https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjL8xPyIorVQnu4S4QqHWLynlLbNUadEBrSe_1FRx6GMfcY4BBwJhecv5GzHKiKFkmn89U81A_rntAlp-iT5FniorqlcpU8BlXS-MqjK0wl7EI_YwJact3QbUaR_M-o-7-Sh_jLvnyvN1s/s1600/mem2.png
由 Josh Gordon 代表 TensorFlow 团队发布
TensorFlow 2.3 已
发布!此版本的重点是提供新的工具,使您更容易加载和预处理数据,以及解决输入管道瓶颈,无论您是在一台机器上还是多台机器上工作。
- tf.data 添加了两种机制来解决输入管道瓶颈并提高资源利用率。对于高级用户,新的 服务 API 提供了一种方法,可在连接到训练设备的主机无法跟上模型的数据消耗需求时提高训练速度。它允许您将输入预处理卸载到与训练作业一起运行的数据处理工作器 CPU 集群,从而提高加速器利用率。第二个新功能是 tf.data 快照 API,它允许您将输入预处理管道的输出持久化到磁盘,以便您可以在不同的训练运行中重用它。这使您可以用存储空间来换取额外的 CPU 时间。
- TF Profiler 也添加了两个新工具:一个内存分析器,用于可视化模型的内存使用情况随时间的变化,以及一个 Python 跟踪器,它允许您跟踪模型中 Python 函数调用。您可以在下面了解更多有关这些内容的信息(如果您不熟悉 TF Profiler,请务必查看这篇 文章)。
- TensorFlow 2.3 添加了对新的 Keras 预处理层 API 的 实验性 支持。这些层允许您将预处理逻辑打包到模型中,以便更轻松地部署 - 因此您可以发布一个接受原始字符串、图像或表格中的行作为输入的模型。还有一些新的用户友好的 实用程序,允许您使用几行代码轻松地从磁盘上的图像 目录 或 文本文件 创建一个 tf.data.Dataset。
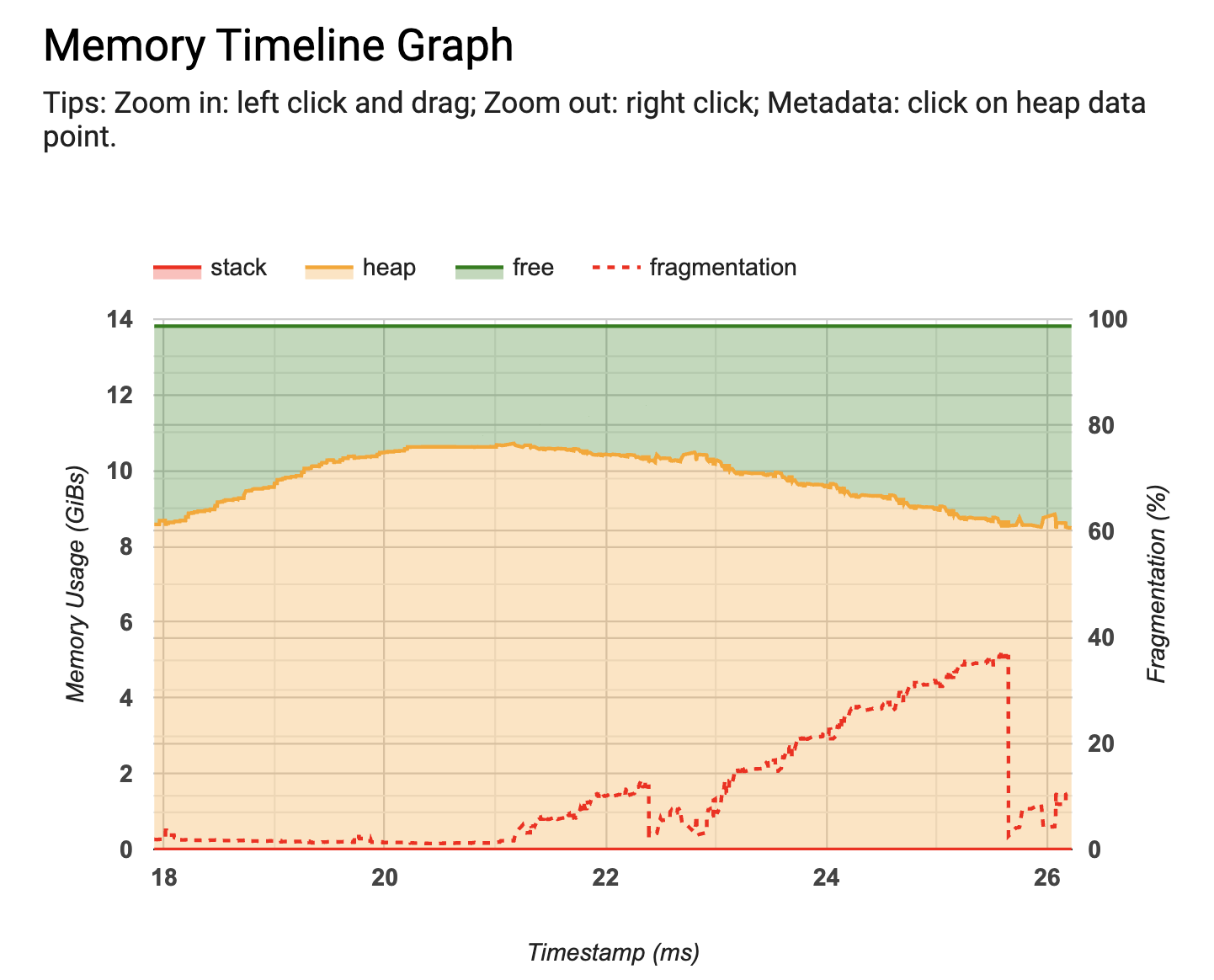 |
| 新的内存分析器 |
tf.data 中的新功能
tf.data.service
现代加速器(GPU、TPU)非常快。为了避免性能瓶颈,务必确保您的数据加载和预处理管道足够快,以便在需要时将数据提供给加速器。例如,假设您的 GPU 每秒可以分类 200 个样本,但您的数据输入管道只能从磁盘加载每秒 100 个样本。在这种情况下,您的 GPU 将有 50% 的时间处于空闲状态(等待数据)。并且,假设您的输入管道已经与 GPU 计算重叠(如果不是,您的 GPU 将有 66% 的时间等待数据)。
在这种情况下,您可以通过使用
tf.data.experimental.service 将数据加载和预处理分布到与您的训练作业一起运行的集群中,来将训练速度提高一倍。tf.data 服务具有调度程序-工作器架构,其中一个调度程序和多个工作器。您可以在
此处 找到有关设置集群的文档,并且可以在
此处 找到一个完整的示例,展示如何使用
Google Kubernetes Engine 部署集群。
启动 tf.data.service 后,您可以使用
distribute 变换将分布式数据集处理添加到您现有的 tf.data 管道中
ds = your_dataset()
ds = dataset.apply(tf.data.experimental.service.distribute(processing_mode="parallel_epochs", service=service_address))
