作者:Hannes Hapke 和 Robert Crowe
构建基于机器学习的服务和产品的初创公司需要用于训练和服务其模型的生产级基础设施。对于人手不足的小型团队来说,这尤其具有挑战性,因为他们需要快速创新和发展。TFX(TensorFlow Extended)提供了一系列选择来缓解这些挑战。在本博文中,您将了解总部位于旧金山的金融科技初创公司 Digits 如何从尽早应用 TFX 中受益,TFX 如何帮助 Digits 发展,以及其他初创公司如何从 TFX 中受益。
TFX 是一组库,可简化生产机器学习模型的开发和部署,包括实施自动训练管道。您可能已经知道 Alphabet(包括 Google 和 Waze)、Spotify 或 Twitter 等主要公司成功地利用 TFX 来管理其机器学习管道。但 TFX 对像 Digits 这样的中期初创公司也有巨大的益处。
在我们深入研究如何在 Digits 使用 TFX 之前,让我们介绍一个每个初创公司都将面临的概念性软件设计问题:选择战术编程和战略编程(由 John Ousterhout 在“软件设计哲学”中介绍)。在他的分析中,Ousterhout 表明,战略编程是长期成功的更可持续的方法:即使需要更多时间才能发布初始版本,战略编程也有助于使不断增长的代码库的复杂性更容易管理。
 |
| 来源:“软件设计哲学”,John Ousterhout,2018 |
在 Digits,我们发现同样的概念也适用于机器学习。虽然我们可以在最小的基于 Jupyter notebook 的设置中训练机器学习模型,但随着复杂性的增加,这个系统将变得越来越难于管理。在这种情况下,随着公司的发展,快速训练的机器学习模型的任何初始收益都会逐渐减少。因此,我们从一开始就在我们的 ML 工程设置中投入了大量资金。
Ousterhout 发现战略编程需要更多的前期时间,但开发人员将受益于更低的系统复杂性。例如,我们花了大约 2-3 个月的时间来设置所有 ML 工具和工作流,我们认识到这是一项重大投资。
