作者: Gábor Bartók 和 Efi Kokiopoulou,Google Research
本文假设您对强化学习和/或多臂老虎机有一定的了解。如果您是初学者,一个好的起点是 Bandits 维基百科词条,或者想要更技术性和更深入的介绍,可以参考 这本书。
在本博文中,我们将介绍 TensorFlow-Agents Bandits 库。该库提供了最流行的 bandit 算法的综合列表,以及可以在其上运行算法的各种测试问题。测试问题(称为 bandit 环境)包括一些合成环境,以及从现实生活(分类或推荐)数据集中转换的环境。
其中一个例子是 MovieLens 环境,它利用了这个 数据集。在本博文中,我们将借助 MovieLens 环境指导您使用 TF-Agents Bandits 库。
多臂老虎机是一种机器学习框架,其中代理反复从一组动作中选择动作,并通过与环境交互来收集奖励。代理的目标是在给定的时间范围内积累尽可能多的奖励。术语“老虎机”来自一个说明性的例子:从一组具有不同回报的机器中找到最好的老虎机(单臂老虎机)。这些动作也被称为“臂”。
 |
| 来自 维基百科 的图片 |
还有两个重要的概念需要了解:“上下文”和“后悔”。在许多现实生活场景中,找到平均提供最高回报的最佳动作是不够的:我们希望根据情况/上下文找到最佳动作。为了在这个方向上扩展 bandit 框架,我们引入了“上下文”的概念。在代理必须选择动作之前,它会收到提供有关当前回合信息的上下文。然后,代理的目标是找到一个策略,该策略为给定的上下文选择回报最高的动作。
在 bandit 文献中,“后悔”的概念非常重要。后悔可以非正式地定义为最优策略和学习策略之间的性能差异。通常,性能是用累积奖励(即跨多个回合的奖励总和)来衡量的;否则,人们也可以提到“瞬时后悔”,即代理在特定回合遭受的后悔。Bandit 算法通常附带性能保证,这些保证以给定 bandit 问题族中的后悔上限表示。
考虑以下场景。您的任务是向电影流媒体服务的用户推荐电影。在每一轮中,您都会收到有关用户的信息。您的任务是从用户可以选择的一小部分电影中选择一部,目标是选择一部用户会喜欢并给出高评分的电影。
为了说明,我们将众所周知的 MovieLens 数据集转换为 bandit 问题。该数据集包含来自 943 个用户对 1682 部电影的约 10 万个评分。将此数据集转换为上下文 bandit 问题的第一步是构建用户/电影评分矩阵 `A`,其中 `A_ij` 是用户 `i` 对电影 `j` 的评分。由于我们只有从每个用户那里对一些电影的评分,因此评分矩阵 `A` 的一个问题是它非常稀疏,即只有少数条目 `A_ij` 可用;所有其他条目都是未知的。为了解决这个稀疏性问题,我们构建了一个低秩 SVD 分解 `A ~= U*V'`(推荐系统中的低秩矩阵分解是协同过滤的流行方法,例如参见 Koren 等人 2009 年)。这样,`U` 的行就是上下文特征。然后,要推荐给用户的电影就是一组动作,表示为 `V` 的行。推荐电影 `j` 给用户 `i` 的奖励可以计算为 `U_i` 和 `V_j` 的相应行的内积。因此,使用低秩 SVD 分解来计算奖励使我们能够即使对于未推荐给用户的电影也近似估计奖励;因此,他们的评分是未知的。
现在让我们看看如何在 TF-Agents Bandits 库的帮助下对上述问题进行建模和解决。 TF-Agents 是一个模块化库,它具有强化学习和 Bandits 各个方面的构建块。问题可以用“环境”来表达。环境是一个类,它生成观察结果(又称上下文),并且在被呈现动作后也会输出奖励。在 MovieLens 环境的情况下,观察结果是矩阵 `U` 的随机行,而奖励是在算法选择动作(即矩阵 `V` 的行,在本例中为电影)后给出的。MovieLens 环境的实现可以在这里找到 这里。值得注意的是,在 TF-Agents 中实现 bandit 环境相当简单。有关演练,我们建议读者参考我们的 Bandits 教程。
TF-Agents 中的 Bandit 算法有两个主要构建块:“策略”和“代理”。策略是一个函数,它在给定观察结果的情况下选择动作。代理负责学习良好的策略:在给定(观察结果、动作、奖励)元组的示例的情况下,它训练策略以使它选择更好的动作。TF-Agents Bandits 库提供了最流行算法的综合列表,包括线性方法以及非线性方法(例如,那些使用基于神经网络的价值函数的方法)。让我们看看 LinUCB 如何解决 MovieLens 问题!
