NVIDIA 的 Valerie Sarge、Shashank Verma、Ben Barsdell、James Sohn、Hao Wu 和 Vartika Singh 的客座文章

推荐系统在几乎所有你能想到的地方都个性化了我们的体验。它们可以帮助你在周六晚上选择一部电影,或者在你循环播放你最喜欢的播放列表太多次时发现一位新艺术家。它们是深度学习最重要的应用之一,但就目前而言,推荐系统仍然是加速最具挑战性的模型之一,因为它们对数据的要求很高。这不仅意味着要加快推理速度,还要加快训练工作流程,以便开发人员能够快速迭代。在本文中,我们将讨论在实践中推荐系统工作负载通常会遇到的瓶颈,以及如何识别和缓解这些瓶颈。
NVIDIA GPU 擅长处理并行计算,并且在计算机视觉 (CV) 或自然语言处理 (NLP) 等深度学习领域取得了成功,在这些领域,计算本身通常是吞吐量的决定性因素,与将数据本身带到模型所需的时间相比。但是,现代推荐系统往往是内存和 I/O 绑定,而不是计算绑定。
现代推荐系统可能拥有数百个特征,其中许多是类别特征,基数可以达到数亿之多!例如,考虑一个“用户 ID”特征。不难想象有数亿个不同的用户。有时,累积的 嵌入 表可能变得非常大,以至于难以容纳在一个 GPU 的内存中。此外,这些大型嵌入表涉及纯粹的内存查找,而深度神经网络本身的内存占用可能要小得多。
话虽如此,NVIDIA GPU 技术的最新进展,特别是越来越大的 GPU 内存和更高的内存带宽,正在逐渐使 GPU 成为加速推荐系统的更好选择。例如,NVIDIA A100 GPU 80GB 拥有 80GB HBM2 内存,带宽为 2.0TB/s,而 CPU 内存的带宽仅为数十 GB/s。这除了一个 40MB L2 缓存,它提供了高达 6TB/s 的读取带宽!
