https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgJurdq1EtyB-O_OnJxklEWsWg2SGWUsaE7A7lYzkahS2PpgV3YY5qie6AoFztS9H62xHE-2KEEWsevDS4MJqAfDiHEkTQM8ynbdx1IdosFQX93fXjeKosO-2sZr1wrhXRS-uGOnK7JWtU/s1600/tensorflowcloud.png
来自 TensorFlow 团队的 Pankaj Kanwar、Peter Brandt 和 Zongwei Zhou 发布
MLPerf 是衡量机器学习性能的行业标准,它发布了来自 MLPerf Training v0.7 轮的
最新基准测试结果。我们很高兴地分享,Google 的提交展现了领先的顶尖性能(达到目标质量的最短时间),它能够扩展到 4,000 多台加速器,并且在 Google Cloud 上具有 TensorFlow 2 开发者体验的灵活性。

在这篇博文中,我们将探讨 TensorFlow 2 MLPerf 提交,它展示了企业如何在 Google Cloud 中最先进的 ML 加速器上运行 MLPerf 代表的宝贵工作负载,包括广泛部署的 GPU 和 Cloud TPU 世代。我们附带的
博客文章 突出了我们创纪录的大规模训练结果。
TensorFlow 2:专为性能和可用性而设计
在今年早些时候的 TensorFlow 开发者峰会上,我们强调 TensorFlow 2 将重点放在可用性和实际性能上。当竞争赢得基准测试时,工程师经常依赖低级 API 调用和特定于硬件的代码,这些代码在日常企业环境中可能不实用。借助 TensorFlow 2,我们旨在通过更直接的代码提供开箱即用的高性能,避免低级优化在代码可重用性、代码健康和工程生产力方面可能导致的重大问题。
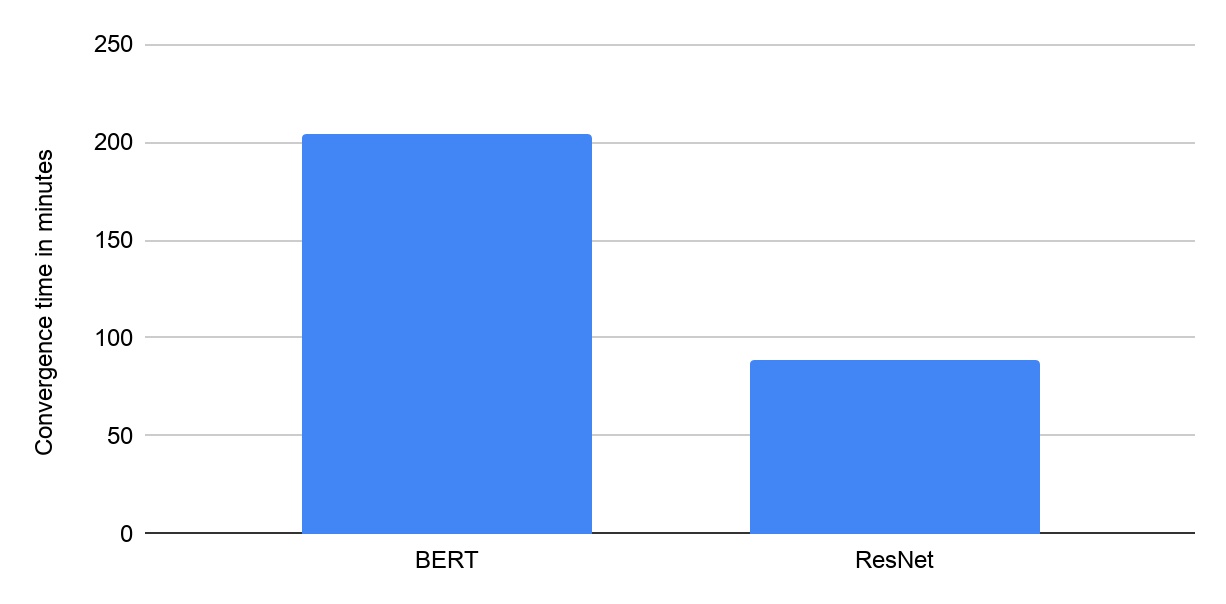 |
| 使用 Google Cloud VM(配备 8 个 NVIDIA V100 GPU)在“可用”类别中从 Google 的 MLPerf Training v0.7 闭源提交中获得的收敛时间(以分钟为单位)。 |
