作者 Christian Sager(产品所有者,Digitec Galaxus)和 Anant Nawalgaria(机器学习专家,Google)

零售行业很重要的能够通过大规模向时事通讯中提供个性化内容来吸引和激发用户积极性。重要的是要利用现有趋势来做到这一点,同时探索并挖掘可能具有更高用户参与度的潜在新趋势。这个项目由 Digitec Galaxus 和 Google 合作完成,通过设计一个基于Contextual Bandits的系统,为每周超过 200 万用户个性化时事通讯。
为了实现这一目标,我们在 TensorFlow 生态系统和 Google Cloud 中利用了多项产品,包括 TF-Agent、TensorFlow Extended (TFX)(在 Vertex AI 上运行),构建了一个系统,以可扩展、模块化、经济高效且低延迟的方式实现时事通讯个性化。在本文中,我们将重点介绍其中某些部分,并向您提供可用于了解详情的资源。
Digitec Galaxus AG 是瑞士最大的在线零售商。它为其客户供应各种产品,从电子产品到服装。作为在线零售商,我们自然会使用推荐系统,不仅在我们的主页或产品页面上,而且还在我们的时事通讯中。我们已经为时事通讯提供多个推荐系统,并且一直积极 采用 Google Cloud 推荐 AI。由于我们有大量的推荐系统和数据,因此面临以下复杂性。
1. 个性化
我们有超过 12 个推荐系统在时事通讯中使用,但是我们希望通过为不同的用户选择不同的推荐系统(它们反过来选择商品)来设置这些推荐系统的上下文。此外,我们希望利用现有趋势并尝试新的趋势。
2. 延迟
我们希望确保可以以低于 50 毫秒的延迟检索到推荐人的排名列表。
3. 易于维护且可推广/模块化架构的端到端架构
我们希望该解决方案采用易于维护且与平台无关的方式构建架构,并具有训练和使用上下文多臂老虎机模型所需的所有 MLops 功能。对我们来说,以模块化方式构建该解决方案也很重要,以便可以轻松地将其调整为其他用例,例如主页上的推荐、智能标签等。
