由 Charles Gaillard,Mindee 撰写
光学字符识别 (OCR) 是指能够从图像或文档中捕获文本元素并将其转换为机器可读文本格式的技术。 如果您想了解更多相关信息,这篇文章 是一个很好的介绍。
在 Mindee,我们开发了一个名为 DocTR 的开源 Python OCR,但我们也希望将其部署在浏览器中,以确保所有开发者都能使用它,尤其是 约 70% 的开发者选择使用 JavaScript。
我们使用 TensorFlow.js API 实现了这一目标,并最终得到了一个 网页演示,您现在可以使用自己的图像进行尝试。
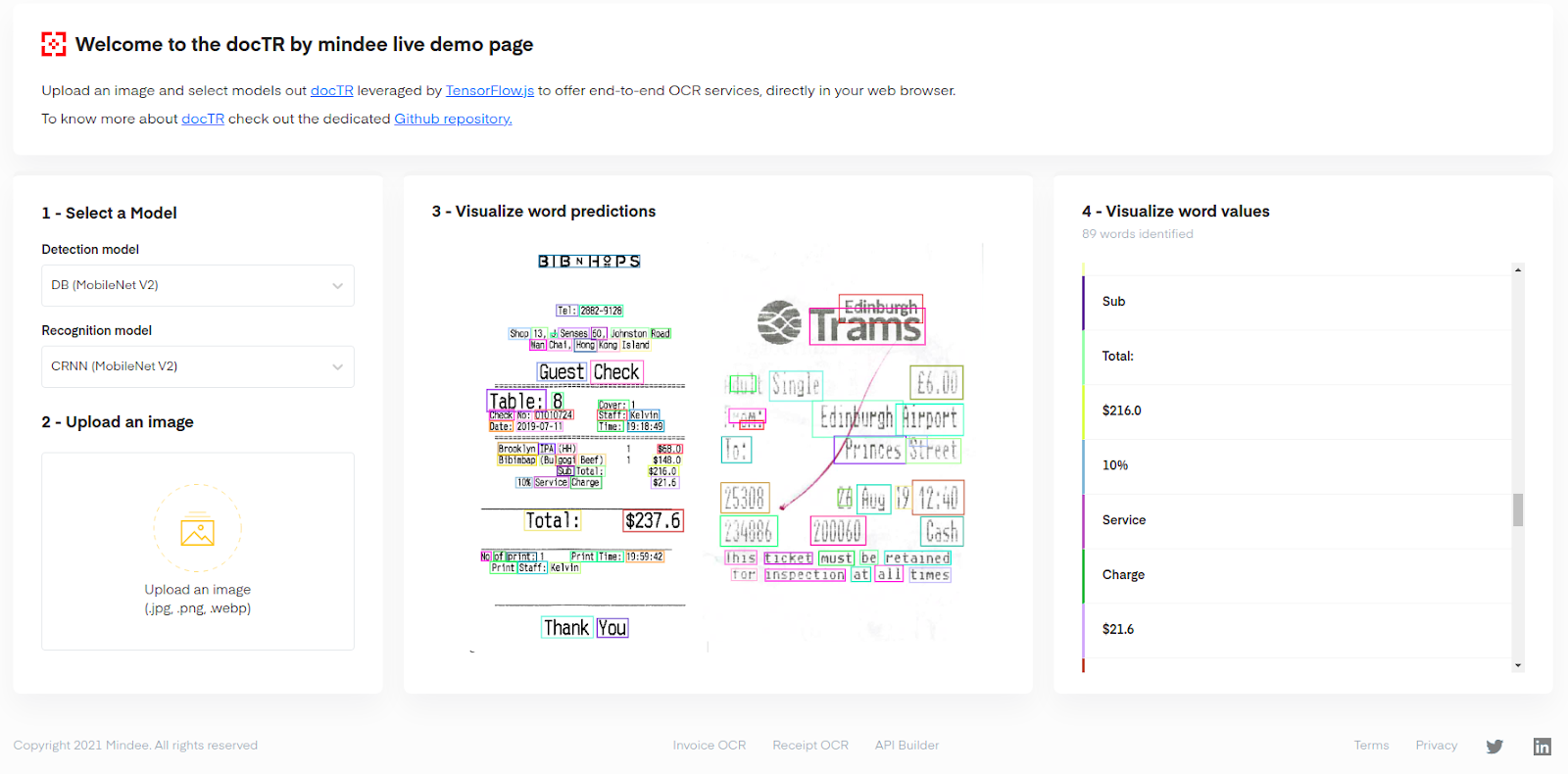
 |
| 演示界面,显示了两张收据的图片,由 OCR 进行解析:共识别出 89 个单词。 |
这个演示旨在非常易于使用,并在大多数计算机上快速运行,因此我们提供了一个经过预训练的模型,该模型使用较小的输入尺寸 (512 x 512) 进行训练,以节省内存。 图像会被调整为正方形,因此它可以很好地推广到大多数纵横比接近 1:1 的文档,例如卡片、较小的收据、票据、A4 纸等。 对于纵横比非常高的矩形,由于我们在文本检测步骤中没有保留纵横比(使用填充),因此分割结果可能不会那么好。 它针对具有显著字体的文档(例如收据、卡片等)进行了优化。 请记住,这些模型旨在在浏览器中运行时提供性能。 因此,对于字体尺寸与文档尺寸相比非常小或纵横比非常高的图像,性能可能不是最佳的。
OCR 模型可以分为两个部分:检测模型和文本识别模型。 在 DocTR 中,检测模型是一个 CNN(卷积神经网络),它对输入图像进行分割以找到文本区域,然后在每个检测到的单词周围裁剪文本框并将其发送到识别模型。 第二个模型是一个卷积循环神经网络 (CRNN),它从单词图像中提取特征,然后使用循环层 (LSTM) 解码图像上的字母序列。
 |
| 此演示中使用的 OCR 模型的全局架构 |
DocTR 中实现了不同的架构,但我们选择了一个非常轻量级的架构供客户端使用,因为设备硬件因人而异。 在这里,我们使用了一个带有 DB(可微分二值化)头的 mobilenetV2 主干。 实现细节可以在 DocTR Github 上找到。 我们使用 (512, 512, 3) 的输入尺寸训练了该模型,以减少延迟和内存使用。 我们有一个由 130,000 个带注释文档组成的私有数据集,该数据集被用于训练此模型。
我们使用的识别模型也是我们最轻量级的架构:一个带有 mobilenetV2 主干的 CRNN(卷积循环神经网络)。 有关此架构的更多信息,请参阅 此处。 它基本上由 mobilenetV2 层的前半部分组成,用于提取特征,并随后由 2 个 双向 LSTM 组成,用于将视觉特征解码为字符序列(单词)。 它使用 Alex Graves 引入的 CTC 损失 来有效地解码序列。 此模型中单词图像的输入尺寸为 (32, 128, 3),我们使用填充来保留裁剪的纵横比。 它使用我们私有数据集进行训练,该数据集包含从不同文档中提取的 1100 万个文本框。 该数据集包含各种各样的字体,因为它包含来自许多不同数据源的文档。 我们使用数据增强,使其能够很好地推广到不同的字体、背景和渲染效果。 它还应该在手写文本上取得不错的效果,只要它是人类可读的。
