作者:Hugo Zanini,数据产品经理
去年,我在 如何使用 TensorFlow.js 在浏览器中训练自定义目标检测 上发表了一篇文章。这引起了来自世界各地开发人员的极大兴趣,他们试图将该解决方案应用于他们的个人或商业项目。在回答读者对我第一篇文章的疑问时,我注意到在将我们的解决方案应用于大型数据集以及使用新版 TensorFlow.js 在生产中部署生成的模型时存在一些困难。
因此,本文的目的是分享一个针对消费品行业中一个普遍问题的解决方案:使用 TensorFlow.js 进行实时离线SKU 检测。

| 使用 TensorFlow.js 在智能手机上实时运行的离线 SKU 检测 |
问题
消费者经常消费的商品(食品、饮料、家庭用品等)需要对这些产品进行大量补充和放置在销售点(超市、便利店等)。
在过去几年中,研究人员反复表明,大约三分之二的购买决定是在顾客进入商店后做出的。对于消费品公司来说,最大的挑战之一是保证其产品在商店中的可用性和正确放置。
在商店中,团队根据营销策略组织货架,并管理商店中产品的水平。从事这些活动的人员可能会计算商店中每个品牌的 SKU 数量以估计产品库存和市场份额,并帮助制定营销策略。
但是,这些估计非常耗时。拍摄照片并使用算法计算货架上的 SKU 数量以计算品牌的市场份额可能是一个很好的解决方案。
为了使用这种方法,检测应实时运行,以便您将手机摄像头对准货架时,算法会识别品牌并计算市场份额。而且,由于商店内部的互联网通常有限,因此检测应该离线工作。

| 示例工作流程 |
这篇文章将展示如何使用 SKU110K 数据集 和 MobileNetV2 网络实现实时离线图像识别解决方案来识别通用 SKU。
由于缺少带有不同品牌标记 SKU 的公共数据集,我们将创建一个通用算法,但所有说明都可以在多类问题中应用。
与每个机器学习流程一样,该项目将分为以下四个步骤

| 目标检测模型生产管道 |
准备数据
训练良好模型的第一步是收集良好数据。如前所述,此解决方案将使用一个在不同场景中包含 SKU 的数据集。SKU110K 的目的是为能够识别密集场景中物体的模型创建基准。
数据集以Pascal VOC 格式提供,必须转换为tf.record。用于执行转换的脚本 可以在此处获得,数据集的tf.record 版本也在我的项目存储库 中。如前所述,SKU110K 是一个庞大且极具挑战性的数据集。它包含许多物体,这些物体经常看起来相似甚至相同,并且彼此靠近。
为了使用此数据集,所选的神经网络必须在识别模式方面非常有效,并且足够小以在 TensorFlow.js 中实时运行。
选择模型
有各种神经网络能够解决 SKU 检测问题。但是,能够轻松实现高精度水平的架构非常密集,并且在转换为 TensorFlow.js 以实时运行时没有合理的推理时间。
因此,这里的方法将集中在优化一个中等水平的神经网络,以实现能够在密集场景中工作并实时运行推断的合理精度。分析 TensorFlow 2.0 目标检测模型动物园,挑战将是尝试使用可用的更轻的单次射击模型来解决问题:SSD MobileNet v2 320x320,它似乎符合所需条件。该架构已被证明能够识别多达 90 个类别,并且可以训练以识别不同的 SKU。
训练模型
有了好的数据集和所选的模型,现在该考虑训练过程了。TensorFlow 2.0 提供了一个 目标检测 API,它使构建、训练和部署目标检测模型变得容易。在这个项目中,我们将使用这个 API 并使用 Google Colaboratory 笔记本 训练模型。本节的其余部分解释了如何设置环境、模型选择和训练。如果您想直接跳转到 Colab 笔记本, 请点击这里。
设置环境