在详细介绍我们如何建立一个能够满足所有要求的机器学习基础架构之前,我们将详细了解我们如何做到这一点,以及我们要解决的问题。
Digitec Galaxus 已有多个推荐系统。由于我们有大量的推荐系统,因此有时很难以个性化方式在它们之间进行选择。因此我们向 Google 寻求寻求帮助,以实施上下文多臂老虎机驱动的推荐,它可以对我们的主页和时事通讯进行个性化。由于我们只向注册用户发送时事通讯,因此我们可以为每个用户添加功能。
我们选择了 TFAgents 来实施 上下文多臂老虎机 模型。训练和服务管道由 Vertex AI 渠道编制,该渠道运行 TFX,后者 wiederum 使用 TFAgents 来开发上下文多臂老虎机模型。以下是对我们方法的概述。

奖励订阅,并处罚取消订阅
根据有关用户的某些特征(上下文)以及 12 个可用推荐人中的每一个,我们旨在建议最佳推荐人(操作),它会增加用户点击所选推荐人的至少一个推荐(奖励 = 1)的机会(奖励),并且最大限度地减少导致取消订阅的点击次数(奖励 = -1)。
通过以这种方式制定问题和奖励函数,我们假设系统将优化以增加点击次数,同时仍然向用户显示相关(且不是点击诱饵)内容,以维持潜在的性能提升。这是因为当用户取消订阅时,奖励函数会对事件进行处罚,而点击诱饵内容很可能会导致这种情况。当时通过使用 上下文多臂老虎机 来解决问题,因为它们擅长利用行之有效的方法,同时探索并发现性能更好的方法。
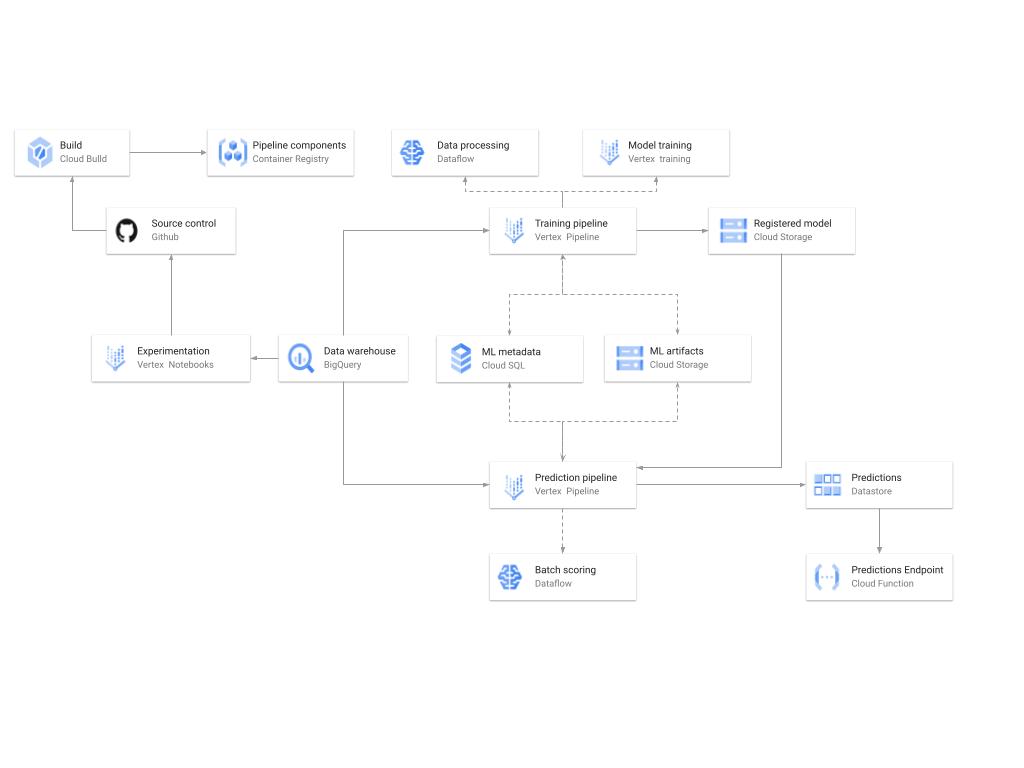 |
| 一张显示 GCP 上建议训练和预测系统的高级架构的图表。 |
这里有很多细节,因为图表中所示的架构涵盖了机器学习开发、训练和服务的三个阶段。以下是一些关键部分。
模型开发
除实施模型训练和评分组件和渠道外,Vertex Notebooks 还用作数据科学环境进行实验和原型设计。源代码在 GitHub 中进行版本控制。建立了一个持续集成 (CI) 渠道来运行单元测试、构建渠道组件并将容器映像存储到 Cloud Container Registry.
