作者:Chansung Park,Sayak Paul(ML 和 Cloud GDE)
TensorFlow Extended (TFX) 是一个灵活的框架,允许机器学习(ML)从业人员以更高的可靠性和弹性更快地迭代生产级 ML 工作流。TFX 的强大之处在于它能够灵活地在不同的兼容编排器(如 Kubeflow、Apache Airflow、Vertex AI Pipelines 等)上运行 ML 管道,无论是在本地还是在云端。
在这篇博文中,我们将讨论使用 TFX 和各种 Google Cloud 服务(如 Dataflow、Vertex Pipelines、Vertex Training 和 Vertex Endpoint)构建用于 语义分割 任务的端到端 ML 管道的重要细节。该管道还使用一个与 Hugging Face 🤗 Hub 集成的自定义 TFX 组件 - HFPusher。最后,您将看到我们如何利用 GitHub Actions 将 CI/CD 整合到其中。
尽管我们不会详细介绍管道的全部内容,但您仍然可以在 此 GitHub 存储库 中找到基础项目的代码。
该项目的系统架构分为三个主要部分。第一部分是关于核心 TFX 管道,它处理从数据摄取到模型部署的所有步骤。第二部分涉及管道与外部 Hugging Face 🤗 Hub 服务之间的集成。最后一个是关于使用 GitHub Actions 自动化和实施 CI/CD。
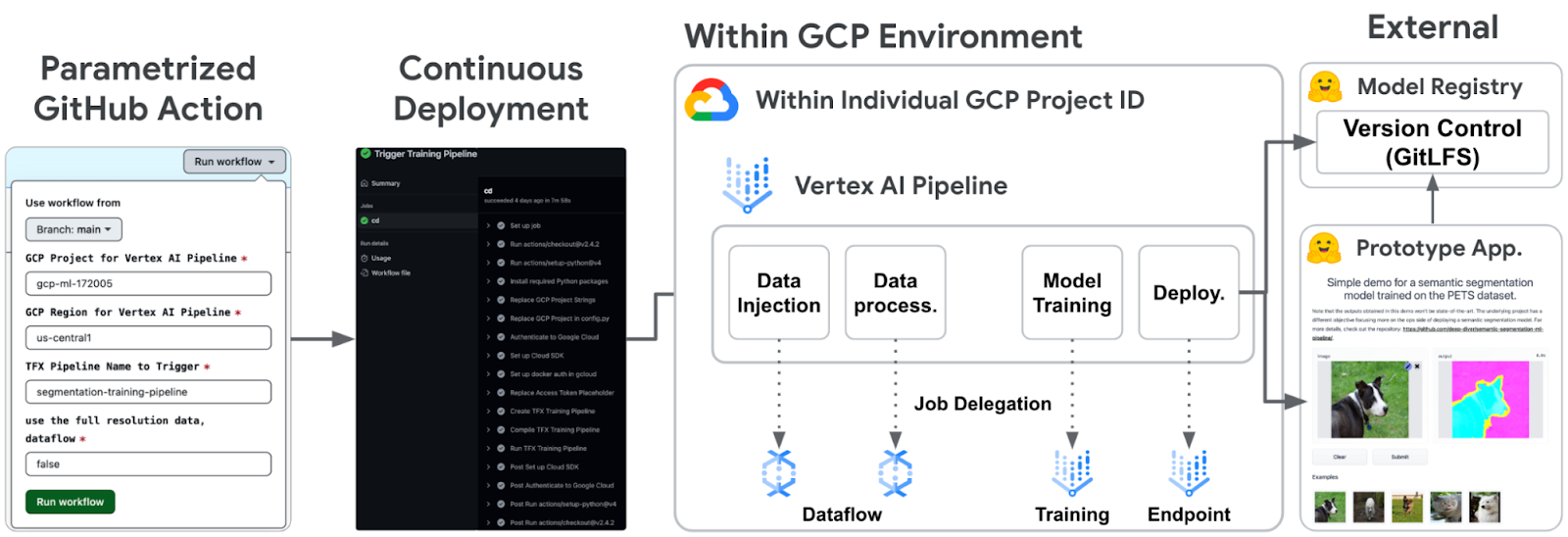 |
图 1. 整体系统架构 (原始) |
在单独的分支中提出新功能或代码重构时,通常会打开拉取请求。在 ML 项目中,这些更改通常会影响模型和/或数据。除了对提议的更改运行基本验证(代码质量、测试等)之外,我们还应确保这些更改产生的模型足够好,能够在合并之前替换当前部署的模型(如果更改与建模有关)。