在实践中,你可能会发现推荐系统往往会低效利用 GPU,因为它们通常受到主机到设备内存传输瓶颈的限制。从 CPU 内存读取到 GPU(反之亦然)代价昂贵!因此,避免 CPU 和 GPU 之间频繁的数据传输应该有助于提高性能。然而,许多与推荐系统相关的 TensorFlow 操作没有 GPU 实现,这导致了 CPU 和 GPU 之间不可避免的来回数据传输。此外,在典型的推荐系统模型中,计算负载本身通常很小,与 NLP 或 CV 模型相比,训练往往会被数据加载所拖延。
深度学习应用程序性能可能受到训练工作的一个或多个部分的限制,例如输入数据管道(例如数据加载和预处理)、计算密集型层,以及内存读取和写入。TensorFlow 剖析器 及其跟踪查看器(显示 CPU 和 GPU 事件的时间轴)可以帮助你识别性能瓶颈。
下图显示了在 TensorFlow 2.4.3 中使用合成数据训练 Wide & Deep (W&D) 模型 的跟踪查看器截图。
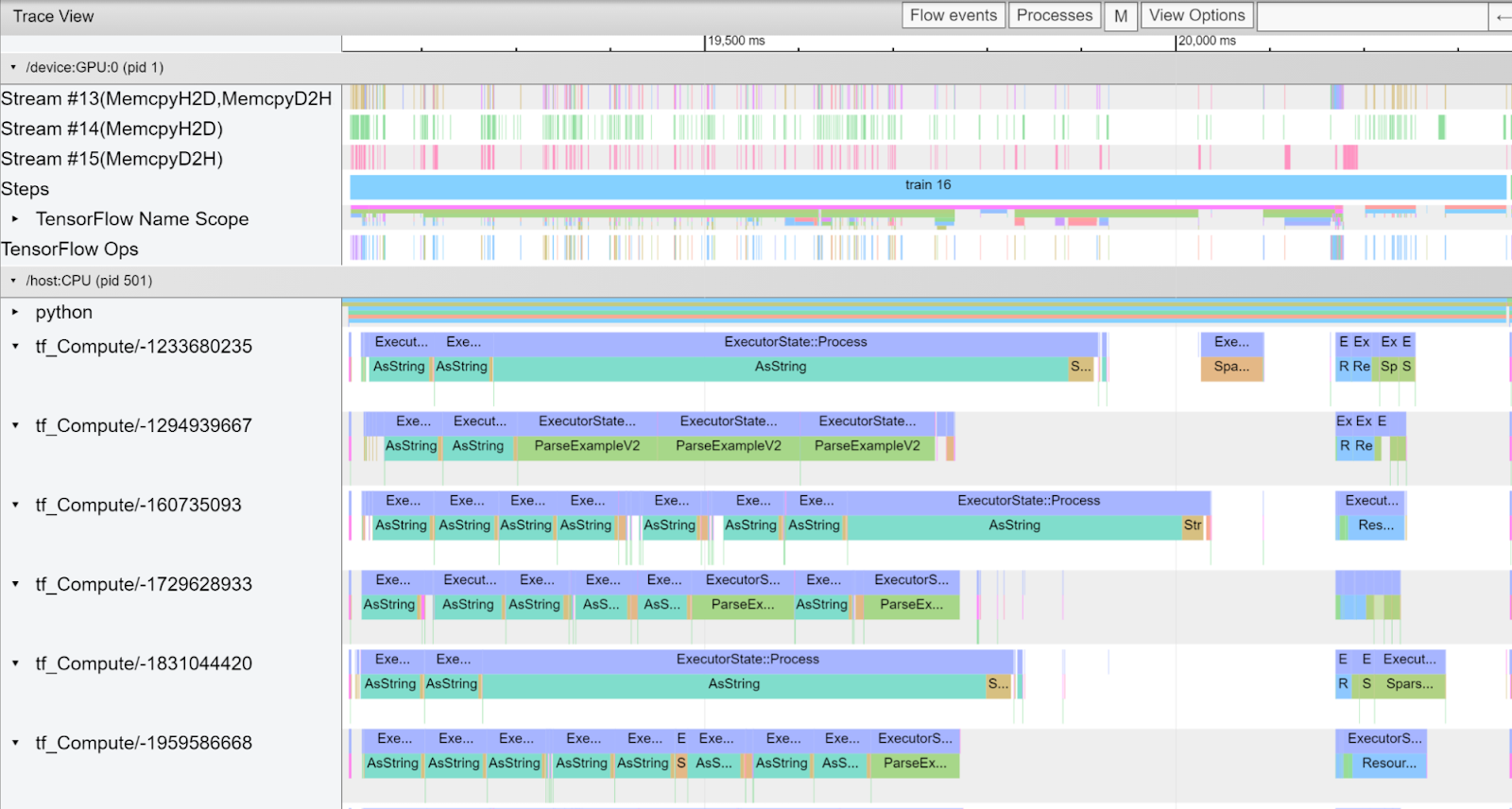 |
| 图 1:在 TensorFlow 2.4.3 中使用合成数据训练 W&D 模型的跟踪。 |
在这个截图中,我们可以看到,一些类型的操作导致了 CPU 上的大部分训练时间。一些名称被截断了,但包括