训练
训练管道在 Vertex Pipelines 上使用 TFX 执行。实质上,该管道使用从 BigQuery 中提取的新训练数据来训练模型,验证生成的模型并将该模型存储在模型注册表中。在我们的系统中,模型注册表在 Cloud Storage 中进行组织。训练管道使用 Dataflow 进行大规模数据提取、验证、处理和模型评估,以及 Vertex Training 进行模型的大规模分布式训练。此外,AI Platform Pipelines 将各个管道步骤生成的编译工件存储到 Cloud Storage,并且有关这些编译工件的信息存储在 Cloud SQL 中的 ML 元数据数据库中。
提供服务
使用批处理预测管道生成预测,并存储在 Cloud Datastore 中以便使用。批处理预测管道是使用 TFX 制作的,并且在 Vertex Pipelines 上运行。该管道使用模型注册表中的最新模型对来自 BigQuery 的提供服务查询进行评分。Cloud Function 以 REST/HTTP 终结点形式提供,以便从 Datastore 检索预测。
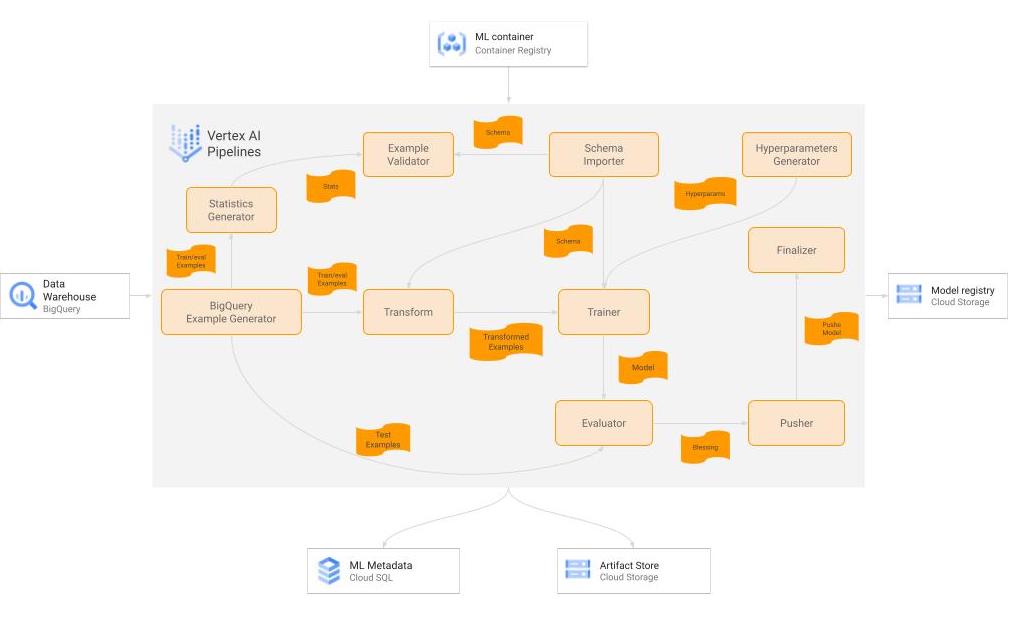 |
| 面向训练工作流的 TFX 管道的图表。 |
我们的基于 TFX 的持续培训工作流中使用了许多组件,培训目前按需进行,但以后计划每两周执行一次。以下是有关重要组件的一些详细信息。
原始数据
我们的数据由存储在 BigQuery 表格和其他格式中的异构格式中的多个数据集组成,然后由客户以非规范化方式将其连接到单个 BigQuery 表格中进行培训。为了帮助避免模型中出现偏差和漂移,我们对 4 周滚动窗口进行模型训练,每个训练周期重叠一周。这是一个简单的设计选择,因为实施非常简单,因为 BigQuery 作为 TFX 的源具有良好的兼容性,并且还允许用户在获取时执行一些基本的数据预处理和清理操作。
BigQueryExampleGen
我们首先利用 BigQuery 利用内置函数预处理数据。通过将我们自己的特定过程嵌入到 ExampleGen 组件发出的查询调用中,我们能够避免构建独立于 TFX 管道范围之外的单独 ETL。这最终被证明是一种在生产中更快速地获取模型的好方法。然后通过 ExampleGen 组件将此预处理数据拆分为训练和评估数据并转换为 tf.Examples。
转换
此组件执行为处理字符串、填补缺失值、对数标准化值、设置嵌入等必要的特征工程和转换。此处的主要好处是最终将所得的转换置于计算图之前,从而在训练和服务中使用完全相同的代码。Transform 组件在生产中于 Cloud Dataflow 上运行。
训练器
训练器组件使用 TF-Agents 训练模型。我们利用 Vertex Training 上的并行训练加快速度。模型的设计为:用户 ID 从输入传递至输出保持不变,以便将其用作下游服务管道的一部分。训练器组件在生产中于 Vertex Training 上运行。
评估器
评估器将现有的生产模型与通过训练器接收到的模型进行比较,并准备验证器组件所需要的指标以认可生产中“更好的”模型。模型验证标准基于 AUC 得分、反事实政策评估以及未来可能出现的其他指标。由于评估器组件具有可扩展性,因而易于实现符合业务要求的自定义指标。评估器在 Vertex AI 上运行。
推动器
推动器的主要功能是将认可的模型发送到我们的 TFServing 部署以进行生产。但是,我们增加了使用评估器中产生的自定义指标的功能以确定服务中要使用的决策标准,并将其附加到计算图。TFX 组件中提供的抽象级别使此自定义修改变得容易。总体而言,此修改允许流水线在没有循环参与的情况下操作,以便我们能够频繁更新模型,同时继续在对我们的业务很重要的指标上提供一致的性能。
