由软件工程师蔡在洪、李里诺和杨凡发布
TensorFlow 模型优化工具包 (TFMOT) 提供了先进的优化技术,如支持量化的训练 (QAT) 和修剪。自 推出 TFMOT 以来,我们一直在持续改进其可用性和覆盖范围。今天,我们很高兴地宣布,我们将 TFMOT 模型覆盖范围扩展到 TensorFlow 模型园地 中流行的计算机视觉模型。
为此,我们为子类化模型和自定义层添加了8 位 QAT API 支持和修剪 API 支持。您可以在模型花园中使用这些新特性,以及在开发您自己的模型时使用。通过这些特性,我们演示了将 QAT 和修剪应用到若干经典计算机视觉模型,同时显著加速了模型开发周期。
在这篇文章中,我们将描述在子类化模型和自定义层应用 QAT 和修剪时遇到的技术难题。并展示经过优化的结果以说明优化技术的益处。
我们已经解决了几个技术难题以支持子类化模型并简化应用 QAT API 的过程。TFMOT 和模型花园已经处理所有的新更改,从而让用户无需了解所有技术细节。在模型花园中将 QAT 应用到计算机视觉模型的面向最终用户的 API 非常直接。通过应用一些配置更改,您可以在几小时内启用 QAT 对预训练模型进行微调,并获得一个可部署的设备模型。完全无需或仅需最少的代码更改。我们将在本文中探讨那些难题以及我们如何解决它们。
先前的 QAT API 假设模型仅包含内置层。为了支持嵌套功能模型,我们将 QAT 方法单独应用到模型的不同部分。例如,将 QAT 应用到模型花园中的图像分类模型 (M),该模型包含两个子模块:主干网络 (B) 和分类层 (C)。其中 B 是 M 中的嵌套模型,而 C 是个层。B 和 C 都只包含内置层。我们不等同于直接将 QAT 运用到整个分类模型 M 上,而是分别对主干 B 和分类层 C 进行量化。首先,我们仅将 QAT 应用到主干 B。然后我们将经过量化的主干 B 连接到其对应的分类层 C,以形成一个新的分类模型,并标注 C 以进行量化。最后,我们对整个新模型进行量化,这有效地将 QAT 应用到了标注的分类层 C。
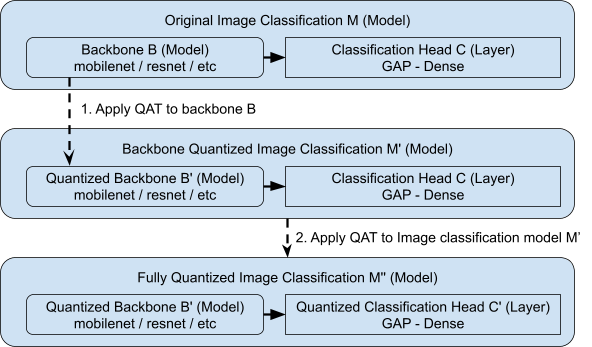 |
如果主干网络还包含自定义层,而不是内置层,我们首先添加这些自定义层的量化版本。例如,如果分类模型 (M) 的主干网络 (B) 或分类层 (C) 也包含一个名为 MyLayer 的自定义层,我们创建一个名为 MyLayerQuantized 的 QAT 对应项,并通过量化包装器 API 包装其中的任何内置层。如果存在嵌套的自定义层,我们会重复执行这个过程,直至正确包装所有内置层。
应用量化后的剩余部分是加载自原始模型的权重,因为应用了 QAT 的模型由于包含额外的量化参数而包含更多参数。我们目前的解决方案是变量名称过滤。我们已经添加了一个逻辑,将权重从原始模型加载到应用了 QAT 的模型的已过滤权重,以支持针对预训练模型的微调。
除了 QAT,我们还提供修剪的两个 Model Garden 模型,这是 MOT 的另一种训练中模型优化技术。修剪于训练期间使给定模型的权重变得稀疏(强制一定部分元素变为零),从而提高计算效率并节省存储空间。
用户可以轻松地在 Model Garden 配置中设置修剪参数。为了提高修剪模型质量,从预训练稠密模型开始进行修剪,并且在训练步骤中仔细调整修剪计划是众所周知的方法。两者都在 Model Garden 修剪配置中提供。
本工作还提供了修剪中嵌套函数层支持的一个示例。我们在使用get_prunable_weight()方法时的方式也适用于具有自定义层的任何其他 Keras 模型。
借助于提供的两个 Model Garden 修剪配置,用户可以快速演示对图像分类的 ResNet50 和 MobileNetV2 模型进行修剪。了解修剪 API 的实际用法以及通过监控张量板来了解修剪过程也是本工作的另一个收获。
我们支持图像分类和语义分割两种任务。具体而言,对于图像分类中的 QAT,我们支持常见的 MobileNet 系列,包括MobileNetV2、MobileNetV3(大)、多硬件 MobileNet(AVG)和ResNet(通过在常见构建模块(例如 InvertedBottleneckBlockQuantized 和BottleneckBlockQuantized)上进行量化)。对于语义分割中的 QAT,我们支持带有 DeepLab V3/V3+ 的 MobileNetV2 主干。对于图像分类中的修剪,我们支持MobileNetV2和ResNet。有关更多详细信息,请参阅 QAT 和修剪 的文档。