现在,当您遍历数据集时,数据处理将使用 tf.data 服务进行,而不是在您的本地机器上进行。
将您的输入管道进行分布式是一个强大的功能,但是如果您在一台机器上工作,tf.data 也有工具可以帮助您
提高输入管道性能。请务必查看
cache 和
prefetch 变换 - 这可以在一行代码中极大地提高您的管道速度。
tf.data 快照
tf.data.experimental.snapshot API 允许您将预处理管道的输出持久化到磁盘,以便您可以在不同的训练运行中实现预处理数据。这对于用磁盘上的存储空间来换取更宝贵的 CPU 和加速器时间很有用。
例如,假设您有一个执行昂贵预处理的数据集(也许您正在使用裁剪或旋转操作来操作图像)。在开发好您的输入行管道以加载和预处理数据之后
dataset = create_input_pipeline()
您可以通过应用快照变换将结果快照到目录中
dataset = dataset.apply(tf.data.experimental.snapshot("/snapshot_dir"))
当您第一次遍历数据集时,快照将在磁盘上创建。后续迭代将从
snapshot_dir 读取,而不是重新计算数据集元素。
快照会计算您数据集的指纹,以便它可以检测到您输入管道的更改,并自动重新计算过时快照。例如,如果您修改了
Dataset.map 变换或向源目录添加了更多图像,指纹将发生变化,导致快照重新计算。请注意,快照无法检测到对
现有文件的更改。查看
文档 了解更多信息。
TF Profiler 中的新功能
TF Profiler(在 TF 2.2 中
推出)使找出性能瓶颈变得更加容易。它可以帮助您确定应用程序何时受输入限制,并可以提供有关如何修复它的建议。您可以在
使用 TF Profiler 分析 tf.data 性能 指南中详细了解此工作流程。
在 TF 2.3 中,Profiler 具有一些新功能和一些可用性改进。
- 新的 内存分析器使您能够在训练期间监控内存使用情况。如果训练作业用尽内存,您可以准确地找出峰值内存使用量发生的时间以及哪些操作消耗了最多的内存。如果您收集了一个配置文件,则内存分析器工具将显示在 Profiler 仪表板中,无需任何额外操作。
- 新的 Python 跟踪器有助于跟踪 Python 调用栈,以便提供有关您的程序中正在执行的操作的更多见解。它显示在 Profiler 的跟踪查看器中。它可以通过 ProfilerOptions 在程序模式下启用,或者通过 TensorBoard 的“捕获配置文件”UI 在采样模式下启用(您可以在此 指南 中找到有关这些模式的更多信息)。
新的 Keras 数据加载实用程序
在 TF 2.3 中,Keras 添加了新的用户友好型实用程序(
image_dataset_from_directory 和
text_dataset_from_directory),使您能够轻松地从磁盘上的图像目录或文本文件目录创建 tf.data.Dataset,只需一个函数调用。例如,如果您的目录结构是
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
您可以使用
image_dataset_from_directory 创建一个 tf.data.Dataset,该数据集将从子目录和标签中生成图像批次
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