你可能还会注意到,在这个配置文件中有很多小的内存复制,请参见图 1 流 #14(MemcpyH2D)和流 #15(MemcpyD2H)。在 DenseFeatures 和 embedding_lookup_sparse 的核心,像 ResourceGather 这样的操作会从嵌入表中获取所需的权重。这里 ResourceGather 在 GPU 上执行,但它之前的操作和之后的操作只有 CPU 实现,因此数据会在 CPU 和 GPU 之间来回复制。这种传输受 PCIe 带宽的限制,通常比 GPU 内存带宽慢一个数量级。此外,虽然大多数单个复制都很小,但每次启动都需要时间,因此它们的总时间可能是相当长的。
为了加速在图 1 中 CPU 上执行的 SparseSegmentMean 和 Unique 等操作,并减少由此产生的复制花费的时间,TensorFlow 2.7 为嵌入函数使用的许多操作(如)提供了 GPU 实现。
几个新的 GPU 内核利用 CUDA CUB 库来加速 GPU 原语(如扫描和排序),这些原语是稀疏索引计算所需的。最密集的操作,SparseSegmentMean 和 SparseSegmentMeanGrad,使用自定义 GPU 内核来执行矢量化加载和存储,以最大限度地提高内存吞吐量。
现在,让我们来看看这些改进在实践中的意义。
让我们比较基于 Wide & Deep 架构的模型的训练运行,分别使用 TensorFlow 版本 2.4.3-GPU(在上述 GPU 稀疏操作实现之前最新的版本)和版本 2.7.0-GPU(第一个包含所有这些 GPU 操作的版本)。该模型包括 1 个二进制标签、10 个数值特征和 40 个类别特征(其中 3 个是 10-hot,其他是 1-hot)。
