由 Google 的 Zhi An Ng 和 Marat Dukhan 发布
XNNPack 是浮点模型的默认 TensorFlow Lite CPU 推理引擎,并且 在移动设备、台式机和 Web 平台上提供了显著的加速。XNNPack 中采用的优化之一是将卷积、深度卷积、转置卷积和全连接操作符的静态权重重新打包到内部布局中,该布局针对推理计算进行了优化。在推理期间,重新打包的权重以一种对处理器管道友好的顺序模式进行访问。
推理延迟减少是有代价的:重新打包本质上是在 XNNPack 中创建了权重的额外副本。当 TensorFlow Lite 模型被内存映射时,操作系统最终会释放权重的原始副本,并使开销消失。但是,某些用例需要为同一个模型创建多个 TensorFlow Lite 解释器副本,每个副本都有自己的 XNNPack 代理。由于属于不同 TensorFlow Lite 解释器的 XNNPack 代理彼此不知道,因此它们中的每一个都会创建自己的重新打包权重副本,内存开销会随着代理实例数量的线性增长而增长。此外,由于模型中的原始权重是静态的,因此 XNNPack 中的重新打包权重在所有实例中也是相同的,这使得这些副本浪费且没有必要。
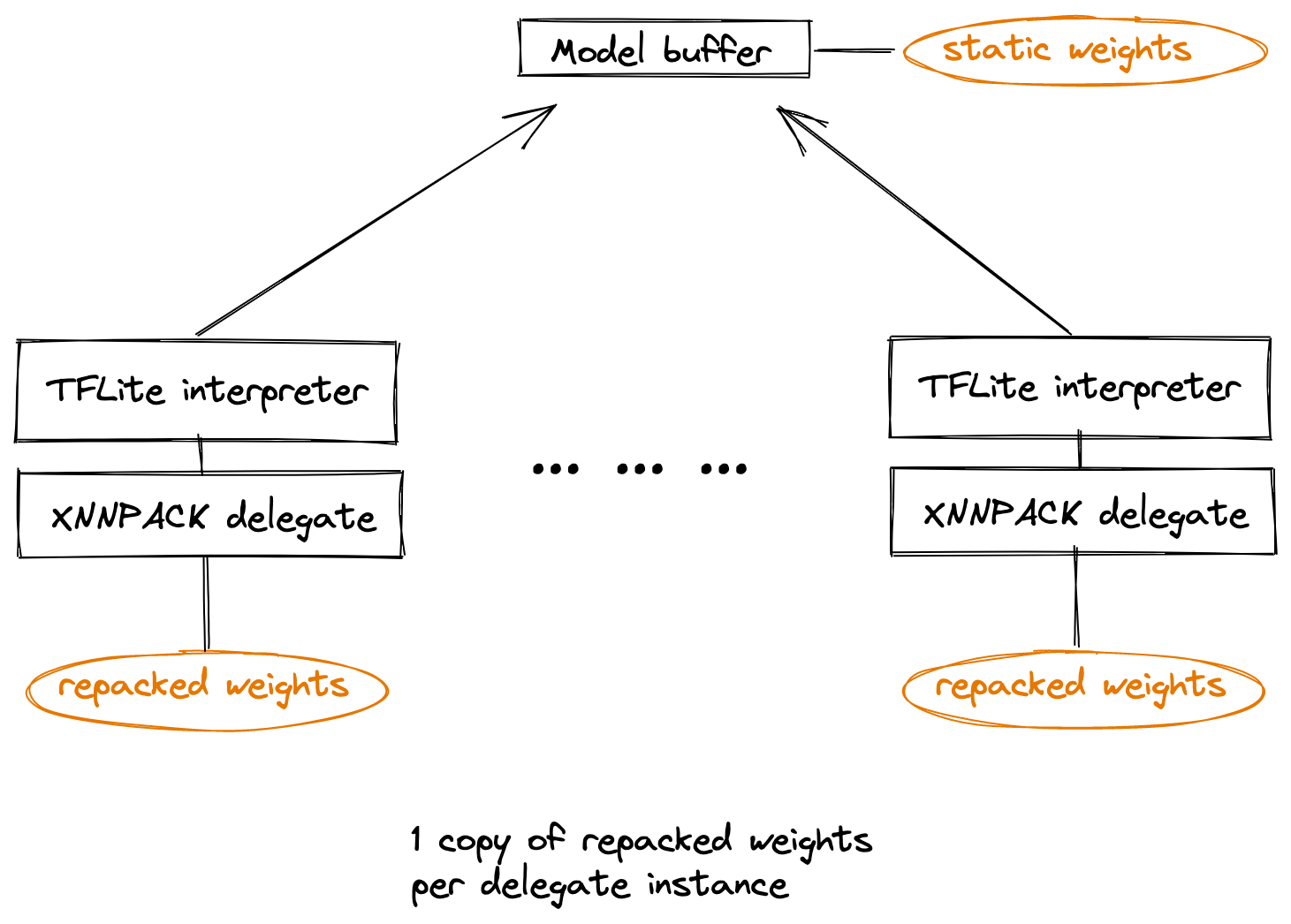
权重缓存是一种机制,允许加速相同模型的多个 XNNPack 代理实例优化其重新打包权重的内存使用情况。使用权重缓存,所有实例都使用相同的底层重新打包权重,从而导致恒定的内存使用量,无论创建了多少解释器实例。此外,由于权重缓存而消除重复项可能会通过提高处理器缓存层次结构的效率来提高性能。注意:权重缓存是一个可选功能,只能通过 C++ API 使用。