TensorFlow 的 Keras API(请参见此
指南 集合)提供可用性和跨各种硬件架构的可移植性。例如,模型开发人员可以使用
Keras 混合精度 API 和
分布式策略 API 使相同的代码库能够在多个硬件平台上运行,几乎没有摩擦。Google 在“云可用”类别中的 MLPerf 提交是使用这些 API 实现的。这些提交表明,使用高级 Keras API 编写的几乎相同的 TensorFlow 代码可以在行业中两个领先的广泛可用的 ML 加速器平台(NVIDIA 的 V100 GPU 和 Google 的 Cloud TPU v3 Pod)上提供高性能。
注意:图表中显示的所有结果均从 www.mlperf.org 于 2020 年 7 月 29 日检索。MLPerf 的名称和徽标是商标。有关更多信息,请参见 www.mlperf.org。显示的结果:0.7-1 和 0.7-2。
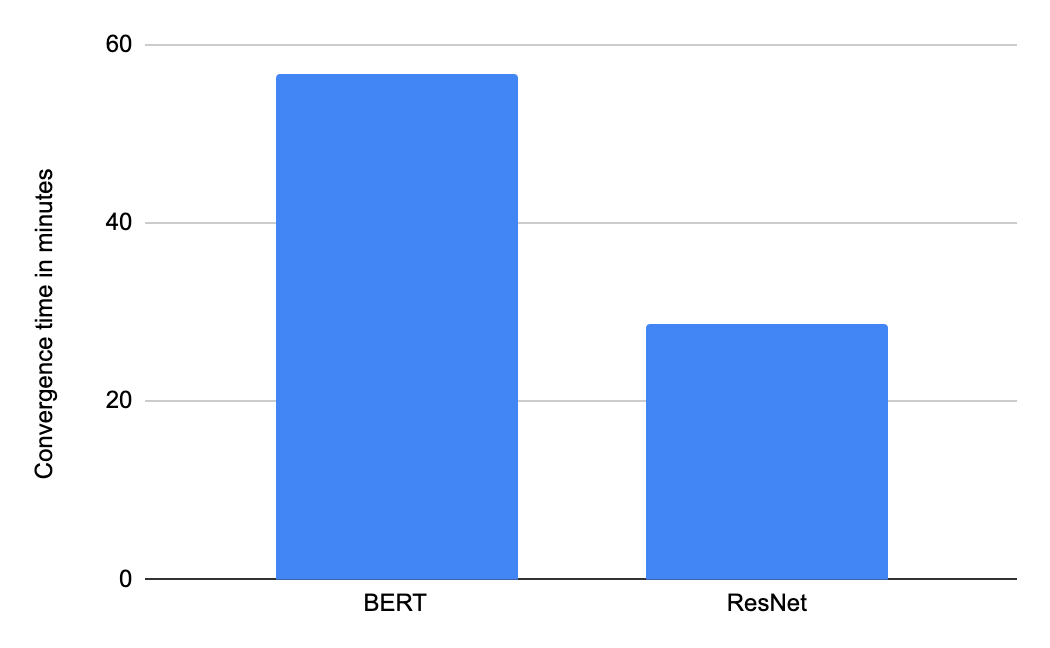 |
| 使用包含 16 个 TPU 芯片的 Google Cloud TPU v3 Pod 切片在“可用”类别中从 Google 的 MLPerf Training v0.7 闭源提交中获得的收敛时间(以分钟为单位)。 |
查看幕后:XLA 的性能增强
Google 在 GPU 和 Cloud TPU Pod 上的提交利用了
XLA 编译器 来优化 TensorFlow 性能。XLA 是 TPU 编译器堆栈的核心部分,可以可选地为 GPU 启用。XLA 是一个基于图的即时编译器,它执行各种不同类型的全程序优化,包括对 ML 操作的广泛
融合。
操作符融合减少了 ML 模型的内存容量和带宽需求。此外,融合减少了操作的启动开销,尤其是在 GPU 上。总的来说,XLA 优化是通用的、可移植的,与 cuDNN 和 cuBLAS 库很好地互操作,并且通常可以为手动编写低级内核提供引人注目的替代方案。
Google 的 TensorFlow 2 在“云可用”类别中的提交使用了 TensorFlow 2.0 中引入的 @tf.function API。@tf.function API 提供了一种简单的方法来