虽然这可能不适合仍在努力建立产品市场匹配的初创公司,但我们认为这种 ML 策略是拥有不断增长的客户群的初创公司的正确路径。此外,我们的经验是,将战略编程应用于机器学习问题将在长期内提高开发人员的工作满意度并提高数据团队的留存率(更少的匆忙的热修复、系统的模型重新训练等)。
我们使用 TFX 发展业务,我们已经确定了三个关键优势,这些优势使我们能够以对我们作为初创公司取得成功至关重要的方式优化我们的 ML 模型训练和部署。
在 Digits,我们区分机器学习实验和生产机器学习。ML 实验的目标是开发概念验证模型。我们的工程师可以自由地使用任何框架和工具进行 ML 实验,只要满足我们的安全要求。
当我们将模型投入生产,客户依赖一致的预测时,我们将这些实验转换为生产 ML 模型。每次创建生产 ML 模型时,我们都会遵循一致的项目结构,并使用相同的步骤进行数据和模型分析以及特征工程。TFX 在标准化这些方面至关重要。
由于每个生产模型都遵循相同的标准,因此我们可以尽早检测项目之间潜在的协同作用。这种方法使我们能够在最早的开发阶段共享项目之间的代码。标准化提高了代码可重用性,新项目具有更快的启动时间。
使用 TFX 标准化工作流的另一个好处是,我们现在可以将我们的软件工程和 DevOps 原则应用于 ML 项目:非定期运行的管道可以由我们的持续集成系统触发。然后,TFX 管道将新生产的模型注册到我们的模型注册表中。基于此,持续集成系统还可以更新我们的 ML 服务端点并自动部署我们的 ML 模型。这样,对我们 ML 系统的所有更改都将在我们的 Git 存储库中进行跟踪。
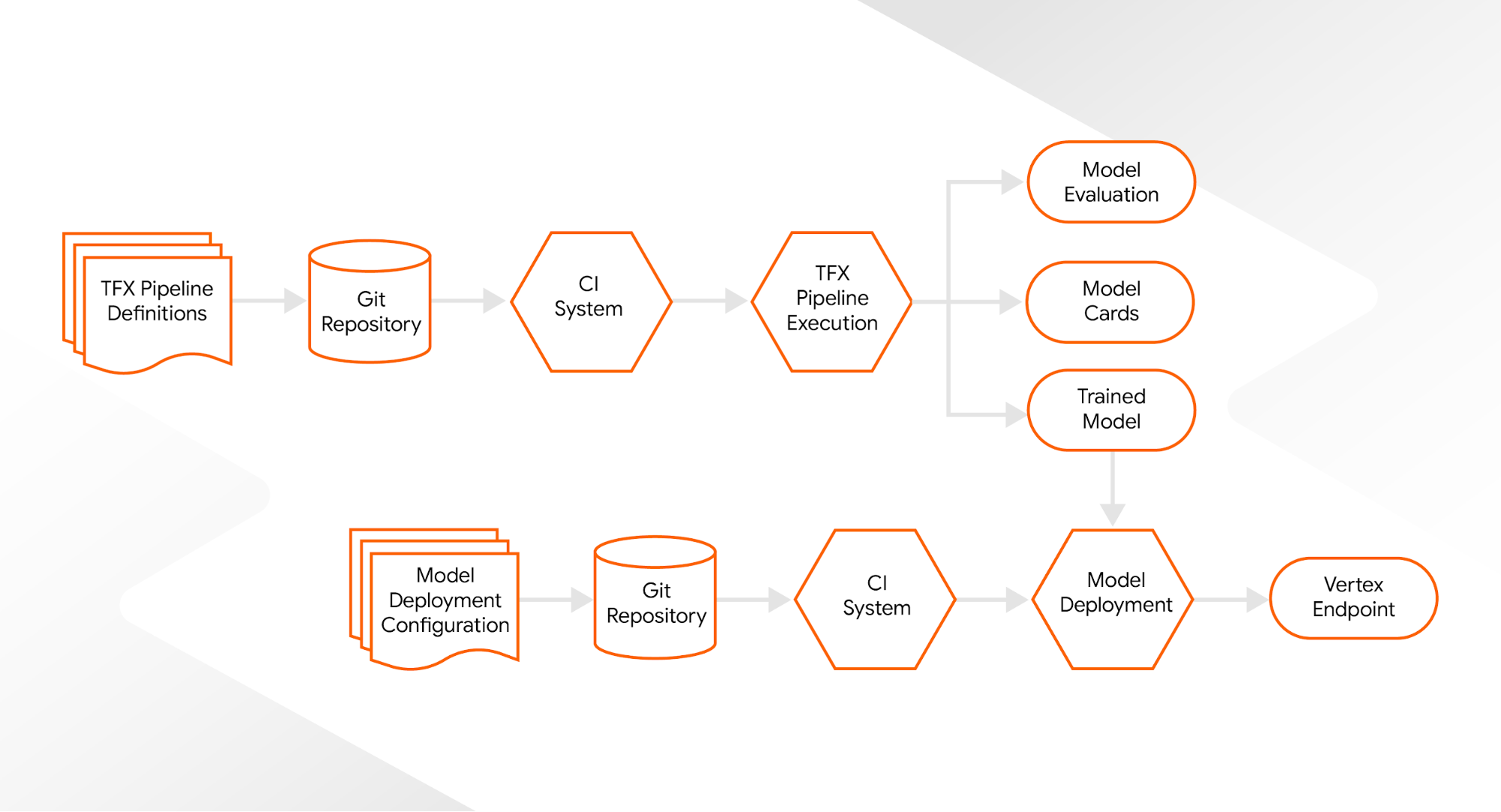 |
| 包括 CI 在内的系统组件 |
与 Keras 的预处理层相比,TFX 通过 Apache Beam 任务支持特征工程、模型分析和数据验证。这样,我们只需要实现一次特征工程 - 使用 TFX,我们可以在我们的数据集增长并需要更多处理能力时简单地替换 Apache Beam 配置。
