作者:Nikita Namjoshi,Google Cloud 开发者倡导者
当你开始着手处理新的机器学习问题时,我猜你首先会使用笔记本。也许你喜欢在本地环境中运行 Jupyter,使用 Kaggle Kernel,或者是我个人最喜欢的 Colab。借助这些工具,创建和实验机器学习变得越来越容易。但虽然在笔记本中进行实验很棒,但在将你的实验提升到生产规模时,很容易遇到瓶颈。突然之间,你的关注点不仅仅是获得最高的准确率分数。
如果你的工作需要长时间运行,想进行分布式训练,或托管模型以进行在线预测怎么办?或者,也许你的用例需要围绕安全性和数据隐私进行更细粒度的权限控制。你的数据在服务时间将是什么样子,你将如何处理代码更改,或如何监控模型的性能?
创建生产应用程序或训练大型模型需要额外的工具来帮助你超越笔记本中的代码进行扩展,使用云服务提供商可以提供帮助。但这个过程可能让人感觉有点让人望而生畏。看一下 Google Cloud 产品 的完整列表,你可能会完全不知道从哪里开始。
因此,为了让你的旅程更容易一些,我将向你展示一条从实验性笔记本代码到云端部署模型的快速路径。
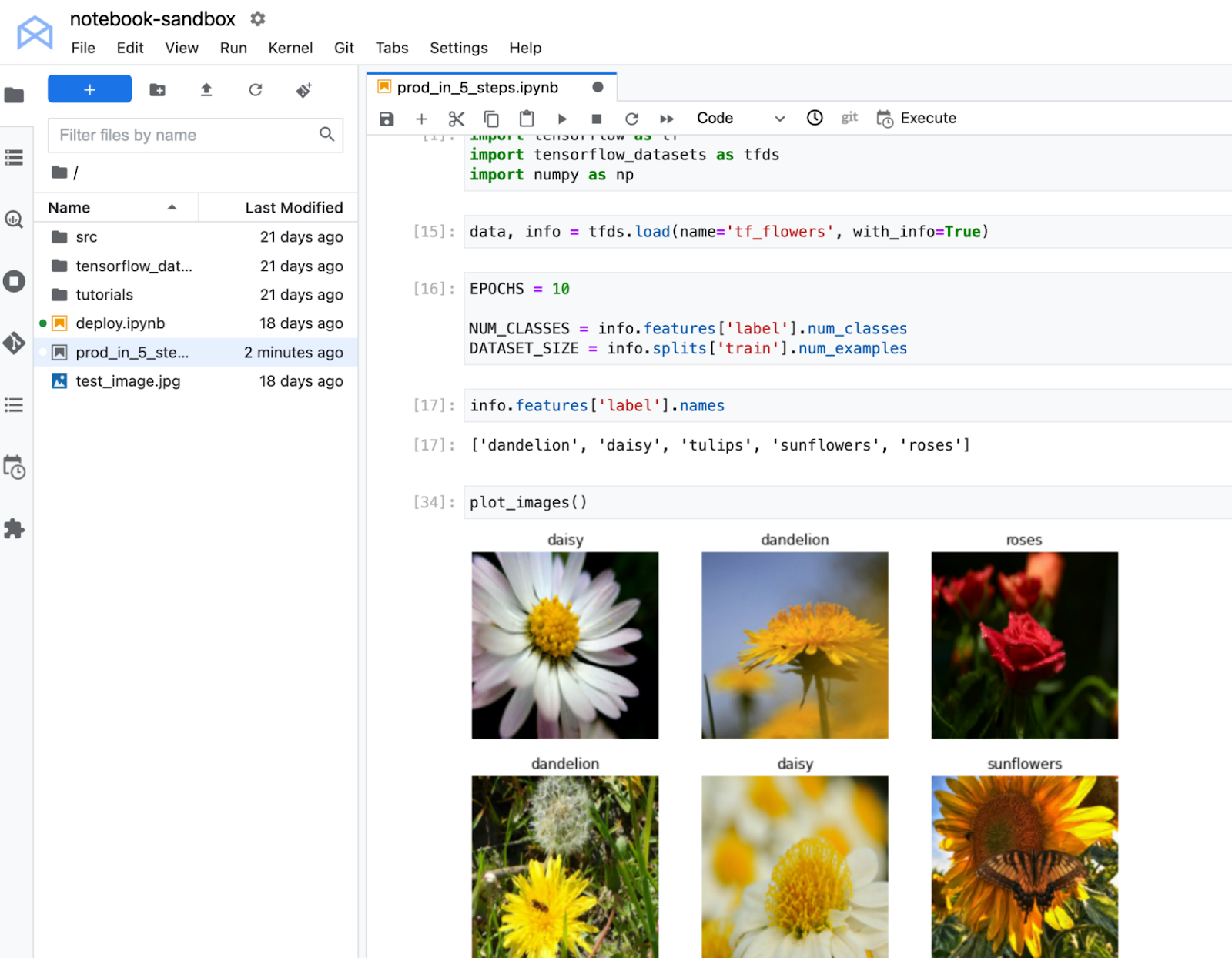
本示例中使用的代码可以 在这里找到。此笔记本在 TF Flowers 数据集 上训练了一个图像分类模型。你将看到如何在云端部署此模型,以及通过 REST 端点获取新花卉图像的预测。
请注意,你需要一个启用了计费功能的 Google Cloud 项目来完成本教程。如果你以前从未使用过 Google Cloud,你可以 按照这些说明 设置项目并获得 300 美元的免费信用额度来进行实验。
以下是你将采取的五个步骤
为了训练和部署模型,你将使用 Vertex AI,它是 Google Cloud 的托管机器学习平台。Vertex AI 包含许多不同的产品,可以帮助你在整个 ML 工作流程的生命周期中提供帮助。今天你将使用其中的一些产品,首先是 Workbench,它是托管笔记本产品。
在 云控制台 的 Vertex AI 部分,选择“Workbench”。请注意,如果这是你第一次在项目中使用 Vertex AI,系统会提示你启用 Vertex API 和 Notebooks API。因此请确保点击 UI 中的按钮来执行此操作。