简而言之,LinUCB 算法 跟踪所有动作的运行平均奖励,以及估计周围的置信区间。在每一轮中,该算法选择具有最高奖励估计上限置信度的动作。
在 TF-Agents 库中,LinUCB 算法由具有“乐观探索策略”的 LinearBanditPolicy 和负责更新估计值的 LinearBanditAgent 构成。请注意,可以将探索策略从“乐观”更改为“采样”,在这种情况下,该算法变为线性汤普森采样。
所以让我们看看 LinUCB 在 MovieLens 环境中的表现!我们在 MovieLens 环境(有 100 个动作和 SVD 分解秩 20)上运行 LinUCB,并在 TensorBoard 上获得结果
(请注意,以下所有图表都是基于对五次运行进行平均的结果,阴影显示标准差。曲线也应用了滚动平均平滑。)

如上所述,对 LinUCB 进行一些修改,我们就可以实现线性汤普森采样 (LinTS)。如果我们在同一个问题上运行 LinTS(实现 这里),我们将得到与 LinUCB 非常相似的结果(见下方的联合图)。
让我们将这些结果与另一个代理进行比较,比如 NeuralEpsilonGreedy 代理。顾名思义,该代理使用神经网络来估计奖励,并添加概率为 `epsilon` 的均匀探索。这种探索策略被称为“epsilon-贪婪”,因为该方法在大多数情况下是贪婪的,但以概率 `epsilon`,它会通过随机选择一个动作进行探索。如果我们运行 Neural Epsilon Greedy 并将来自三种算法的结果汇总在一起,我们将得到
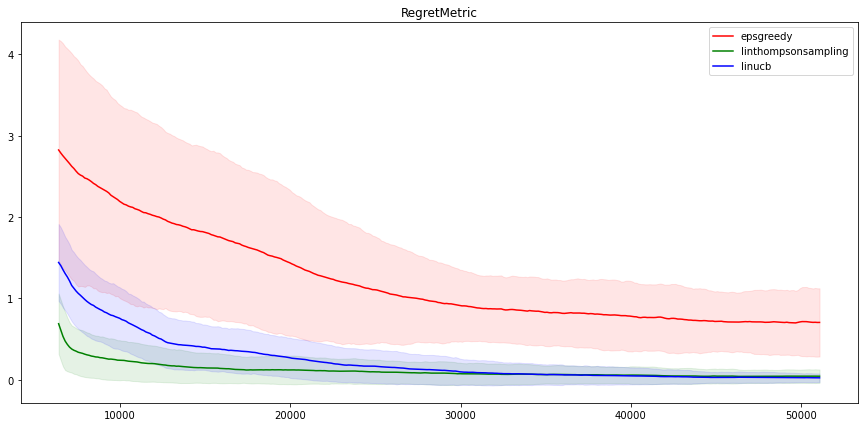
看看这些方法选择次优动作的频率也很有意思。如下所示
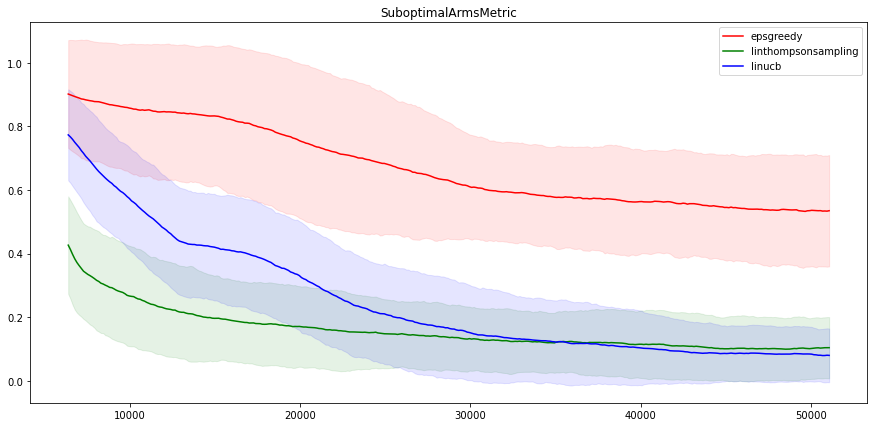
我们看到 LinUCB 和 LinTS 的性能非常相似,这并不令人惊讶,因为它们是非常相似的算法。另一方面,Neural epsilon-Greedy 在这个问题上表现不佳。在五万次迭代之后,指标仍然远不如线性方法。但是请注意,即使是 epsilon-Greedy 算法也能在 100 部电影中找到最佳电影大约一半的时间,这仍然不错!