由于我们的模型最初是使用 TensorFlow 实现的,因此需要进行 Python 转换才能在浏览器中大规模运行生成的模型。 为此,我们为每个训练的 Python 模型导出了一个 tensorflow SavedModel,并使用 tensorflowjs_converter 命令行工具 将保存的模型快速转换为浏览器执行所需的 TensorFlow.js JSON 格式。
然后,生成的转换模型被集成到我们的 React.js 前端应用程序中,该应用程序为 演示 的用户界面提供支持。 更准确地说,我们使用 MUI 来设计我们内部前端 SDK react-mindee-js(提供计算机视觉工具)和 OpenCV.js 的界面组件,用于检测模型后处理。 此后处理步骤使用 OpenCV.js 函数将原始二值化分割图转换为多边形列表。 然后,我们可以从源图像中裁剪这些框,最终得到准备好发送到识别模型的单词图像。
我们必须有效地管理速度和性能之间的权衡。 OCR 模型非常慢,因为您有两个无法并行化的任务(文本区域分割 + 单词识别),因此我们必须使用轻量级模型来确保在大多数设备上快速执行。
在配备 RTX 2060 和 i7 第 9 代处理器的现代计算机上,使用 WebGL 后端,检测任务每张图像需要大约 750 毫秒,识别模型每批 32 个裁剪 (单词) 需要大约 170 毫秒,使用 TensorFlow.js 基准测试工具 进行基准测试。
将两个模型和视觉操作(检测后处理)打包在一起,端到端的 OCR 在小型文档(少于 100 个单词)上的运行时间不到 2 秒,并且在包含大量单词的非常密集的文档上的预测时间只需要几秒钟。

|
| 演示界面截图,显示了一个非常密集的旧 A4 文档,由 OCR 进行解析:共识别出 738 个单词。 |
此演示 由 TensorFlow.js 提供支持,它能够为几乎每个人提供在线、相对快速且稳健的文档 OCR 服务,是第一个完全由 TensorFlow.js 在浏览器中驱动的 OCR。
由于我们在客户端执行模型,因此实际性能会因运行设备的硬件而异。 但是,这里的目标更多是展示,即使是复杂且最先进的深度学习模型也可以部署到浏览器中,并在几乎所有机器上以高效的方式运行,这对可能涉及敏感文档信息的场景非常有用,因为您不想将文档发送到云端进行分析。
我们很高兴能为所有人提供这种解决方案,并热切地关注 Web ML 行业的未来,随着时间的推移,WebGPU 等新的网络标准将成为主流,并默认在现代网络浏览器中启用,毫无疑问,速度将会更快。
2022 年 6 月 7 日 — 由 Charles Gaillard,Mindee 撰写 介绍 光学字符识别 (OCR) 是指能够从图像或文档中捕获文本元素并将其转换为机器可读文本格式的技术。 如果您想了解更多相关信息,这篇文章 是一个很好的介绍。 在 Mindee,我们开发了一个名为 DocTR 的开源 Python OCR,但我们也希望将其部署在浏览器中,以确保所有开发者都能使用它,尤其是 约 70% 的开发者选择使用 JavaScript。