接下来,选择 **托管笔记本**,然后选择 **新建笔记本**。

在 **高级设置** 下,你可以通过指定机器类型和位置、添加 GPU、提供自定义容器和启用终端访问来自定义笔记本。现在,保留默认设置,只需提供笔记本的名称。然后点击创建。

当你看到 **打开 JUPYTERLAB** 文本变为蓝色时,你就知道你的笔记本已准备就绪。首次打开笔记本时,系统会提示你进行身份验证,你可以按照 UI 中的步骤进行操作。

当你打开 JupyterLab 实例时,你会看到几个不同的笔记本选项。Vertex AI Workbench 提供不同的内核(TensorFlow、R、XGBoost 等),这些内核是预装了数据科学常用库的托管环境。如果需要向内核添加其他库,可以使用笔记本单元中的 pip install,就像在 Colab 中一样。

第一步完成!你已创建了托管的 JupyterLab 环境。
现在是将 TensorFlow 代码导入 Google Cloud 的时候了。如果你一直在其他环境(Colab、本地等)中工作,你可以将所需的任何代码工件上传到 Vertex AI Workbench 托管笔记本,甚至可以与 GitHub 集成。将来,你可以在 Workbench 中完成所有开发工作,但现在让我们假设你一直在使用 Colab。
Colab 笔记本可以导出为 .ipynb 文件。

你可以通过点击“上传文件”图标将文件上传到 Workbench。

当你打开 Workbench 中的笔记本时,系统会提示你选择内核,即笔记本运行的环境。你可以选择几个不同的内核,但由于此代码示例使用 TensorFlow,因此你将要选择 TensorFlow 2 内核。