初创公司可以从基于 Apache Beam 的 DirectRunner 的 TFX 默认设置开始。DirectRunner 模式不允许任何并行执行管道任务,但无需任何设置时间即可使用。随着初创公司的发展,工程团队可以将底层 Apache Beam Runner 替换为更强大的系统,如 Google Cloud 的 Dataflow、Apache Spark 或 Apache Flink,而只需最少的代码更改 - 通常只有一行。虽然 Dataflow 仅适用于 Google Cloud 客户,但 Apache Spark 和 Flink 是开源的,所有主要云提供商都提供托管服务。
我们在 Digits 成功地采用了这种策略:我们从 Apache Beam 的 DirectRunner 开始我们的初始管道,这种设置帮助我们了解 TFX 如何改进我们的 ML 工作流。随着公司的发展,要处理的数据量也随之增加。为了处理不断增加的数据量,TFX 允许我们无缝切换到不同的 Beam 运行器。通过分两个阶段构建我们的管道,我们不必立即实施 TFX 和更强大、更复杂的编排依赖项,从而为我们最初的小团队节省了大量压力。
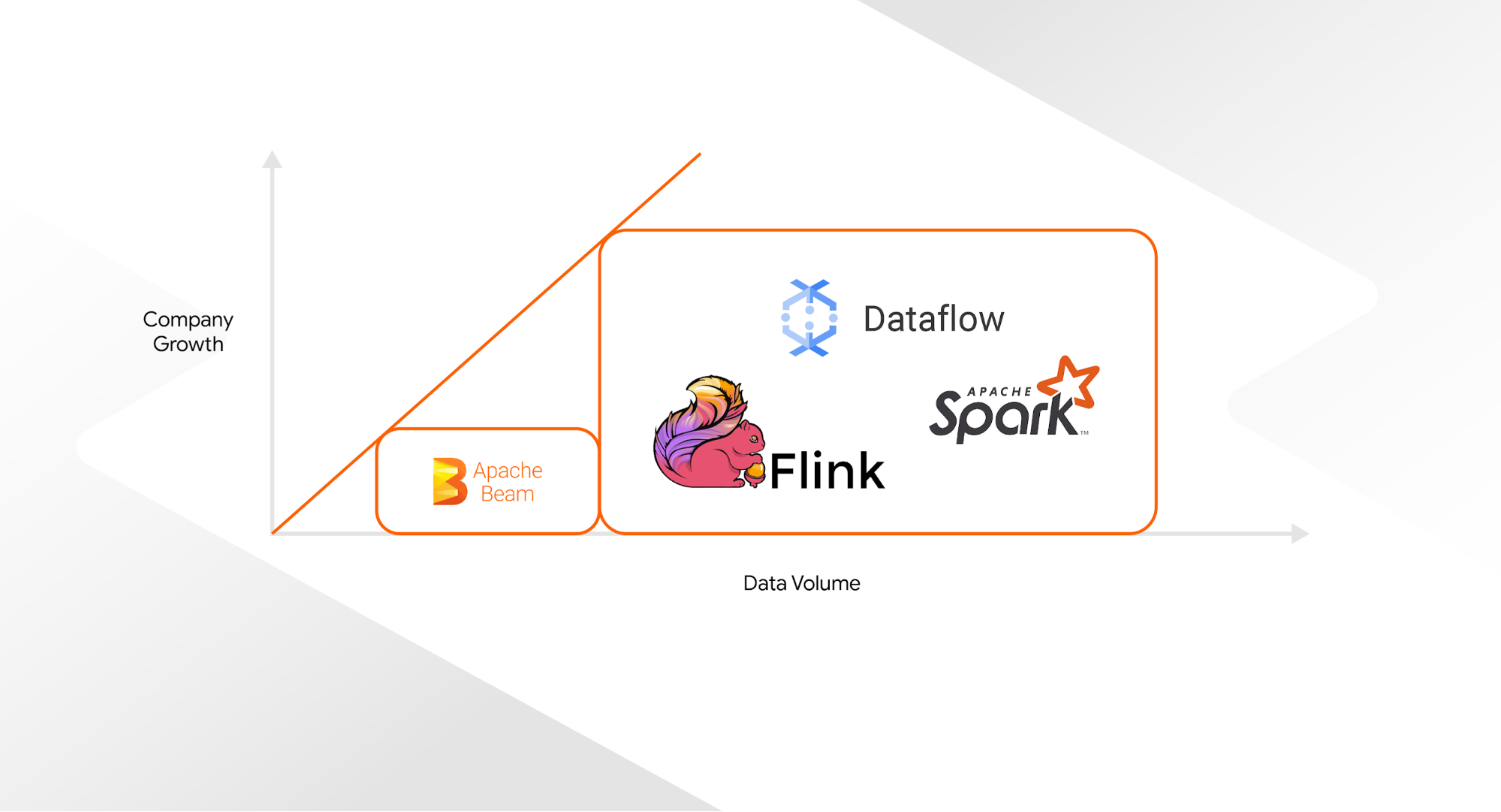 |
| 不同的 Beam 运行器选项,取决于数据量 |
另一个对我们有用的优势是 TFX 如何轻松地与 Google Cloud 生态系统集成。Google Cloud 的 Vertex AI Pipeline 本地支持 TFX,并提供所有必要的管道基础设施作为托管服务。我们无需管理自己的 Kubernetes 集群,可以轻松地在不同 Google Cloud 项目的管道运行之间来回切换。我们也不受集群计算和内存限制的限制,因为我们可以使用 Vertex Pipelines 访问 GPU 和 TPU。
跟踪所有 ML 工件是持续管理生产 ML 模型的关键。我们的目标是跟踪我们所有生产模型的所有相关数据点。我们需要存储工件,如数据集、数据拆分、数据验证结果、特征转换、训练后的模型和模型分析结果。但我们也不想让 ML 团队因为大量的记录工作而减慢速度。