在这个项目中,我们开发了一个 GitHub Action,它在合并分支上以可配置参数手动触发。这样,项目利益相关者可以验证性能相关的更改,并将更改可靠地交付到生产环境。在现实中,这里可能会有更多关键的度量,但我们希望这个 GitHub Action 能成为一个良好的起点。
在任何 MLOps 项目的核心,都有一个 ML 管道。我们构建了一个简单而完整的 ML 管道,它支持在 TFX 中进行自动数据摄取、数据预处理、模型训练、模型评估和模型部署。TFX 管道可以在本地环境中运行,但我们也将其在 Vertex AI 平台上运行,以复制现实世界的生产级环境。
最后,来自 ML 管道的经过训练和合格的模型被部署到 Vertex AI Endpoint。经过“验证”的模型也与一个交互式演示一起被推送到 Hugging Face Hub,通过一个自定义的 HFPusher TFX 组件。Hugging Face Hub 是一个非常受欢迎的地方,用于存储模型并免费发布一个完全可用的 ML 驱动的交互式应用程序。在进行全面生产部署之前,使用最新模型展示应用程序并对其进行审核以确认其按预期工作非常有用。
下面,我们将更详细地讨论这些组件中的每一个,讨论我们的设计考虑因素和非平凡的技术方面。
ML 管道完全用 TFX 编写,从数据摄取到模型部署。具体来说,我们使用了标准的 TFX 组件,例如 ExampleGen、ImportSchemaGen、Transform、Trainer、Evaluator 和 Pusher,以及自定义的 HFPusher 组件。让我们简要了解一下每个组件在我们项目中的作用。
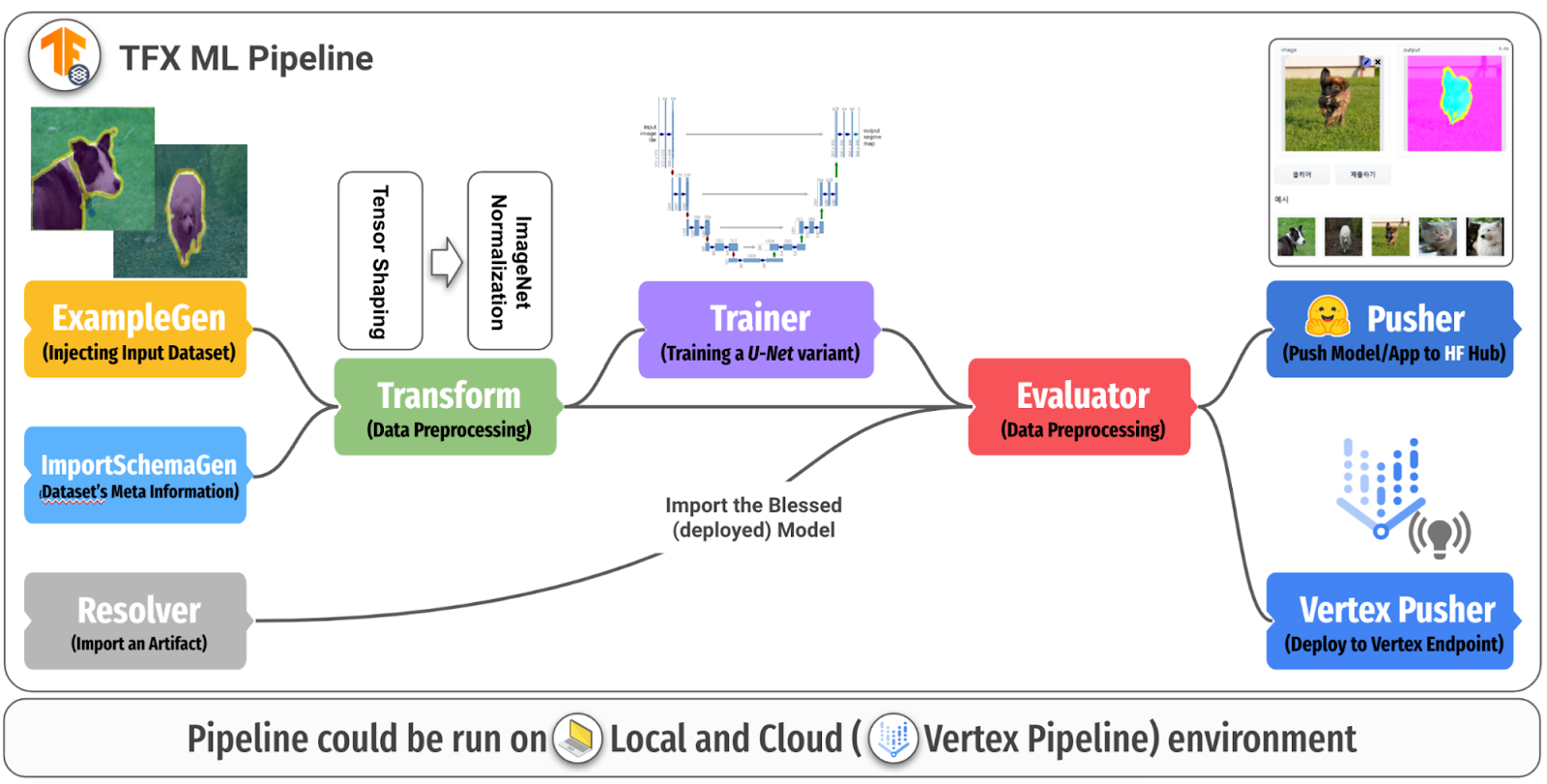 |
图 2. ML 管道概述 (原始) |