对模型花园使用 QAT 简单明了。首先,我们按照使用模型花园训练模型的标准流程来训练一个浮点模型。训练收敛后,我们采用最优检查点作为我们的起点来应用 QAT,类似于微调阶段。很快,我们将获得一个更适合量化的模型。然后可以将此类模型转换为 TFLite 模型,以部署到设备上。
对于图像分类,我们评估 ImageNet 验证集上的前 1 准确度。如表 1 所示,QAT 模型始终以很大优势优于 PTQ 模型,并且达到相当的延迟。值得注意的是,对于 PTQ 无法生成合理结果的模型(MobileNetV3),QAT 仍然能够生成一个强大的量化模型,且精度几乎没有下降。
表 1. ImageNet 分类中支持模型的准确度和延迟比较。延迟使用三星 Galaxy S21 在 1 线程 CPU 上进行测量。FP32 指未量化的浮点 TFLite 模型。PTQ INT8 指完全整数训练后量化。QAT INT8 指量化的 QAT 模型。
* 由于硬 swish 激活,PTQ 无法对 MobileNet V3 进行正确量化,从而导致准确度较低。
我们在语义分割中也观察到类似情况:与 FP32 模型相比,PTQ 引入了 1.3 mIoU 下降,而 QAT 模型将下降最小化至仅 0.7,且保持了相当的延迟。平均而言,我们预计对于图像分类,QAT 仅会导致前 1 准确度下降 0.5,对于语义分割,下降不到 1 mIoU。
表 2. Pascal VOC 分割中 MobileNet v2 + DeepLab v3 的准确度和延迟比较。延迟使用三星 Galaxy S21 在 1 线程 CPU 上进行测量。FP32 指未量化的浮点 TFLite 模型。PTQ INT8 指完全整数训练后量化。QAT INT8 指量化的 QAT 模型。
我们支持用于图像分类的 ResNet50 和 MobileNet v2。基于模型园区训练配置生成每个任务的预训练稠密模型。剪枝模型可转换为 TFLite 模型。在 TFLite 转换中只需设置稀疏性标志,便可以通过稀疏数据格式获得模型大小减少的好处。
对于图像分类,我们再次对 ImageNet 验证集评估顶级 1 准确率以及转换的 TFLite 模型的大小。随着稀疏性级别的提高,模型大小变得更紧凑,但准确率下降。在 MobileNetV2 等参数有效的模型中,高稀疏性的准确率影响更为严重。
表 3. ResNet-50 和 MobileNet v2 的 ImageNet 分类准确率和模型大小比较。模型大小通过已保存 TFLite 模型的磁盘使用情况衡量。稠密指未修剪的 TFLite 模型,50% 稀疏性指所有可修剪层权重的 TFLite 模型随机修剪 50% 个元素。
我们已为 TFMOT 提出了一项扩展功能,该功能可为“模型花园”中的计算机视觉模型提供 QAT 和修剪支持。我们重点介绍了易用性和保持准确性且模型大小或延迟低时取得的出色折中效果。
虽然我们认为这是一个简单且用户友好的解决方案,可以实现 QAT 和修剪,但我们知道这只是提供更好可用性的精简工作流程的开始。
当前,受支持的任务仅限于图像分类和语义分割。我们将会继续为其他任务(例如对象检测和实例分割)添加更多支持。我们还将会添加更多模型(例如基于转换器的模型)并提升 TFMOT 和“模型花园”API 的可用性。感谢您对此工作的关注。
我们谨向所有为这项工作做出贡献的人员表示感谢,包括“模型花园”、“模型优化”,以及我们在研究部门的合作者们。特别感谢“模型优化”团队的大卫·里姆(已退休)和伊桑·金(已退休);“模型花园”团队的阿卜杜拉·拉什万、杜显之、李叶青、金在允和李静;终端设备机器学习团队的李芋琦。

2022 年 6 月 9 日 — 该文章由软件工程师 Jaehong Kim、Rino Lee 和 Fan Yang 发表 TensorFlow 模型优化工具包 (TFMOT) 提供了先进的优化技术,例如量化感知训练 (QAT) 和修剪。自从 TFMOT 推出 以来,我们一直在不断提升其可用性和覆盖范围。今天,我们很高兴地宣布,我们将 TFMOT 模型的覆盖范围扩展到了热门的…