在选择内核后,你在笔记本中执行的任何单元格都将在此托管的 TensorFlow 环境中运行。例如,如果你执行导入单元格,你会看到你可以导入 TensorFlow、TensorFlow Datasets 和 NumPy。这是因为所有这些库都包含在 Vertex AI Workbench TensorFlow 2 内核中。不出所料,如果你尝试在 XGBoost 内核中执行相同的笔记本单元格,你会看到错误消息,因为 TensorFlow 没有安装在那里。
虽然我们可以手动运行笔记本的其余单元格,但对于需要很长时间才能训练的模型,笔记本并不总是最方便的选择。如果你正在构建一个包含 ML 的应用程序,你可能不会只训练一次模型。随着时间的推移,你将希望重新训练模型以确保它保持最新状态并继续产生有价值的结果。
当你开始处理新的机器学习问题时,手动执行笔记本的单元格可能是正确选择。但是,当你希望在更大的范围内自动化实验,或为生产应用程序重新训练模型时,托管的 ML 训练选项将使事情变得容易得多。
启动训练作业的最快方法是通过 笔记本执行功能,它将在 Vertex AI 托管训练服务上逐个单元格地运行笔记本。
当你启动训练作业时,它将在你完成作业后无法访问的机器上运行。因此,你不想将 TensorFlow 模型工件保存到本地路径。相反,你将希望保存到 Cloud Storage,它是 Google Cloud 的对象存储,这意味着你可以存储图像、csv 文件、txt 文件、保存的模型工件。几乎任何东西都可以。
云存储具有“存储桶”的概念,存储桶用于保存你的数据。你可以 通过 UI 创建存储桶。你在 Cloud Storage 中存储的所有内容都必须包含在存储桶中。在存储桶内,你可以创建文件夹来组织你的数据。
Cloud Storage 中的每个文件都有一个路径,就像你本地文件系统中的文件一样。除了 Cloud Storage 路径始终以 **gs://** 开头
你将希望更新你的训练代码,以便你保存到 Cloud Storage 存储桶而不是本地路径。
例如,在这里,我已将笔记本的最后一个单元格从 model.save('model_ouput').更新。不再保存到本地,我现在将工件保存到我在项目中创建的名为 nikita-flower-demo-bucket 的存储桶中。