在这个项目中,我们已经使用 这些脚本 以 TFRecord 格式准备了 Pets 数据集,并将它们存储在 Google Cloud Storage (GCS) 中。 ExampleGen 从 GCS 中获取数据文件,根据 glob 模式将它们拆分为训练和评估数据集,并将它们存储为 GCS 中的 TFRecords。请注意,ExampleGen 可以接受不同的数据类型,例如 CSV、TFRecord 或 Parquet,然后它以 TFRecord 的统一格式生成数据集。它使我们能够在整个 TFX 管道中统一处理数据。请注意,由于 Pets 数据集可从 TF Datasets 获取,因此您也可以为此任务使用自定义的 TFDS ExampleGen。
ExampleGen 可以开箱即用地与 Dataflow 集成。要使用 Dataflow,您需要做的就是使用 with_beam_pipeline_args 方法,并提供 适当的参数,例如机器类型、磁盘大小、工作线程数量等等。就上下文而言,Dataflow 是由 Google Cloud 提供的托管服务,允许我们以完全分布式的方式高效地运行 Apache Beam 管道。
ImportSchemaGen 导入之前由 SchemaGen 自动推断的协议缓冲区文本格式文件。它也可以手动调整以定义来自 ExampleGen 的输出数据的结构。
在我们的案例中,准备好的 Pets 数据集有两个特征 - 图像和分割图(标签),每个特征的大小为 128x128。因此,我们可以定义如下所示的架构。
另请注意,在 float_domain 部分,我们可以设置值限制。在这个项目中,输入数据是标准的 RGB 图像,因此每个像素值应该在 0 到 255 之间。另一方面,标签的像素值应该是 0、1 或 2,分别表示图像中物体的外部、内部和边界。