在以下基准测试套件中,一些类别特征可以为每个数据点取多个值(即它们是“多热”的)。例如,在电影推荐用例中,一个“历史记录”特征可以是用户先前观看过的电影列表。相比之下,一个单热特征只能取一个值。在本帖的其余部分,术语“n-hot”表示可以取最多 n 个值的“多热”类别特征。总的来说,模型中所有特征的嵌入表为 9.1 GB。对于这些特征,使用了 身份类别列,除非基准测试说明了其他情况。
模型的宽部分使用 keras.layers.Embedding,深部分使用 keras.layers.DenseFeatures。这些训练运行使用从 TFRecord 文件读取的合成数据(在“加速数据加载”中描述),批次大小为 131,072,使用 SGD 优化器。性能数据记录在一个系统上,该系统配备了一个 NVIDIA A100-80GB GPU 和 2 个 AMD EPYC 7742 64 核 CPU @ 2.25GHz。
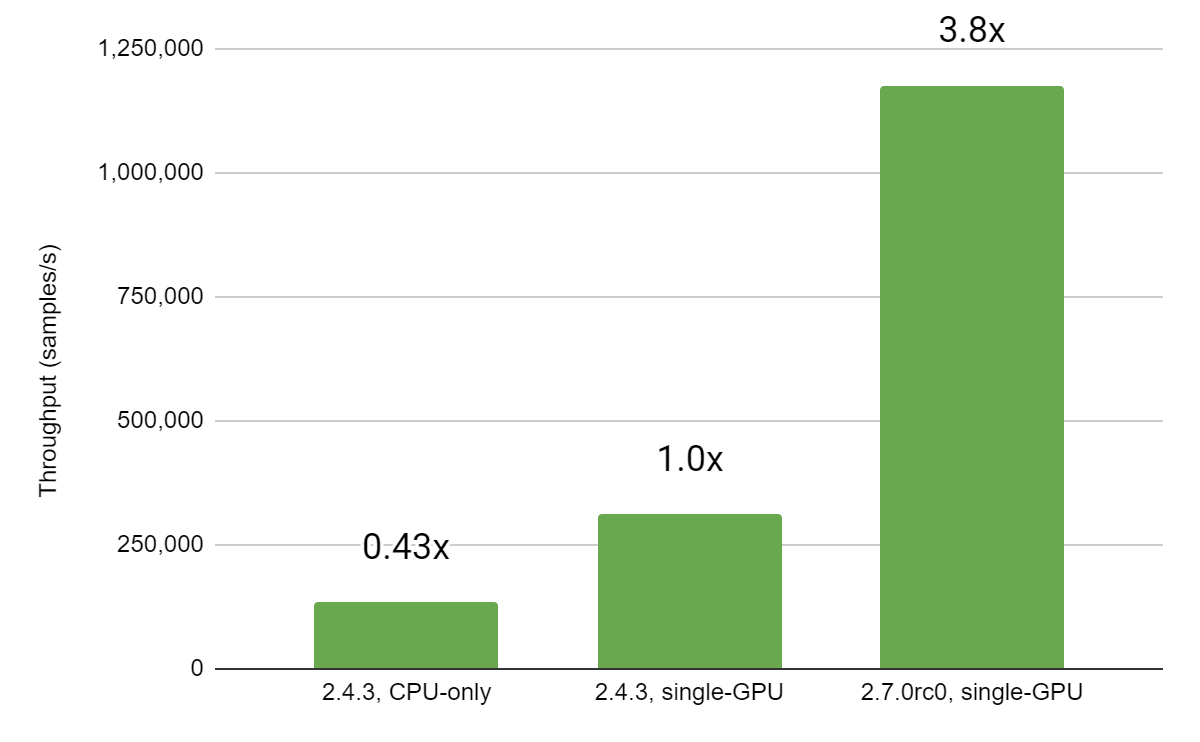 |
| 图 2:训练吞吐量(以样本/秒为单位) |
从上面的图中可以看出,从 TF 2.4.3 到 TF 2.7.0,我们观察到训练步骤减少了约 **73.5%**。这相当于在 NVIDIA A100-80GB 上的训练速度提高了大约 **3.77 倍**,仅仅是升级到 TF 2.7.0!让我们仔细看看使这种改进成为可能的更改。