TFX 与 ML 元数据存储 (MLMD) 紧密集成,这有助于我们将所有模型详细信息保存在一个地方。在幕后,我们 ML 管道中的每个 TFX 组件都会记录所有中间管道结果和元数据。我们可以为我们的 ML 管道生成的每个模型生成模型血统,而无需任何额外的开销。当事情发展很快时,这已被证明是一种不可或缺的工具。
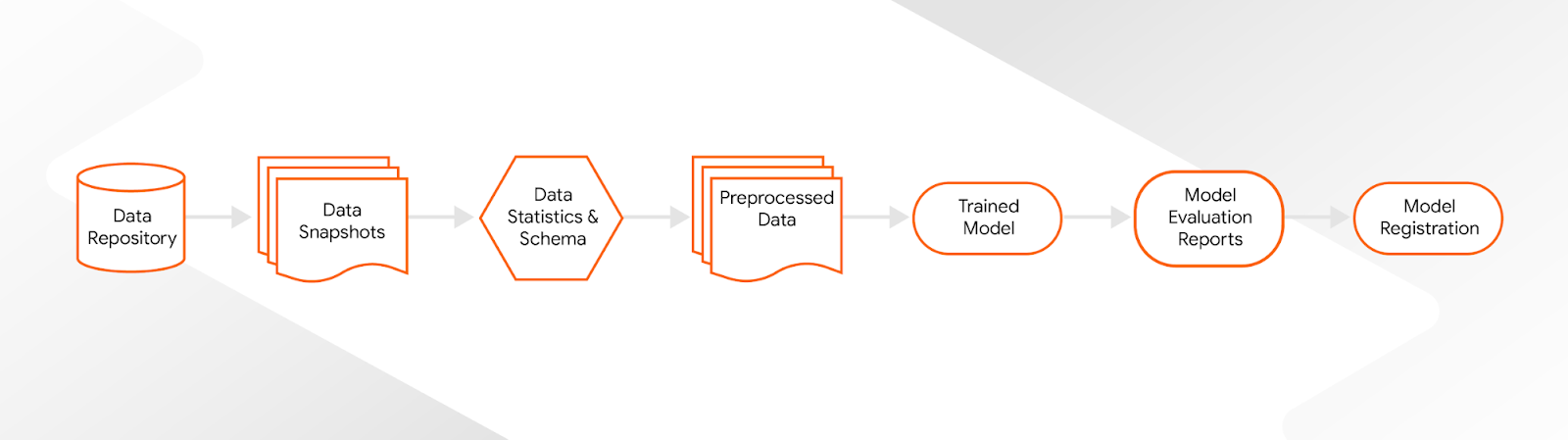 |
| 模型血统 |
虽然将 TFX 适应我们的需求确实需要一些时间,但我们已经看到这项初始投资随着时间的推移得到了回报。我们现在能够将机器学习实验在几分钟内转换为生产管道,并持续生产和部署模型的新版本。
- TFX 帮助我们使我们的 ML 代码库更具模块化。我们已经开发了几个自定义 TFX 组件(例如,用于模型部署、模型注释或模型跟踪)。由于 TFX 组件的模块化,所有项目都可以从单个项目中进行的增强中受益。
- 同时,我们从使用 TFX 标准化我们的生产 ML 代码库中受益。作为一家不断发展的初创公司,我们发现这种标准化特别有用,因为它帮助我们在复杂性增加时保持正轨。新项目现在遵循高度优化的“cookie-cutter”方法,这导致了巨大的时间和劳动力节省。这些标准化还使我们能够自动化模型部署流程的大部分内容,这反过来有助于释放工程能力。我们发现这些节省对于初创公司中常见的小型灵活的 ML 团队至关重要。
- 使用 TFX 还使我们能够为我们的 MLOps 工具做好未来准备。TFX 在幕后使用 Apache Beam 的事实使我们确信,随着公司的发展,我们无需重新设计我们的 MLOps 设置。
- TFX、其元数据存储及其 Google Cloud 集成帮助我们从给定的工件中复制模型,并在需要时更容易准确地重新创建任何以前的 ML 模型。
使用 TFX 发展 Digits 的经验使我们相信,任何认真对待机器学习的公司都可以从 TFX 中受益 - 从小型初创公司到大型公司,在每个步骤中都是如此。
要了解更多关于 TFX 的信息,请查看 TFX 网站,加入 TFX 讨论组,深入了解 TFX 博客 中的其他文章,观看我们的 TFX YouTube 播放列表,或 订阅 TensorFlow 频道。