借助 ImportSchemaGen,数据已经在 转换 中被正确地塑造并验证。如果没有 ImportSchemaGen,我们将不得不编写代码来解析 TFRecords 并手动在 转换 中塑造每个特征。因此,由于本项目中的模型是基于 MobileNetV2 构建的,因此以下一行代码足以进行数据预处理。
由于数据预处理是 CPU 和内存密集型任务,Transform 也能与 Dataflow 集成。就像在 ExampleGen 中一样,可以通过调用 with_beam_pipeline_args 方法将任务无缝委托给 Dataflow。
(Vertex) Trainer 仅训练模型。我们使用基于 MobileNetV2 的 UNet 架构,该架构来自 TensorFlow 官方教程。由于模型架构并非新鲜事物,让我们看看它是如何模块化的以及一些关键代码片段。
您将建模代码放在一个单独的文件中,该文件作为参数提供给 Trainer。在本例中,该文件名为 train.py。当运行 Trainer 组件时,它会查找名为 run_fn 的起点函数,该函数在 train.py 中定义。 run_fn() 函数基本上从 Transform 的输出中提取训练和评估数据集,训练 UNet 模型(在 unet.py 中定义),然后使用适当的签名保存训练后的模型。训练过程简单地遵循标准 Keras 方式 - model.compile(),model.fit()。
Trainer 组件可以与 Vertex AI Training 开箱即用地集成,这是一个托管服务,用于在分布式系统中训练模型。通过在 配置 Trainer 的 custom_config 参数中指定您希望如何配置训练服务器集群,训练作业将由 Vertex AI Training 自动处理。
还要注意模型在 TensorFlow 中导出的签名。考虑以下保存训练模型(tf.keras.Model 实例)到 SavedModel 资源的代码片段。
签名是定义如何处理给定输入数据的函数。例如,我们定义了三个不同的签名。当 serving_default 用于服务时,另外两个用于模型评估时。