现在我们已准备好启动执行。
选择执行按钮,为你的执行提供一个名称,然后添加一个 GPU。在环境下,选择 TensorFlow 2.7 GPU 镜像。此容器预装了 TensorFlow 和许多其他数据科学库。
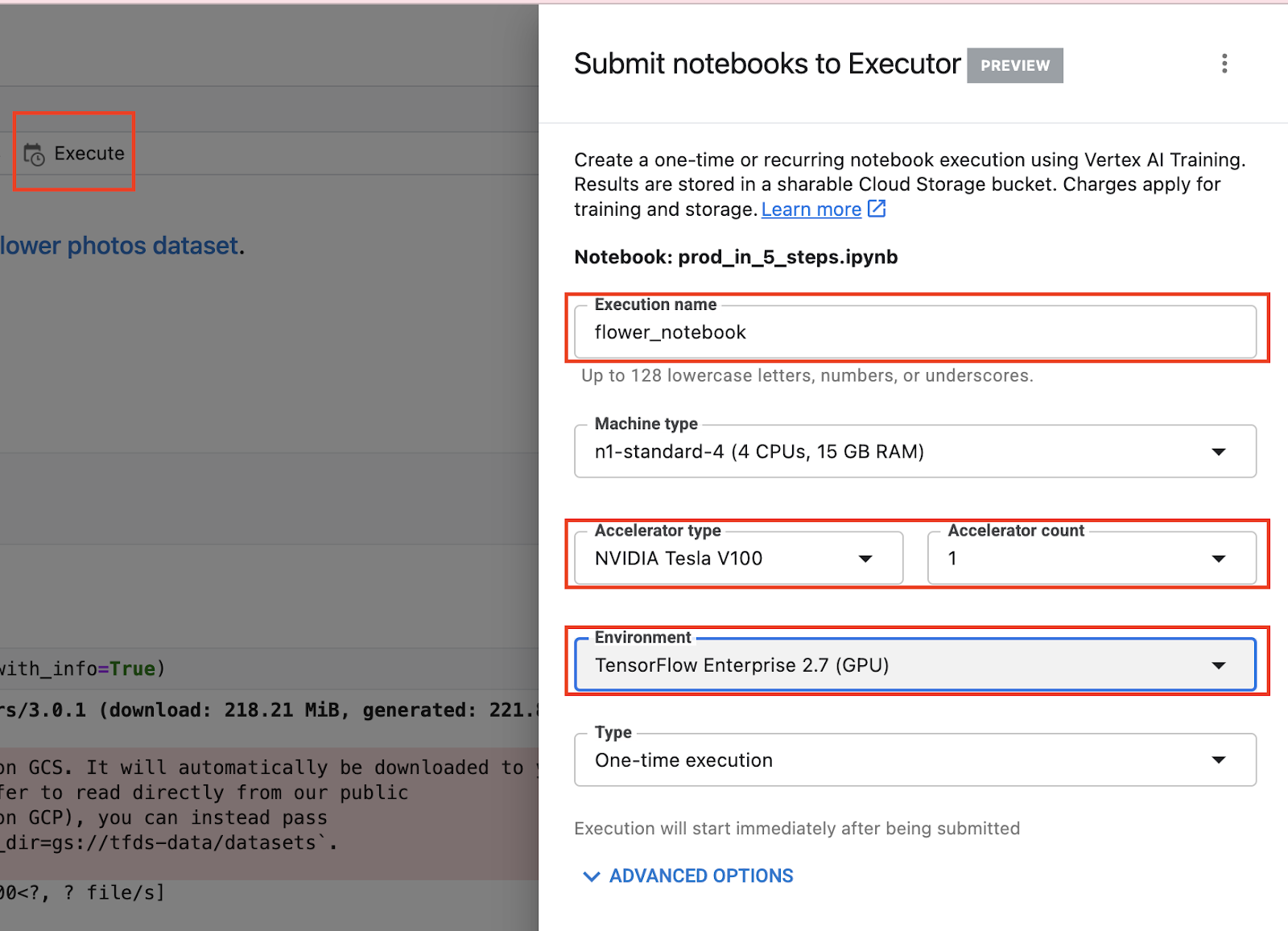
然后点击 **提交**。
你可以在 **执行** 选项卡中跟踪训练作业的状态。笔记本和每个单元格的输出将在作业完成并存储在 GCS 存储桶中时在 **查看结果** 下可见。这意味着你始终可以将模型运行与执行的代码关联起来。

训练完成后,你将能够在你的存储桶中看到 TensorFlow 保存的模型工件。

现在你知道了如何在 Google Cloud 上快速启动无服务器训练作业。但 ML 不仅仅是关于训练。如果我们不实际使用模型来做点什么,那么所有这些努力有什么意义,对吧?
就像训练一样,我们可以通过在笔记本中调用 model.predict 来直接执行预测。但是,当我们希望获取大量数据的预测,或实时获取低延迟预测时,我们将需要比笔记本更强大的东西。
返回到 Vertex AI Workbench 托管笔记本中,你可以在一个单元格中粘贴下面的代码,该代码将使用 Vertex AI Python SDK 将你刚刚训练的模型部署到 Vertex AI Prediction 服务。将模型部署到端点会将保存的模型工件与物理资源关联起来,以实现低延迟预测。
首先,导入 Vertex AI Python SDK。
from google.cloud import aiplatform
然后,将你的模型上传到 Vertex AI 模型注册表。你需要为你的模型提供一个名称,并提供一个服务容器镜像,即运行预测的环境。Vertex AI 为服务提供 预构建的容器,在本示例中,我们使用的是 TensorFlow 2.8 镜像。
您还需要将artifact_uri替换为您保存的模型工件存储的存储桶路径。对我来说,那是“nikita-flower-demo-bucket”。您还需要将project 替换为您的项目 ID。
my_model = aiplatform.Model.upload(display_name='flower-model',
artifact_uri='gs://{YOUR_BUCKET}',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest',
project={YOUR_PROJECT})
然后将模型部署到端点。我现在使用默认值,但如果您想了解有关流量分配和自动缩放的更多信息,请务必查看文档。请注意,如果您的用例不需要低延迟预测,则无需将模型部署到端点,并且可以使用批量预测功能。
endpoint = my_model.deploy(
deployed_model_display_name='my-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
部署完成后,您可以在控制台中看到您的模型和端点