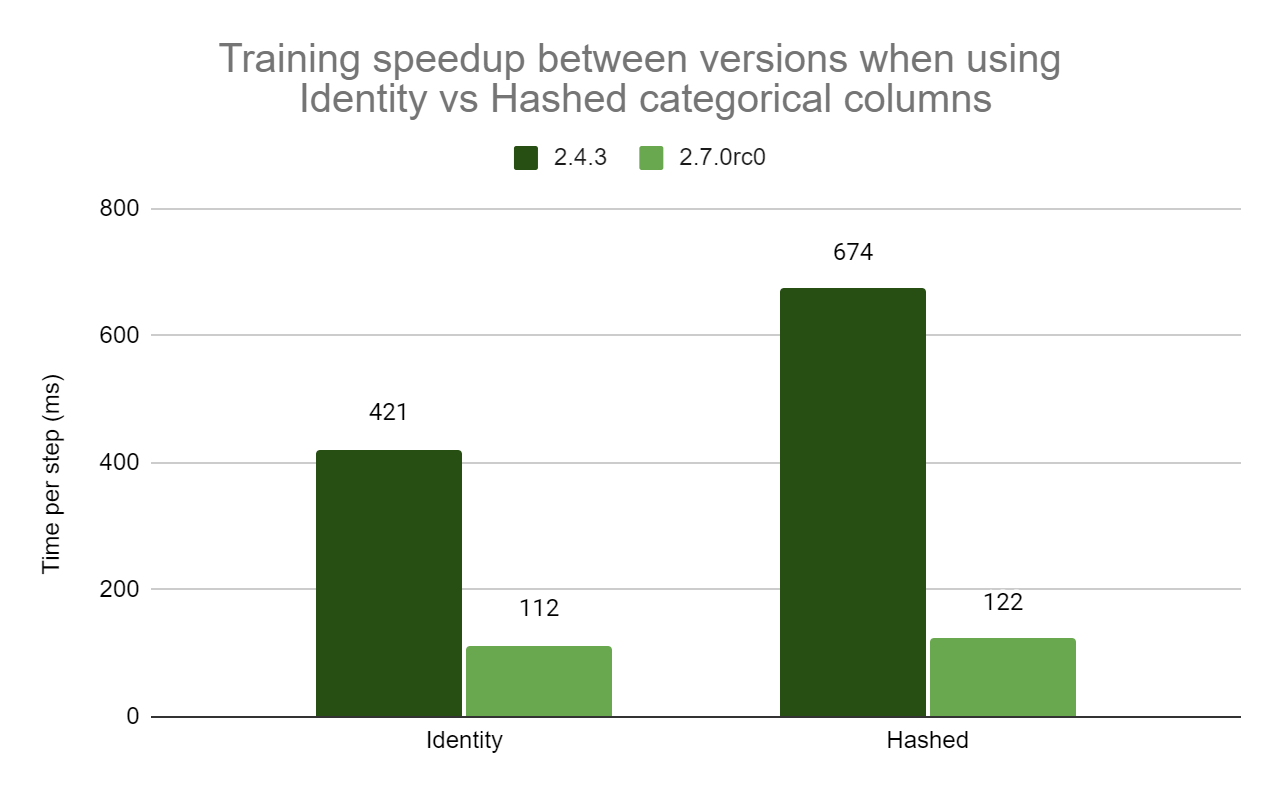 |
| 图 3:在测试模型中使用纯身份类别列(3.77 倍)和纯哈希类别列(5.55 倍)时,不同版本之间的训练步骤时间加速。由于一个新的 GPU 整数哈希操作,哈希类别列显示出额外的加速。 |
身份 和 哈希 类别列都从新的 GPU 内核中受益。由于这些操作中的许多以前是在 CPU 上并行执行的,因此很难量化每个操作的加速,但这些新的内核共同是性能改进的主要原因。
哈希类别列还受益于一个新的 GPU 操作(TensorToHashBucket),它在 Grappler 传递中取代了以前在 AsString + StringToHashBucketFast 哈希方法。这些操作以前非常耗时,因此使用哈希类别列的测试模型在训练步骤时间方面显示出更大的改进。
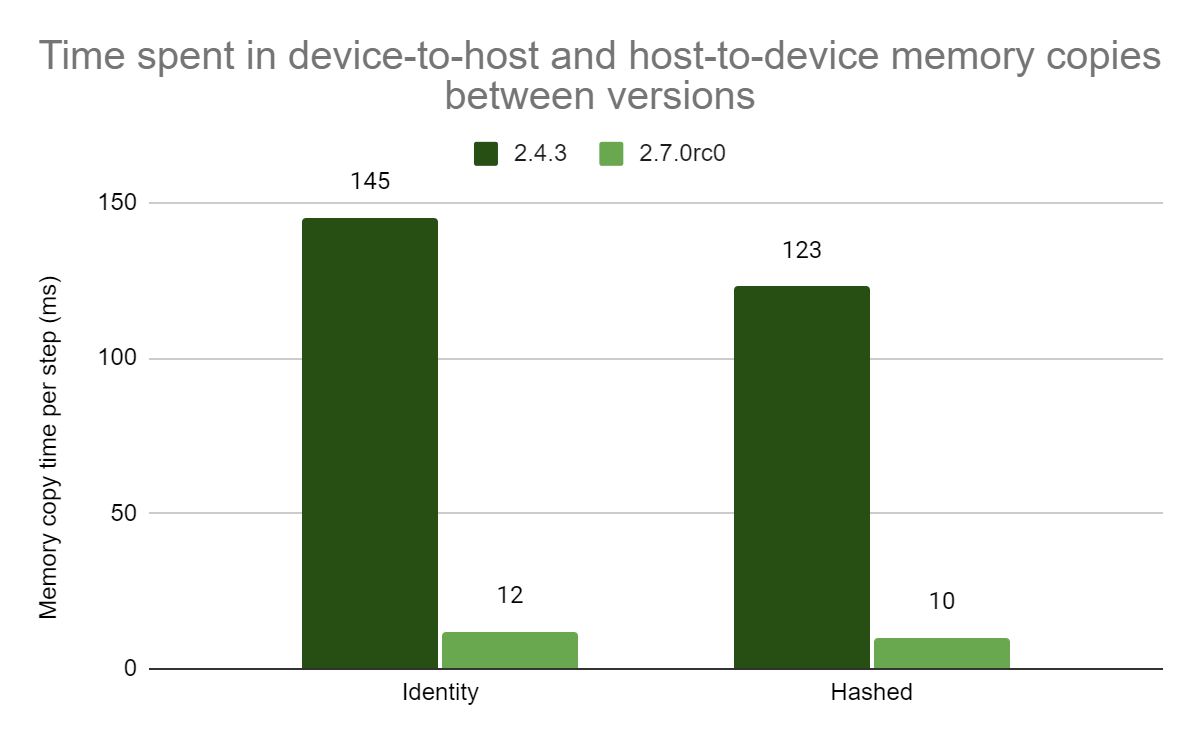 |
| 图 4:设备到主机和主机到设备内存复制所花费时间的比较。在 TensorFlow 2.7.0 中为操作提供 GPU 内核,通过避免额外的复制来节省时间。 |
除了 GPU 内核本身带来的加速之外,通过执行更少的数据复制还可以节省一些时间。我们之前提到,当在 GPU 上放置的操作后面跟着在 CPU 上放置的操作,反之亦然时,需要额外的主机到设备和设备到主机复制。图 4 显示了通过将更多操作放置在 GPU 上,在复制方面所花费的时间大幅减少。
推荐系统训练经常受到从磁盘加载数据的速度的限制。以下是三种常见的识别数据加载瓶颈的方法