请注意,transform_features 和 from_examples 签名在 Evaluator 组件中内部使用。在下一节中,我们将解释它们之间的联系。
训练好的模型的性能应该通过一些指标来评估。**评估器** 让我们可以定义这些指标,不仅可以评估训练好的模型本身,还可以将训练好的模型与 **解析器** 获取的最新最佳模型进行比较。换句话说,只有当训练好的模型的性能超过基线阈值并且比之前部署的模型更好时,它才会被部署。这个项目的完整配置可以在 这里 找到。
我们使用 transform_features 和 from_examples 这两个签名来进行相同的数据预处理,是因为它们在不同的情况下使用。 评估器 对现有模型运行 evaluate() 方法,而对当前训练的模型,它会运行在 signature_name 中指定的函数(签名)。因此,我们需要一个可以对给定样本进行转换,并同时运行 evaluate() 方法的函数。
当评估好的模型准备部署时,**(Vertex)** 推送器 将模型推送到 Vertex AI 的 模型注册表。它还可以选择性地创建一个 端点 并将模型部署到端点。您可以为 推送器 指定许多不同的部署特定 配置:机器类型,GPU 类型,GPU 数量,流量分配等等。
Hugging Face Hub 为机器学习从业者提供了一个强大的方式来存储和分享 模型,数据集 和 机器学习应用程序。由于它支持对模型工件的无缝存储并提供自动版本控制,我们开发了一个名为 HFPusher 的自定义 TFX 组件,它:
您可以在 Trainer 组件之后在任何地方使用这个组件,但建议您在 TFX 管道的末尾使用它。 HFPusher 组件只需要少量参数,包括两个 TFX 工件和四个 Hugging Face 特定配置:
Hugging Face Hub 主要基于 Git 和 Git-LFS。Hugging Face 团队提供了一个易于使用的 huggingface_hub API 工具包来与它交互。这就是它如何为版本控制、大型文件存储和交互提供无缝支持。
在图 3 和图 4 中,我们展示了模型代码库和应用程序代码库(从 TFX 管道自动创建)在 Hugging Face Hub 上的样子。
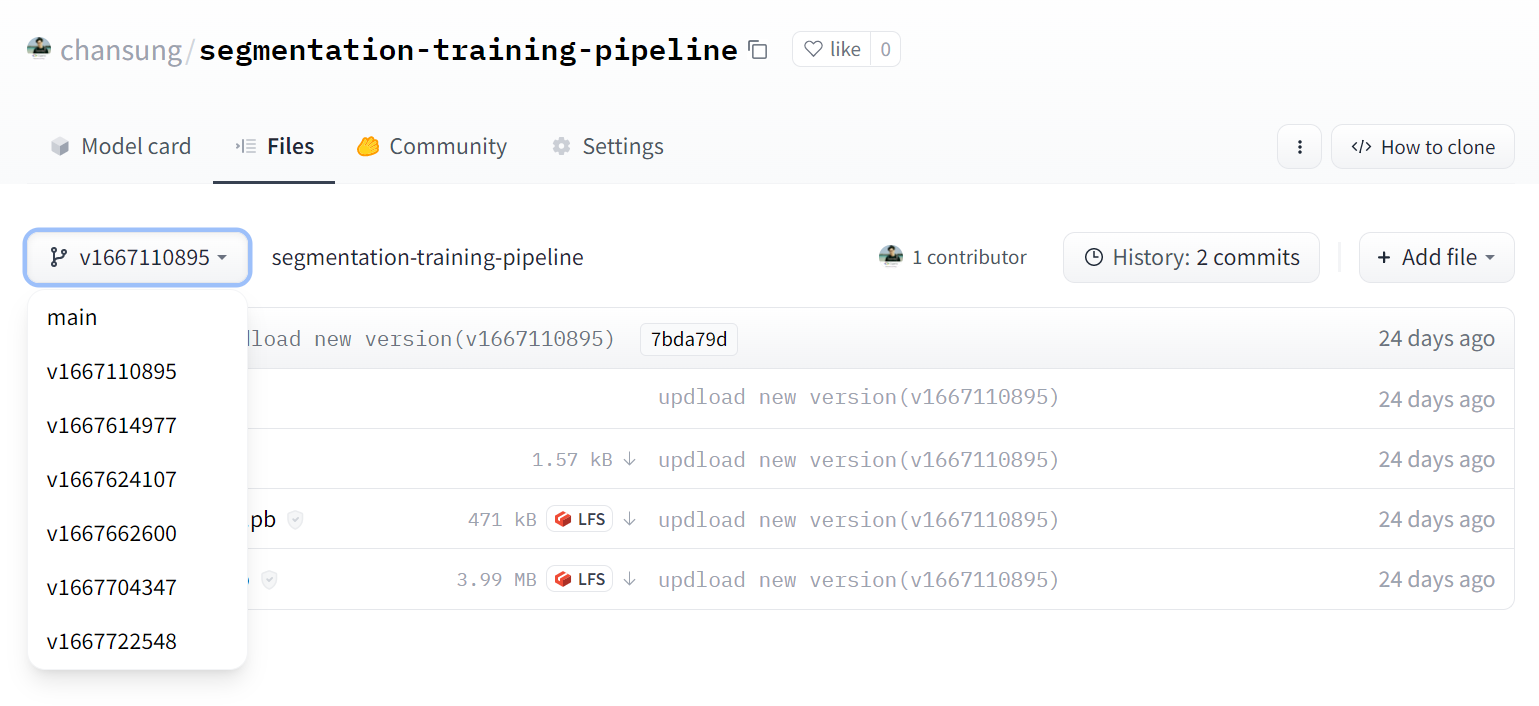 |
| 图 3. Hugging Face 模型中心中的模型版本控制 (原始) |
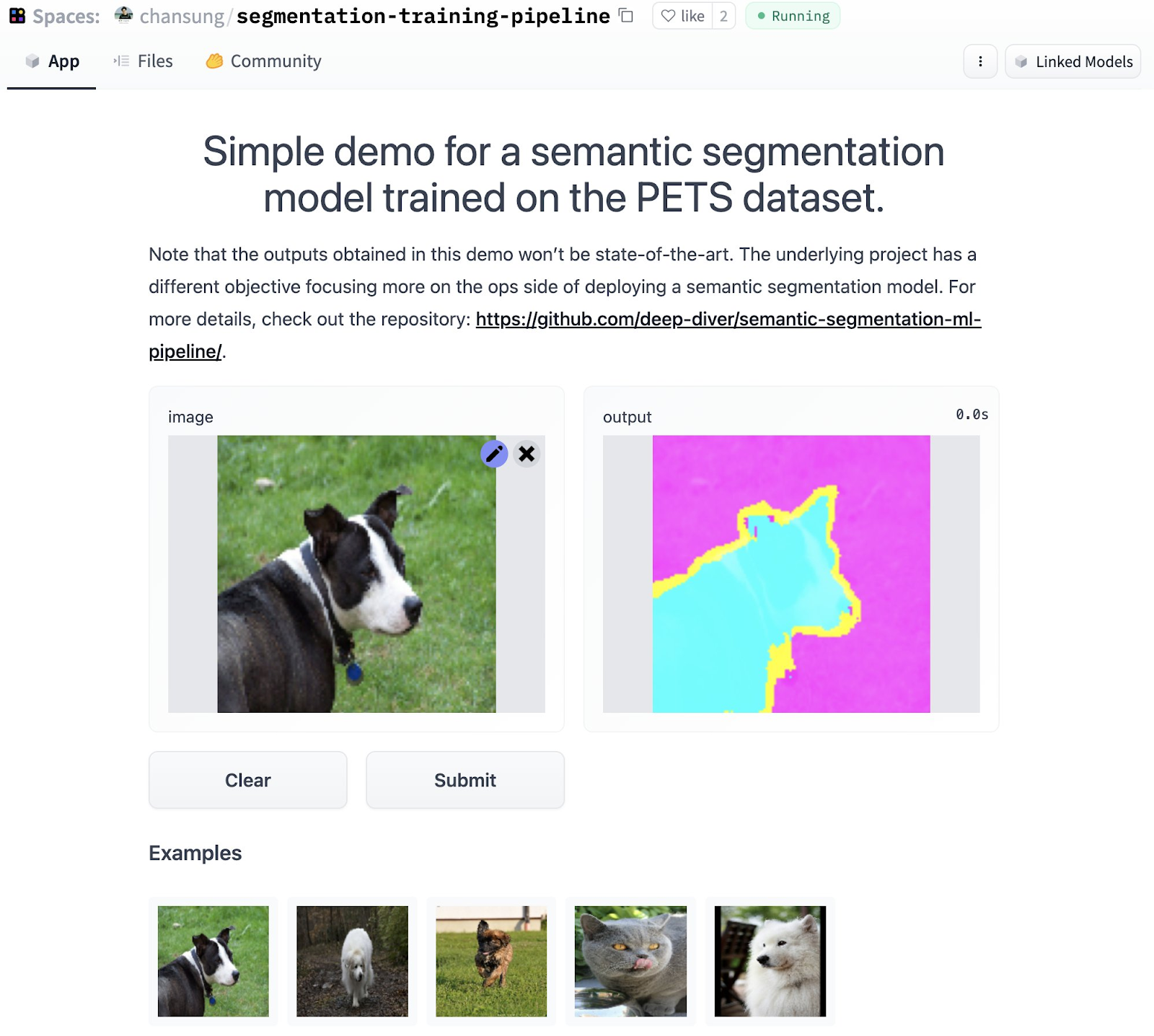 |
| 图 4. Hugging Face Space 中心中自动发布的应用程序 (原始) |
HFPusher 已贡献到官方 TFX-Addons tfx-addons 包。 HFPusher 将在 0.4.0 及更高版本中提供 tfx-addons 包中。
在 DevOps 世界中,我们通常会对引入的更改运行许多测试,以确保它们足够有效,可以投入生产。如果测试通过,则更改会被合并,并自动发布新的部署。
对于机器学习代码库,更改通常与数据或模型在广义上的变化有关。验证这些更改在很大程度上取决于应用程序,但仍然有一些共同点:
在这个项目中,我们关注第一个要点。我们设计了一个 GitHub Action 工作流,可以:
1. **Google Cloud 身份验证和设置** 通过 google-github-actions/auth 和 google-github-actions/setup-gcloud GitHub Actions 完成,前提是提供凭据(JSON)。为了使用适当的凭据访问指定的 Google Cloud 项目 ID,工作流会从 GitHub Action 秘密 中查找凭据。每个凭据都映射到与 Google Cloud 项目 ID 相同的名称。