创建 一个新的 Google Colab 笔记本并选择 GPU 作为硬件加速器
Runtime > Change runtime type > Hardware accelerator: GPU
克隆、安装和测试 TensorFlow 目标检测 API
接下来,使用以下命令下载并解压缩数据集
设置训练管道
我们准备配置训练管道。TensorFlow 2.0 为 SSD Mobilenet v2 320x320 在 COCO 2017 数据集 上提供了预训练权重,并且可以使用以下命令下载它们
下载的权重是在 COCO 2017 数据集 上预训练的,但这里的重点是训练模型以识别一个类别,因此这些权重将仅用于初始化网络——这种技术称为 迁移学习,并且它通常用于加快学习过程。
最后一步是在配置文件中设置超参数,该文件将在训练期间使用。选择最佳超参数是一项需要一些实验的任务,因此需要计算资源。
我从 TensorFlow 模型配置存储库 中获取了 MobileNetV2 参数的标准配置,并执行了一系列实验(感谢 Google 开发人员提供的免费资源)以优化模型以使用 SKU110K 数据集在密集场景中工作。下载配置并使用以下代码检查参数。
设置完参数后,通过执行以下命令开始训练
为了识别训练进行得如何,我们使用损失值。损失是一个数字,表示模型对训练样本的预测有多糟糕。如果模型的预测完美,则损失为零;否则,损失更大。训练模型的目标是找到一组权重和偏差,这些权重和偏差在所有示例中平均具有较低的损失(深入 ML:训练和损失 | 机器学习速成课程)。
训练过程通过 Tensorboard 监控,在使用 NVIDIA Tesla P4 的 60GB 机器上完成大约需要 22 小时。最终损失可以在下面检查

| 总训练损失 |
验证模型
现在让我们使用测试数据评估训练过的模型
评估是在 2740 张图像上完成的,并根据 COCO 检测评估指标 提供了三个指标:精度、召回率和损失(分类:精度和召回率 | 机器学习速成课程)。相同的指标通过 Tensorboard 提供,并且可以以更简单的方式进行分析
%load_ext tensorboard %tensorboard --logdir '/content/training/'
然后,您可以探索所有训练和评估指标。

| 主要评估指标 |
导出模型
现在训练已经验证,该导出模型了。我们将训练检查点转换为protobuf (pb) 文件。该文件将包含图形定义和模型的权重。
由于我们将使用 TensorFlow.js 部署模型,而 Google Colab 的最大生命周期限制为 12 小时,因此让我们下载训练过的权重并将其保存在本地。当运行命令 files.download("/content/saved_model.zip") 时,Colab 将自动提示文件下载。
部署模型
该模型将以一种任何人都可以通过打开电脑或手机摄像头并在网页浏览器中实时执行推断的方式部署。为此,我们将保存的模型转换为 TensorFlow.js 层格式,将模型加载到 JavaScript 应用程序中,并将所有内容在 CodeSandbox 上提供。
转换模型
此时,您应该在本地保存了类似于以下结构的内容
%MD
├── inference-graph
│ ├── saved_model
│ │ ├── assets
│ │ ├── saved_model.pb
│ │ ├── variables
│ │ ├── variables.data-00000-of-00001
│ │ └── variables.index