超参数生成器
这是一个自定义 TFX 组件,它创建一个带有超参数(例如,批大小、学习率)的字典,并将该字典存储为一个工件。超参数作为输入传递到训练器。
服务模型解析器
此自定义组件采用服务策略(包括勘探)和一个相应的评估策略(不含勘探),并确定将在服务中使用哪个策略。服务标准基于 AUC 得分、反事实策略评估以及未来可能出现的其他指标。
推送_最终确定器
此自定义组件将推入/认可的模型从 TFX 工件目录复制到经过整理的目的地。
TFX 中开箱即用的组件提供了我们所需的大部分功能,很容易创建一些新的自定义组件,以使整个流水线满足我们的要求。该管道还有其他组件,例如 StatisticsGen(它也在 Dataflow 上运行)。
 |
| 展示用于批量预测工作流程的 TFX 管道的图表。 |
以下是我们的批量预测系统中的一些关键部分。
推理数据集
我们的推理数据集的格式几乎与训练数据集相同,只不过它会清空并每天使用新数据重新填充。
BigQueryExampleGen
就像训练管道一样,我们使用该组件从 BigQuery 中读取数据并将其转换成 tf.Examples。
模型导入程序
该组件导入训练管道中 Pusher 组件导出的计算图。如上所述,由于它包含了训练管道生成的整个计算图,包括特征转换和 tf.Agent 模型(包括探索/利用方面),因此它非常便携,可以防止训练/测试偏差。
BulkInferrer
如名称所述,该组件使用导入的计算图对推理数据集执行大规模推理。它在生产环境中使用 Cloud Dataflow 运行,使其非常容易进行扩展。
PredictionStorer
这是一个自定义 Python 组件,它从 Bulkinfererrer 获取推理结果,对结果进行后处理,按照要求格式化/过滤字段,并将其持久保存到 Cloud Datastore。它也使用 Cloud Dataflow 在生产环境中运行。
服务通过云函数实现,其使用用户 ID 作为输入,并返回 DataStore 中存储的每个 userId 的预计算结果,延迟低于 50 毫秒。
在实施第一个版本以来的几个月里,我们对管道进行了许多改进,从更改原始模型的架构/方法,到更改模型结果在用于生成时事通讯的下游应用程序中的使用方式。此外,这些改进中的每项都能比过去更快地为我们带来新的价值。
自最初实施此参考架构以来,我们已经发布了一个简单的 Vertex AI 管道基础 github 代码样本,用于使用 TF Agent 实施推荐系统 在此处。通过使用此模板和指南,它将帮助他们在 GCP 上构建基于上下文赌徒的推荐系统,这种推荐系统既可扩展又模块化,而且延迟低,且成本效益高。令人惊讶的是,我们在已经部署了许多 TFX 组件,这些组件甚至可以移植到新项目中,更重要的是,它极大地缩短了将模型投入生产所需的时间。因此,即使我们团队中那些没有多少机器学习专业知识的软件工程师也有信心能够重复使用此架构并将其调整为更多用例。数据科学家能够花更多时间优化他们制作模型的参数和架构、理解它们对业务的影响,并最终为用户和业务提供更多价值。
如果没有以下 Google 员工的共同协作,这一切都不可能实现:Khalid Salama、Efi Kokiopoulou、Gábor Bartók 和 Digitec Galaxus 的工程师团队。
您可以在 此处 找到这篇关于此项目的 Google Cloud 博客。