在之前的示例中,我们从一组 TFRecord 文件读取数据,这些文件已经将我们的合成输入数据预先整理成批次,以避免受到数据加载的限制(因为这会难以看到新变化带来的加速效果,而这些变化影响的是网络本身的运算)。在 TFRecord 文件中,通常每组输入都存储为单独的条目,批次是在加载和混洗数据后构建的。对于具有许多小特征的数据集,这会消耗大量的磁盘空间,因为每个条目都是单独存储和标记的。例如,我们的测试模型有一个二元标签,10 个数值特征和 40 个分类特征(三个 10-hot 和其余 1-hot)。此模型数据 TFRecord 中的每个条目都包含每个数值特征的一个浮点值,以及每个分类特征的适当数量的整数值。大约 400 万个输入的数据集以这种基本格式存储在磁盘上,占用 4.1GB 空间。
现在考虑一个记录文件,其中每个条目包含此模型的整个批次 131,072 个输入(因此,对于每个数值特征,条目将包含 131,072 个序列化浮点值)。使用这种格式,相同的数据集 400 万个输入只需要 803MB 的磁盘空间,训练速度提高了 7 倍以上。
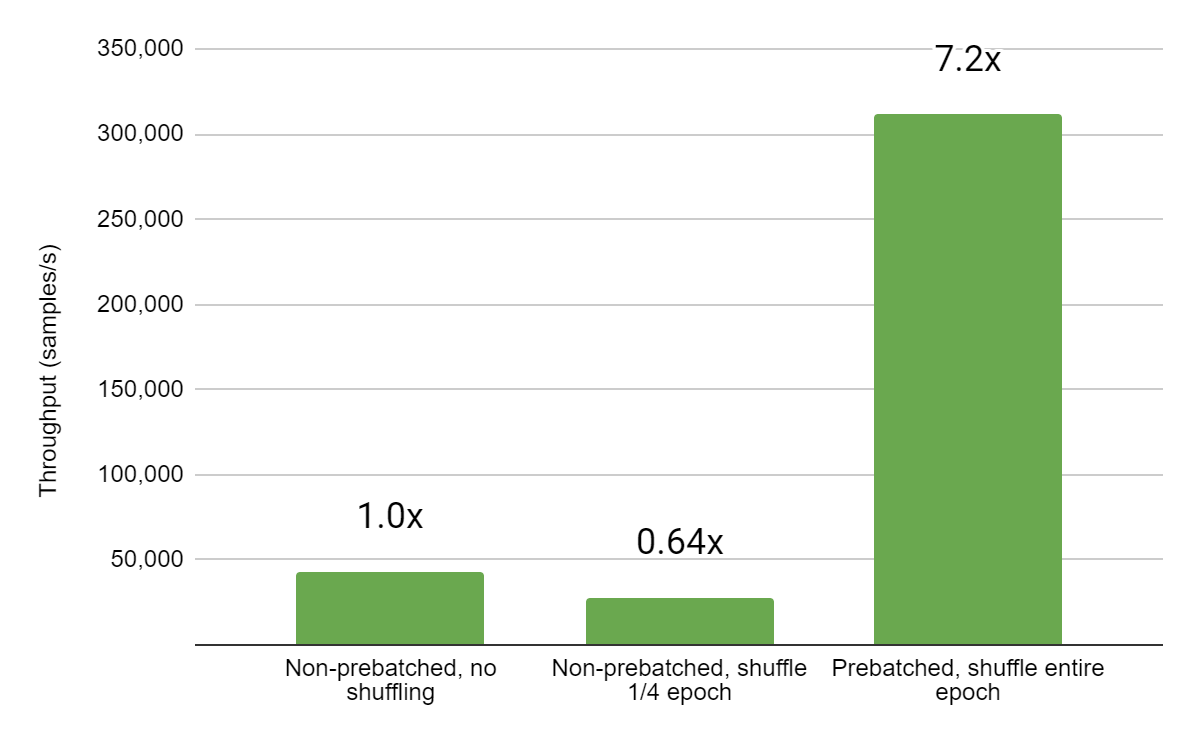 |
| 图 5:在对输入 TFRecord 数据集进行预批处理后,训练步骤的速度提高了 7 倍以上。虽然使用非预批处理输入可以进行更彻底的混洗,但与混洗预批处理输入批次的顺序相比,开销非常大。 |
根据数据工程管道的设置方式,可能需要添加一个组件来创建预批处理数据。预批处理数据的副作用是,批次大小和内容在写入 TFRecord 时很大程度上是预定义的。可以解决这些限制(例如,通过连接来自文件的多个批次来增加训练时的批次大小),但可能会损失一些灵活性。