在我们开始之前,让我们创建一个隔离的 Python 环境以在空工作区中工作,并避免任何库冲突。 安装 virtualenv,然后在 inference-graph 文件夹中打开终端,并创建并激活一个新的虚拟环境
virtualenv -p python3 venv source venv/bin/activate
pip install tensorflowjs[wizard]
启动转换向导
tensorflowjs_wizard
现在,该工具将引导您完成转换,并提供您需要做出的每个选择的解释。下图显示了转换模型时所做的所有选择。大多数是标准选择,但像分片大小和压缩之类的选项可以根据您的需求进行更改。
为了使浏览器能够自动缓存权重,建议将它们分成大约 4 MB 的分片文件。为了确保转换能够正常进行,也不要跳过操作验证,因为并非所有 TensorFlow 操作都受支持,因此某些模型可能与 TensorFlow.js 不兼容——查看 此列表以了解哪些操作当前在 TensorFlow.js 执行的各种后端(如 WebGL、WebAssembly 或纯 JavaScript)上受支持。
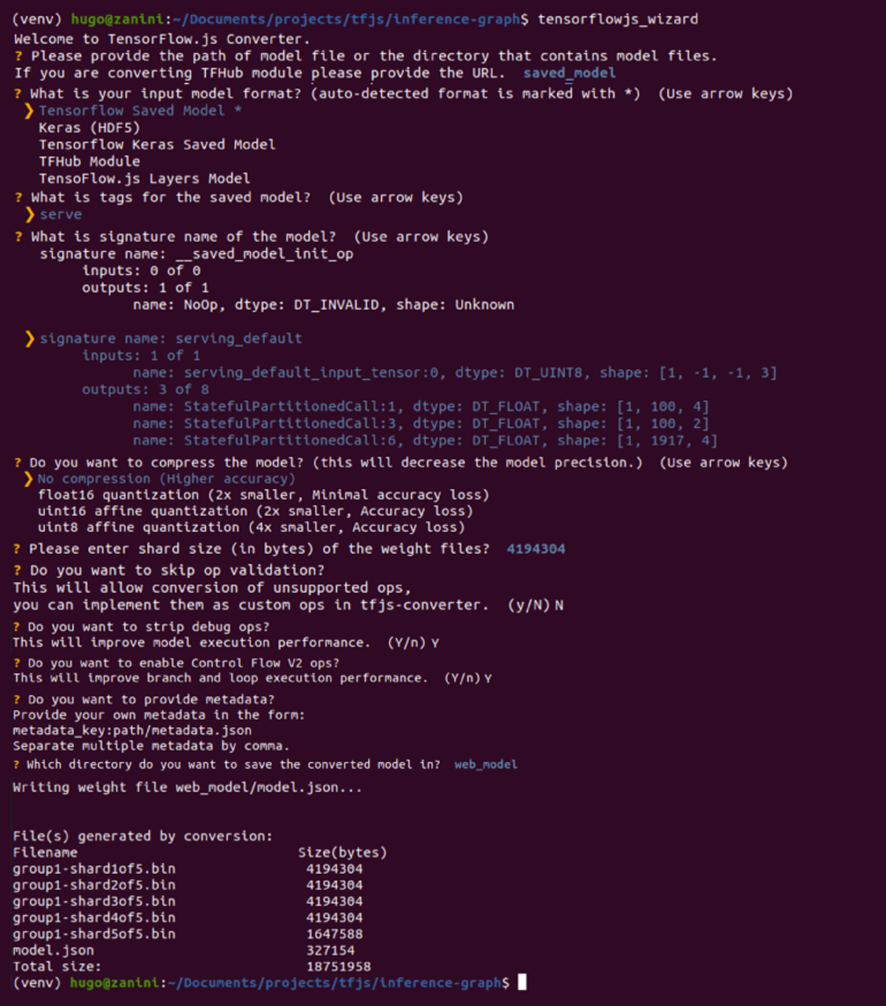
使用 TensorFlow.js 转换器进行模型转换(全分辨率图像在此) |
如果一切顺利,您将把模型转换为 TensorFlow.js 层格式,该格式位于 web_model 目录中。该文件夹包含一个 model.json 文件和一组以二进制格式分片的权重文件。model.json 既包含模型拓扑结构(也称为“架构”或“图形”:对层的描述以及它们如何连接),也包含权重文件的清单 (Lin, Tsung-Yi 等人)。web_model 文件夹的内容当前包含以下所示文件
└ web_model ├── group1-shard1of5.bin ├── group1-shard2of5.bin ├── group1-shard3of5.bin ├── group1-shard4of5.bin ├── group1-shard5of5.bin └── model.json
配置应用程序
模型已准备好加载到 JavaScript 中。我创建了一个应用程序,可以直接从浏览器执行推理。让我们 克隆仓库以了解如何在实时环境中使用转换后的模型。这是项目结构
├── models │ ├── group1-shard1of5.bin │ ├── group1-shard2of5.bin │ ├── group1-shard3of5.bin │ ├── group1-shard4of5.bin │ ├── group1-shard5of5.bin │ └── model.json ├── package.json ├── package-lock.json ├── public │ └── index.html ├── README.MD └── src ├── index.js └── styles.css
为了简单起见,我已经在模型文件夹中提供了一个转换后的 SKU 检测器模型。但是,让我们将上一节生成的 web_model 放入 models 文件夹并测试它。
接下来,安装 http-server
npm install http-server -g
转到 models 文件夹并运行以下命令,使模型在 http://127.0.0.1:8080 上可用。当您想将模型权重保存在安全的地方并控制谁可以对其进行推理请求时,这是一个不错的选择。-c1 参数用于禁用缓存,--cors 标志启用 跨域资源共享,允许托管文件被给定域的客户端 JavaScript 使用。
http-server -c1 --cors .