公平地说,线性算法在这个问题上的表现优于非线性算法,因为这个问题是线性的(由奖励计算构建)。
至于两种线性算法之间的差异,似乎 LinUCB 在一开始有些挣扎,但在长期来看,它比 LinTS 略微(不显著地)好。
上面的 MovieLens 示例有一些缺点:它的动作是一组电影,算法必须为每部电影学习一个不同的模型,而且也很难在系统中引入新电影。为此,我们对环境进行了一些修改:不再将每部电影视为一个独立的动作,而是对电影进行特征建模,类似于用户:`V` 的行将是电影特征。然后,该模型只需要学习一个奖励函数,它的输入是用户特征 `u` 和电影特征 `v`。这样,我们就可以在系统中拥有无限数量的电影,并且可以随时添加新电影。该环境的版本可以在 这里 找到。
我们库中实现的大多数代理都具有在具有动作特征的环境(我们称这些环境为“每臂环境”)中运行的功能。
现在让我们看看不同的算法在 MovieLens 环境的每个臂版本上的表现。我们运行了三种算法的臂特征版本:LinUCB、LinTS 和 eps-Greedy。结果与上一节截然不同:这里线性方法似乎无法找到动作和奖励之间的关系,而神经网络方法给出了与非臂特征问题类似的结果。
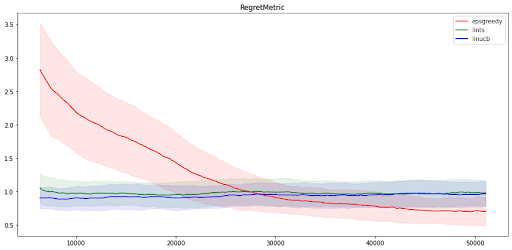
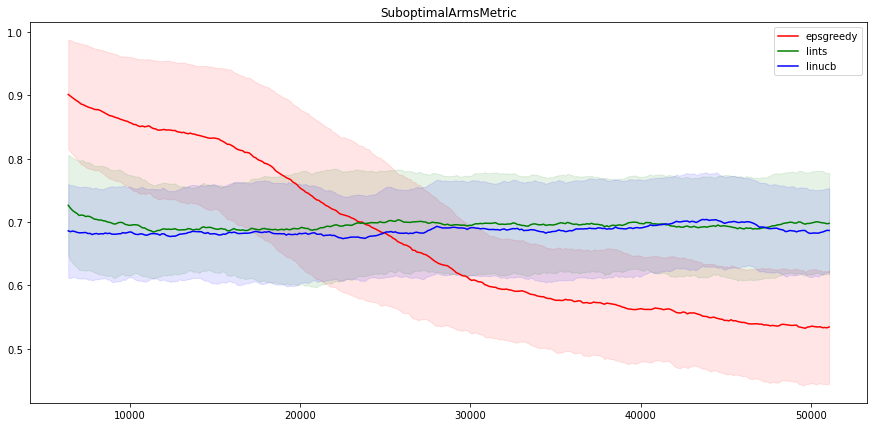
神经网络算法仍然以约 45% 的时间找到最佳动作,而线性算法只有约 30% 的时间。
如果您在库中的代理列表中没有找到您要找的内容,那么实现自己的算法是可能的,而且并不太复杂。您需要
tf_agents.policies.TFPolicy 以及tf_agents.agents.TFAgent。要定义策略,需要实现其私有成员函数 _distribution(...)。简而言之,此函数接受一个观测值并输出一个动作分布(或者在确定性策略的情况下简单地输出一个动作)。
如上所述,代理负责训练策略。为此,TF-Agents 的 TFAgent 的子类(抱歉)必须实现私有成员函数 _train()(以及其他一些函数,为了清楚起见省略了一些细节)。此函数接受训练数据的批次,并训练策略。
如果您想测试您的(新)算法并有一个环境的想法,在 TF-Agents 中实现它也很简单。Bandit 环境有两个主要角色:(i)生成观测值,以及(ii)在代理选择动作后返回奖励。可以通过定义这两个函数轻松创建一个环境类。
在这篇博文中,我们介绍了 TF-Agents Bandit 库,并展示了如何用它来解决推荐问题。如果您想玩一玩本文中使用的环境和代理,可以直接去 这个可执行文件 运行这些代理和更多。如果您想探索该库或只是想了解更多关于该库的信息,我们建议您从这个 教程 开始。如果您有兴趣了解有关在这个 MovieLens 数据集上进行推荐的更多信息,您也可以查看另一个名为 TensorFlow Recommenders 的很棒的库。
TF-Agents Bandits 库是与 Jesse Berent、Tzu-Kuo Huang、Kishavan Bhola、Sergio Guadarrama、Anoop Korattikara、Oscar Ramirez、Eugene Brevdo 和 TF-Agents 团队的许多其他成员合作构建的。

2021 年 7 月 22 日 — 由 Google Research 的 Gábor Bartók 和 Efi Kokiopoulou 发布 本文假设您对强化学习和/或多臂老虎机具有一定的先验经验。如果您是新手,那么一个好的起点是 Bandits 维基百科条目,或者对于更技术性和深入的介绍,请查看 这本书。在这篇博文中,我们介绍了 TensorFlow-AgentsBandits 库。这个库…






{kind=link}