“datasets/cats_and_dogs”,
validation_split=0.2,
subset="training",
seed=0,
image_size=(img_height, img_width),
batch_size=32)
如果您要启动一个新项目,建议您使用
image_dataset_from_directory 而不是传统的
ImageDataGenerator。请注意,此实用程序不会执行数据增强(这应该使用下面描述的新预处理层来完成)。您可以在
此处 找到使用此实用程序加载图像的完整示例(以及如何使用 tf.data 从头开始编写类似的输入管道)。
性能提示
在创建 tf.data.Dataset(无论是从头开始,还是使用
image_dataset_from_directory)之后,请记住为其配置性能,以确保在训练模型时 I/O 不会成为瓶颈。您可以使用一行代码来完成此操作。使用这行代码
train_ds = train_ds.cache().prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
您将创建一个数据集,该数据集将图像缓存到内存中(一旦它们在第一个训练时期期间从磁盘加载),并将 CPU 上的预处理工作与 GPU 上的训练工作重叠。如果您的数据集太大而无法放入内存,您也可以使用
.cache(filename) 自动创建高效的磁盘缓存,该缓存比许多小文件读取速度更快。
您可以在
使用 tf.data API 提高性能 指南中了解更多信息。
新的 Keras 预处理层
在 TF 2.3 中,Keras 还添加了新的
实验性 预处理
层,这些层可以通过允许您将预处理逻辑作为模型
内部的层包含在内来简化部署,因此当您导出模型时,它们将像其他层一样被保存。
- 例如,使用新的 TextVectorization 层,您可以开发一个接受原始字符串作为输入的文本分类模型(无需重新实现任何标记化、标准化、向量化或填充逻辑服务器端)。
- 您也可以使用调整大小、重新缩放和规范化层来开发一个图像分类模型,该模型可以接受任何大小的图像作为输入,并自动将像素值规范化为预期范围。而且,您可以使用新的数据增强层(如随机旋转)通过在 GPU 上运行数据增强来加速您的输入管道。
- 对于结构化数据,您可以使用字符串查找等层来编码分类特征,以便您可以开发一个以表格中的行作为输入的模型。您可以查看此RFC以了解更多信息。
学习如何使用这些新层的最佳方法是尝试新的
从头开始的文本分类、
从头开始的图像分类和
从头开始的结构化数据分类示例
keras.io上。
请注意,所有这些层都可以包含在您的模型中,也可以通过映射转换应用于您的 tf.data 输入管道。您可以在这里找到一个示例
这里。
请记住,这些新的预处理层在 TF 2.3 中是实验性的。我们对设计感到满意(并预计它们将在 2.4 中变为非实验性的),但我们意识到我们可能没有在这次迭代中做好所有事情。您的反馈非常欢迎。请在 GitHub 上提交一个
问题,让我们知道我们如何更好地支持您的用例。
下一步
查看
发行说明以获取更多信息。要保持最新状态,您可以阅读 TensorFlow 的
博客,关注
twitter.com/tensorflow,或订阅
youtube.com/tensorflow。如果您构建了一些想要分享的东西,请将其提交到我们的社区亮点页面
goo.gle/TFCS。对于反馈,请在
GitHub上提交问题。谢谢!






