作者:Zu Kim 和 Louis Romero,谷歌研究院软件工程师
基于检索的分类提供了一种简单的方法,无需通过反向传播进行计算量大的训练,即可创建基于神经网络的分类器。使用这项技术,您只需每个类别一张图片即可创建轻量级移动模型,或者您也可以创建一个能够分类多达数万个类别的设备上模型。例如,我们使用基于检索的分类技术创建了 能够识别数万个地标的移动模型。
基于检索的分类有许多用例,包括
分类和检索是图像识别的两种截然不同的方法。典型的目标识别方法是构建一个神经网络分类器,并使用大量训练数据(通常是数千张甚至更多的图像)对其进行训练。相反,检索方法使用预训练的特征提取器(例如,图像嵌入模型),并根据最近邻搜索算法进行特征匹配。检索方法具有可扩展性和灵活性。例如,它可以处理大量类别(例如,> 100 万),添加或删除类别不需要额外的训练。每个类别只需一个训练数据即可,这使得它实际上是少次学习。检索方法的一个缺点是它需要额外的基础设施,并且不如分类模型直观。您可以阅读有关现代检索系统的文章,了解 TensorFlow Similarity。
基于检索的分类 (CbR) 是一种神经网络模型,将图像检索层嵌入其中。使用 CbR 技术,您可以轻松创建 TensorFlow 分类模型,无需任何训练。
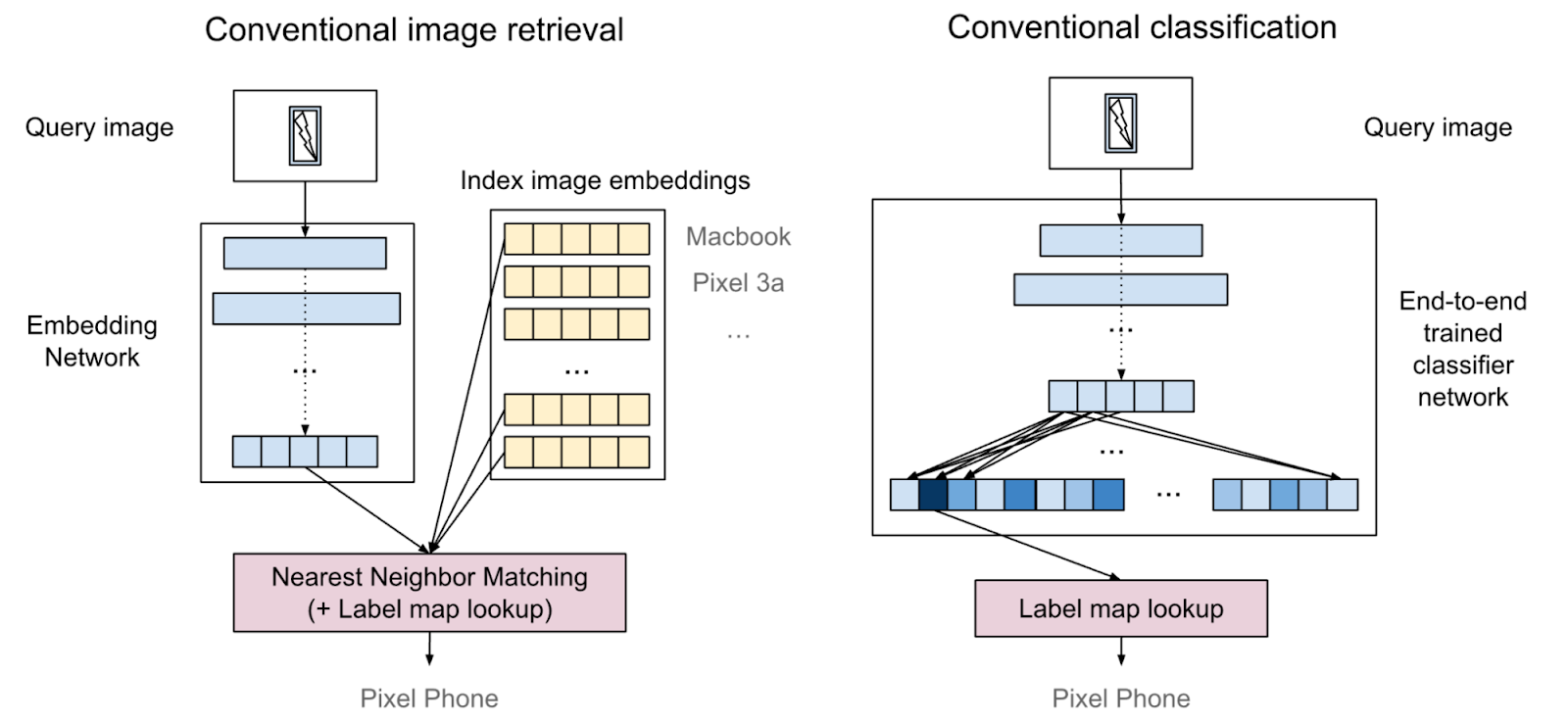 |
| 一张描述传统图像检索和传统分类的图片。传统图像检索需要特殊的检索基础设施,而传统分类需要使用大量数据进行昂贵的训练。 |
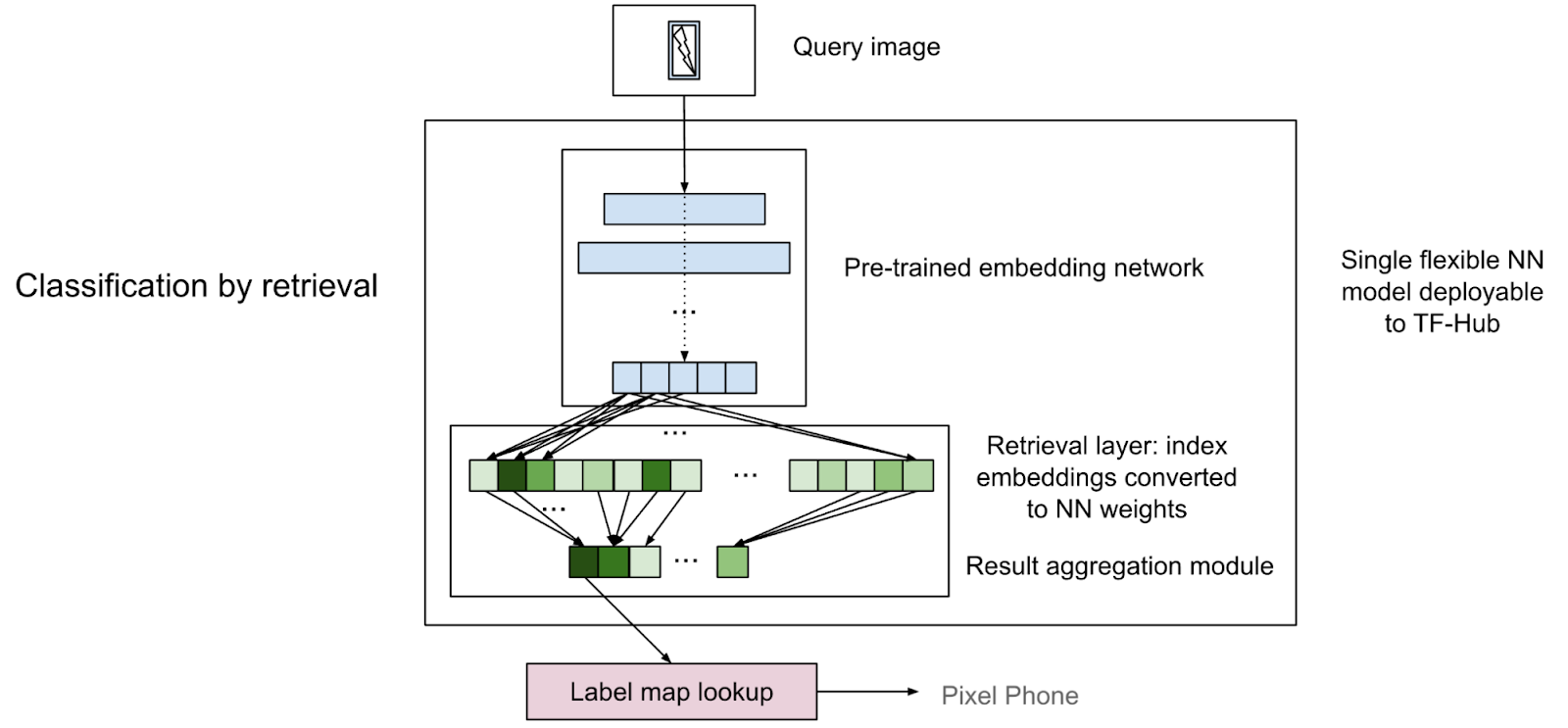 |
| 一张描述基于检索的分类如何与预训练的嵌入网络和最终检索层组合的图片。它无需昂贵的训练即可构建,并且在推理时不需要特殊的基础设施。 |
基于检索的分类模型是嵌入模型的扩展,带有额外的检索层。检索层是从训练数据(即索引数据)计算的(而不是训练的)。检索层由两个部分组成
最近邻匹配组件本质上是一个全连接层,其权重是索引数据的归一化嵌入。请注意,两个归一化向量的点积(余弦相似度)与平方 L2 距离呈线性关系(具有负系数)。因此,全连接层的输出实际上与最近邻匹配结果相同。