推荐系统的规模和范围增长迅速,在 TB 级别看到推荐模型并不罕见(例如,Google 的 1.2TB 模型)。另一个可以加速 NVIDIA GPU 上推荐器训练的有效选项,特别是在多 GPU 和多节点规模下,是 TF 自定义嵌入插件。这个基于 CUDA 的插件将大型嵌入表分布到多个 GPU 和节点,以便开箱即用地进行模型并行多 GPU 训练。它作为 TF 原生嵌入层的 GPU 插件增强,例如 tf.nn.embedding_lookup 和 tf.nn.embedding_lookup_sparse。在 TensorFlow 2.5 及更高版本中,使用具有 100 个 10-hot 分类特征的模型,单个 NVIDIA A100 GPU 基准测试显示,使用 TF 自定义嵌入插件,平均训练迭代时间提高了 7.9 倍,在四个 NVIDIA A100 GPU 上,加速效果提高到 23.6 倍。查看 这篇文章,了解此插件的概述和更多信息。
推荐器对加速来说是一个具有挑战性的工作负载。NVIDIA GPU 技术的进步,包括越来越大的内存、内存带宽和强大的并行计算能力,极大地有利于现代大规模推荐系统。
我们在 TensorFlow 中添加了几个以前没有 GPU 实现的运算的 GPU 实现,极大地提高了训练时间,从而减少了数据科学家可能花费在实验和创建推荐模型上的时间。此外,还可以通过 TF 自定义嵌入插件来加速 NVIDIA GPU 上的嵌入层。





