数据的一些方法,但这些技术并不仅限于视频数据。医疗数据,例如 MRI 扫描或 3D 图像数据,也需要有效的数据加载和潜在的形状调整。当您使用有限的计算资源时,这些技术可能会有用。我们希望您发现这些教程对您有所帮助,感谢您的阅读!