现在,此模型已部署到端点,您可以像任何其他 REST 端点一样访问它。这意味着您可以将您的模型集成并获取预测到下游应用程序中。
现在,让我们直接在 Workbench 中对其进行测试。
首先,打开一个新的 TensorFlow 笔记本。

在笔记本中,导入 Vertex AI Python SDK。
from google.cloud import aiplatform
然后,创建您的端点,替换project_number和endpoint_id。
endpoint = aiplatform.Endpoint(
endpoint_name="projects/{project_number}/locations/us-central1/endpoints/{endpoint_id}")
您可以在云控制台的端点部分找到您的端点 ID。

您可以在控制台首页上找到您的项目编号。请注意,这与项目 ID 不同。

当您向在线预测服务器发送请求时,请求将由 HTTP 服务器接收。HTTP 服务器从 HTTP 请求内容正文中提取预测请求。提取的预测请求将转发到服务函数。在线预测的基本格式是数据实例列表。这些可以是简单的值列表,也可以是 JSON 对象的成员,具体取决于您在训练应用程序中配置输入的方式。
为了测试端点,我首先将一朵花的图像上传到我的工作台实例。

下面的代码使用 PIL 打开并调整图像大小,并将其转换为 numpy 数组。
import numpy as np from PIL import Image IMAGE_PATH = 'test_image.jpg' im = Image.open(IMAGE_PATH) im = im.resize((150, 150))
然后,我们将 numpy 数据转换为 float32 类型并转换为列表。我们转换为列表是因为 numpy 数据不可 JSON 序列化,因此我们无法在请求正文中发送它。请注意,我们不需要将数据按 255 缩放,因为该步骤已作为模型架构的一部分包含在内,使用tf.keras.layers.Rescaling(1./255). 为了避免必须调整图像大小,我们可以将 tf.keras.layers.Resizing 添加到我们的模型中,而不是将其作为tf.data 管道的一部分。
# convert to float32 list x_test = [np.asarray(im).astype(np.float32).tolist()]
然后,我们调用预测函数。
endpoint.predict(instances=x_test).predictions
您得到的结果是模型的输出,它是一个具有 5 个单元的 softmax 层。看起来索引为 2(郁金香)的类得分最高。
[[0.0, 0.0, 1.0, 0.0, 0.0]]
提示:为了节省成本,如果您不打算使用端点,请务必取消部署端点!您可以通过转到控制台的“端点”部分,选择端点,然后选择“从端点取消部署模型”选项来取消部署。您可以在将来需要时重新部署。

对于更现实的示例,您可能希望直接将图像本身发送到端点,而不是先在 NumPy 中加载它。如果您想查看示例,请查看此笔记本。
您现在知道如何从笔记本实验到云端部署。牢记这个框架,我希望您开始考虑如何使用笔记本和 Vertex AI 构建新的 ML 应用程序。
如果您有兴趣了解有关如何使用 Google Cloud 将 TensorFlow 模型投入生产的更多信息,请务必注册即将到来的 Google Cloud 应用机器学习峰会。 此虚拟活动定于 6 月 9 日举行,汇集了全球领先的专业机器学习工程师和数据科学家。与其他 ML 工程师和数据科学家联系,探索加速实验、快速投入生产、扩展和管理模型以及自动化管道以产生影响的新方法。立即预留您的座位!