检索结果是针对每个训练实例,而不是每个类别给出的。因此,我们在最近邻匹配层之上添加了另一个结果聚合组件。聚合组件包含每个类别的选择层,然后是每个类别的聚合(例如,最大)层。最后,将结果连接起来形成一个单一的输出向量。
您可以选择最适合该领域的基嵌入模型。有许多嵌入模型可用,例如,在 TensorFlow Hub 中。提供的 iOS 演示 使用 使用 ImageNet 训练的 MobileNet V3,这是一个通用且高效的设备上模型。
在某种意义上,CbR(索引)可以被视为一种无需训练的少次学习方法。虽然将 CbR 与具有任意预训练基嵌入模型的典型少次学习方法进行比较并不完全相同,在典型少次学习方法中,整个模型使用给定训练数据进行训练,但有一项 研究 将最近邻检索(等同于 CbR)与少次学习方法进行了比较。结果表明,最近邻检索可以与许多少次学习方法相媲美,甚至更好。
代码可在 https://github.com/tensorflow/examples/tree/master/lite/examples/classification_by_retrieval/lib 中获取。
为了演示基于检索的分类库的易用性,我们构建了一个移动应用程序,允许用户选择其照片库中的相册作为输入数据,以创建新的、量身定制的图像分类 TFLite 模型。无需编码。
 |
| iOS 允许用户通过选择其库中的相册来创建新模型。然后,该应用程序允许他们在实时摄像头馈送上试用分类模型。 |
我们鼓励您使用这些工具来构建公平且负责任的模型。要了解有关构建负责任模型的更多信息
我们将探索基于这项工作的可能方法,以扩展 TensorFlow Lite 模型制作器,以实现设备上训练功能。
许多人对这项工作做出了贡献。我们要感谢 Maxime Brénon、Cédric Deltheil、Denis Brulé、Chenyang Zhang、Christine Kaeser-Chen、Jack Sim、Tian Lin、Lu Wang、Shuangfeng Li 以及参与该项目的每个人。