2. 一些**敏感信息** 使用 envsubst 命令进行替换。在这个项目中,需要向 HFPusher 组件提供一个 Hugging Face 🤗 访问令牌,以便在 Hugging Face 🤗 Hub 中创建和更新任何代码库。访问令牌存储在 GitHub Action 秘密中。
3. 一个环境变量 enable_dataflow 根据指定的参数设置为 "true" 或 "false"。通过查看环境变量,**TFX 管道有条件地定义** Dataflow 的专用参数,并通过 with_beam_pipeline_args 方法将这些参数传递给 ExampleGen 和 Transform 组件。
4. 工作流程的最后部分是使用以下 TFX CLI 在 Vertex AI 上 **编译和运行 TFX 管道**。 tfx pipeline create CLI 创建管道并将其注册到本地系统。 此外,它能够根据管道中的自定义 Dockerfile 构建和推送 Docker 镜像到 Google Container Registry(GCR)。 然后 tfx run create CLI 使用指定的 Google Cloud 项目 ID 和区域在 Vertex AI 上运行管道。
在这种情况下,我们需要验证每个 PR,看建议的修改在构建和运行时是否正常工作。 此外,有时每个协作者都希望使用自己的 Google Cloud 帐户运行 ML 管道。 此外,如果我们可以有条件地将 ML 管道中的一些繁重工作委托给更专用的 Google Cloud 服务,那就更好了。
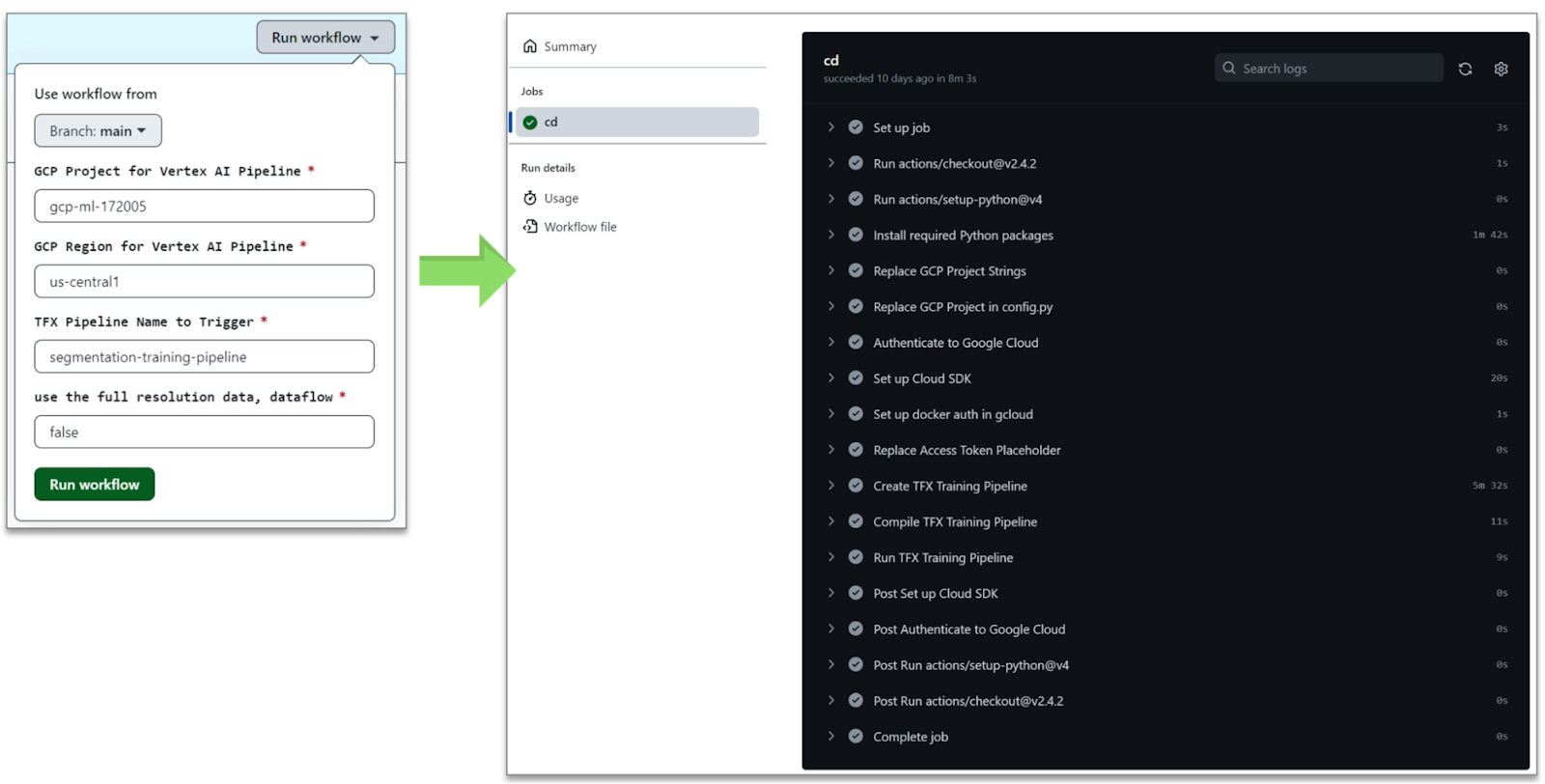 |
| 图 5. 用于 ML 管道 CI/CD 的 GitHub Action (原始) |