选择性地启用 XLA,对哪些函数将被编译进行精细控制。
XLA 带来的性能提升令人印象深刻:在配备 8 个 Volta V100 GPU(每个 GPU 具有 16 GB 的 GPU 内存)的 Google Cloud VM 上,XLA 将
BERT 的训练吞吐量从每秒 23.1 个序列提高到每秒 168 个序列,提高了约 7 倍。XLA 还将每个 GPU 的可运行批次大小提高了 5 倍。XLA 降低的内存使用量还支持高级训练技术,例如梯度累积。
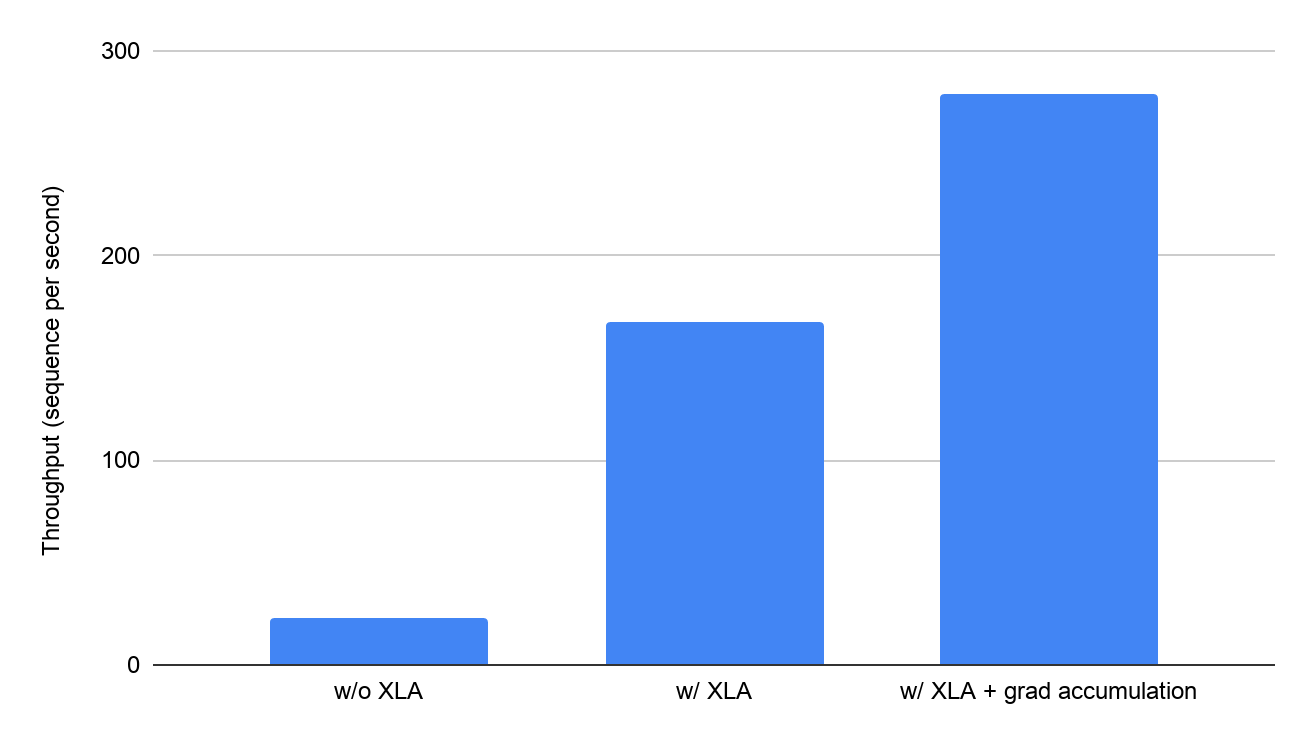 |
| 在 Google Cloud 上使用 8 个 V100 GPU 对 BERT 模型启用 XLA(以分钟为单位)的影响,如 Google 的 MLPerf Training 0.7 闭源提交所示,与同一系统上未经验证的 MLPerf 结果(禁用优化)相比。 |
Google Cloud 上的领先加速器
Google Cloud 是唯一一个提供对最先进的
GPU 和
Cloud TPU 的访问权限的公共云平台,这使 AI 研究人员和数据科学家能够自由选择适合每项任务的硬件。
最先进的模型(例如
BERT)在 Google 和整个行业中被广泛用于各种自然语言处理任务,现在可以在 Google Cloud 上进行训练,利用与在 Google 内部训练工作负载相同的基础设施。使用 Google Cloud,您可以在不到一个小时的时间内,以不到 32 美元的总成本在具有 16 个 TPU 芯片的 Cloud TPU v3 Pod 切片上训练 BERT 处理 300 万个序列。
结论
Google 的 MLPerf 0.7 Training 提交展示了 TensorFlow 2 在最先进的 ML 加速器硬件上的性能、可用性和可移植性。立即开始使用 TensorFlow 2 在
Google Cloud GPU、
Google Cloud TPU 和
TensorFlow Enterprise 上的可用性和功能,以及
Google Cloud 深度学习 VM。
致谢
GPU 上的 MLPerf 提交是与 NVIDIA 密切合作的结果。我们要感谢 NVIDIA 的所有工程师帮助我们完成这项提交。