或者,您可以将模型文件上传到其他地方——甚至上传到其他域(如果需要)。在我的例子中,我选择了自己的 Github 仓库,并在 load_model 函数中引用了 model.json 文件夹的 URL,如下所示
async function load_model() {
// It's possible to load the model locally or from a repo.
// Load from localhost locally:
const model = await loadGraphModel("http://127.0.0.1:8080/model.json");
// Or Load from another domain using a folder that contains model.json.
// const model = await loadGraphModel("https://github.com/hugozanini/realtime-sku-detection/tree/web");
return model;
}
这是一个不错的选择,因为它为应用程序提供了更大的灵活性,并使其更易于在公共 Web 服务器上运行。
选择其中一种方法在 load_model 函数中加载模型文件(src>index.js 文件中的第 10-15 行)。
加载模型时,TensorFlow.js 将执行以下请求
GET /model.json GET /group1-shard1of5.bin GET /group1-shard2of5.bin GET /group1-shard3of5.bin GET /group1-shardo4f5.bin GET /group1-shardo5f5.bin
在 CodeSandbox 中发布
CodeSandbox 是一个用于创建 Web 应用程序的简单工具,我们可以在其中上传代码并将应用程序提供给网络上的每个人。通过将模型文件上传到 GitHub 仓库并在 load_model 函数中引用它们,我们可以简单地登录到 CodeSandbox,单击“新建项目”>“从 Github 导入”,然后选择应用程序仓库。
等待几分钟安装软件包,您的应用程序将出现在您可以与他人共享的公共 URL 上。单击“显示”>“在新窗口中”,将打开一个带有实时预览的标签页。复制此 URL 并将其粘贴到任何 Web 浏览器(PC 或移动设备)中,您的目标检测将准备就绪。如果需要,也可以找到一个可立即使用的项目在此。
结论除了精度之外,这些实验中一个有趣的部分是推理时间——一切都在浏览器中通过 JavaScript 实时运行。SKU 检测模型在浏览器中运行,即使离线,并且使用很少的计算资源,这在许多消费品包装公司应用程序以及其他行业中都是必需的。
使机器学习解决方案能够在客户端运行是确保模型在与用户的交互点有效使用、延迟最小以及在问题发生时解决问题的关键步骤:就在用户手中。
深度学习不应该昂贵,并且应该超越研究,用于现实世界中的用例,而 JavaScript 在生产部署方面非常出色。我希望本文能作为涉及计算机视觉、TensorFlow 的新项目的参考,并在 Python 和 Javascript 之间创建更轻松的流程。
如果您有任何问题或建议,可以通过 Twitter联系我。
感谢阅读!
致谢
我要感谢 Google 开发者社区,为训练模型提供了所有计算资源,以及 SKU 110K 数据集的作者,感谢他们创建和开源了本项目中使用的数据集。

2022 年 5 月 23 日 — 作者:Hugo Zanini,数据产品经理 去年,我在 如何使用 TensorFlow.js 在浏览器中训练自定义目标检测上发表了一篇文章。这引起了来自世界各地开发人员的极大兴趣,他们试图将解决方案应用于他们的个人或商业项目。在回答读者对我第一篇文章的疑问时,我发现将我们的解决方案适应…