下图显示了创建多个实例(横轴)时的最大内存使用量(纵轴)。它将不使用权重缓存的基线与使用具有软最终化的权重缓存进行了比较。使用权重缓存时的峰值内存使用量相对于创建的实例数量增长得慢得多。对于此示例,使用权重缓存允许您在相同的峰值内存预算下将创建的实例数量增加一倍。

权重缓存对象由 TfLiteXNNPackDelegateWeightsCacheCreate 函数创建,并通过代理选项传递给 XNNPack 代理。然后 XNNPack 代理将使用权重缓存来存储重新打包的权重。重要的是,在任何推理调用之前必须完成权重缓存。
// Example demonstrating how to create and finalize a weights cache.
std::unique_ptr<tflite::Interpreter> interpreter;
TfLiteXNNPackDelegateWeightsCache* weights_cache =
TfLiteXNNPackDelegateWeightsCacheCreate();
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
xnnpack_options.weights_cache = weights_cache;
TfLiteDelegate* delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) {
// Static weights will be packed and written into weights_cache.
}
TfLiteXNNPackDelegateWeightsCacheFinalizeHard(weights_cache);
// Calls to interpreter->Invoke and interpreter->AllocateTensors must
// be made here, between finalization and deletion of the cache.
// After the hard finalization any attempts to create a new XNNPack
// delegate instance using the same weights cache object will fail.
TfLiteXNNPackWeightsCacheDelete(weights_cache);
有两种方法可以完成权重缓存,在上面的示例中,我们使用 TfLiteXNNPackDelegateWeightsCacheFinalizeHard,它执行硬最终化。硬最终化具有最少的内存开销,因为它会将权重缓存使用的内存修剪到绝对最小值。但是,在硬最终化之后,不能使用此权重缓存对象创建新的代理 - 使用此缓存的 XNNPack 代理实例数量事先已固定。另一种最终化是软最终化。软最终化具有更高的内存开销,因为它在权重缓存中留有足够的空间用于一些内部簿记。软最终化的优点是可以使用相同的权重缓存来创建新的 XNNPack 代理实例,前提是代理实例使用完全相同的模型。如果代理实例的数量不固定或事先不知道,这将非常有用。
// Example demonstrating soft finalization and creating multiple
// XNNPack delegate instances using the same weights cache.
std::unique_ptr<tflite::Interpreter> interpreter;
TfLiteXNNPackDelegateWeightsCache* weights_cache =
TfLiteXNNPackDelegateWeightsCacheCreate();
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
xnnpack_options.weights_cache = weights_cache;
TfLiteDelegate* delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) {
// Static weights will be packed and written into weights_cache.
}
TfLiteXNNPackDelegateWeightsCacheFinalizeSoft(weights_cache);
// Calls to interpreter->Invoke and interpreter->AllocateTensors can
// be made here, between finalization and deletion of the cache.
// Notably, new XNNPack delegate instances using the same cache can
// still be created, so long as they are used for the same model.
std::unique_ptr<tflite::Interpreter> new_interpreter;
TfLiteDelegate* new_delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
if (new_interpreter->ModifyGraphWithDelegate(new_delegate) !=
kTfLiteOk)
{
// Repacked weights inside of the weights cache will be reused,
// no growth in memory usage
}
// Calls to new_interpreter->Invoke and
// new_interpreter->AllocateTensors can be made here.
// More interpreters with XNNPack delegates can be created as needed.
TfLiteXNNPackWeightsCacheDelete(weights_cache);
使用权重缓存,使用 XNNPack 进行批量推理将减少内存使用量,从而提高性能。在 README 中阅读有关如何在 XNNPack 中使用权重缓存的更多信息,并在 XNNPack 的 GitHub 页面 上报告任何问题。
要保持最新,您可以阅读 TensorFlow 博客,关注 twitter.com/tensorflow,或订阅 youtube.com/tensorflow。如果您构建了一些想分享的内容,请将其提交到 goo.gle/TFCS 中的社区亮点。有关反馈,请在 GitHub 上提交问题或在 TensorFlow 论坛上发帖。谢谢!

2022 年 6 月 6 日 — 由 Google 的 Zhi An Ng 和 Marat Dukhan 发布XNNPack 是浮点模型的默认 TensorFlow Lite CPU 推理引擎,并且 在移动设备、台式机和 Web 平台上提供了显著的加速。XNNPack 中采用的优化之一是将卷积、深度卷积、转置卷积和全连接操作符的静态权重重新打包到内部布局中,该布局针对推理计算进行了优化。在推理期间,重新打包的权重以一种对处理器管道友好的顺序模式进行访问。