您可能已经从图 5 中注意到,GitHub Action 根据五个不同的参数运行工作流程 - 分支、Google Cloud 项目 ID、云区域、TFX 管道名称以及启用 Dataflow 集成。
在这篇文章中,我们讨论了如何构建用于语义分割任务的端到端 ML 管道。 我们利用 TensorFlow、TFX 和 Google Cloud 服务(如 Dataflow 和 Vertex AI、GitHub Actions 以及 Hugging Face 🤗 Hub)开发了一个生产级的 ML 管道,该管道具有外部服务以及半自动的 CI/CD 管道。 我们希望您发现此设置有用且可靠,并将其用于您自己的 ML 管道项目。
作为未来的工作,我们将通过扩展此项目来演示常见的 MLOps 场景。 首先,我们将向数据添加更多复杂性以模拟模型性能下降。 其次,我们将评估当前部署的模型,以查看模型性能下降是否真的发生了。 最后,我们将验证在将当前模型架构替换为 DeepLabV3+ 或 SegFormer 等更好的模型后,模型性能是否恢复。
我们感谢ML 开发者计划团队为我们的实验提供了 Google Cloud 积分。 我们感谢Robert Crowe为我们提供了有益的反馈和指导。 我们还感谢Merve Noyan参与将模型卡片实用程序集成到HFPusher组件中。

2023 年 1 月 18 日 — 由 Chansung Park、Sayak Paul(ML 和 Cloud GDE)发布 TensorFlow Extended (TFX) 是一个灵活的框架,允许机器学习 (ML) 从业者以可靠性和弹性更快的速度迭代生产级 ML 工作流程。 TFX 的强大功能在于它能够灵活地跨不同的兼容编排器运行 ML 管道,例如 Kubeflow、Apache Airflow、Vertex AI Pipelines 等,以及……






{kind=link}