
negloglik = lambda y, p_y: -p_y.log_prob(y)import tensorflow as tf
import tensorflow_probability as tfp
tfd = tfp.distributions
# Build model.
model = tf.keras.Sequential([
tf.keras.layers.Dense(1),
tfp.layers.DistributionLambda(lambda t: tfd.Normal(loc=t, scale=1)),
])
# Do inference.
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.05), loss=negloglik)
model.fit(x, y, epochs=500, verbose=False)
# Make predictions.
yhat = model(x_tst)tfp.layers.DistributionLambda 层实际上返回了 tfd.Distribution 的一个特殊实例(有关此内容的更多详细信息,请参见附录 A),因此我们可以自由地获取其均值并将其绘制在数据旁边mean = yhat.mean()
# Build model.
model = tfk.Sequential([
tf.keras.layers.Dense(1 + 1),
tfp.layers.DistributionLambda(
lambda t: tfd.Normal(loc=t[..., :1],
scale=1e-3 + tf.math.softplus(0.05 * t[..., 1:]))),
])
# Do inference.
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.05), loss=negloglik)
model.fit(x, y, epochs=500, verbose=False)
# Make predictions.
yhat = model(x_tst)mean = yhat.mean()
stddev = yhat.stddev()
mean_plus_2_stddev = mean - 2. * stddev
mean_minus_2_stddev = mean + 2. * stddev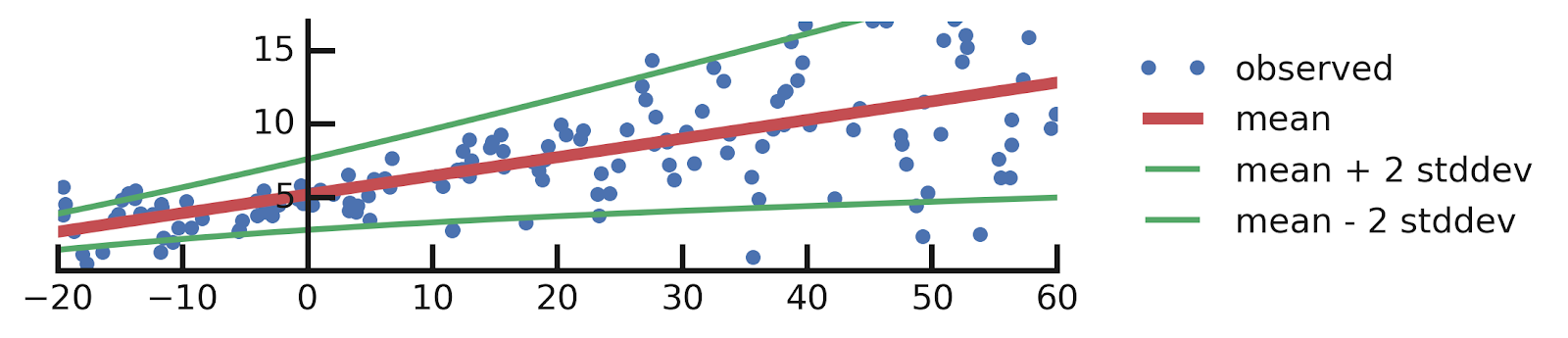
DenseVariational 层替换标准 Keras Dense 层。DenseVariational 层使用权重上的变分后验 _Q_(_w_) 来表示其值中的不确定性。该层将 _Q_(_w_) 规范化为接近 _先验_ 分布 _P_(_w_),该分布在查看数据之前对权重中的不确定性进行建模。# Build model.
model = tf.keras.Sequential([
tfp.layers.DenseVariational(1, posterior_mean_field, prior_trainable),
tfp.layers.DistributionLambda(lambda t: tfd.Normal(loc=t, scale=1)),
])
# Do inference.
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.05), loss=negloglik)
model.fit(x, y, epochs=500, verbose=False)
# Make predictions.
yhats = [model(x_tst) for i in range(100)]DenseVariational 层很简单。上面代码的一个有趣方面是,当我们使用具有这种层的模型进行预测时,每次预测都会得到不同的答案。这是因为 DenseVariational 本质上定义了一个模型集合。让我们看看这个集合告诉我们关于模型参数的信息。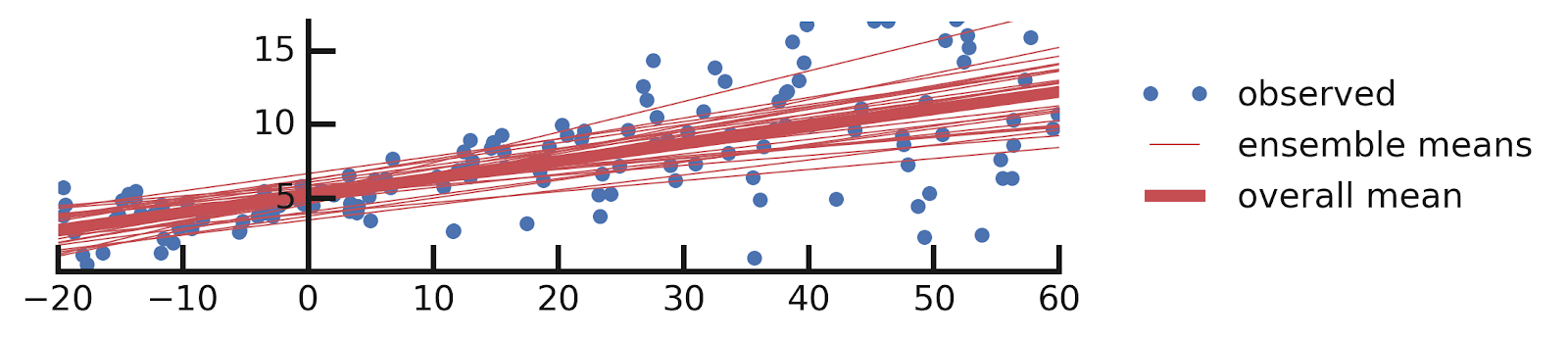
# Build model.
model = tf.keras.Sequential([
tfp.layers.DenseVariational(1 + 1, posterior_mean_field, prior_trainable),
tfp.layers.DistributionLambda(
lambda t: tfd.Normal(loc=t[..., :1],
scale=1e-3 + tf.math.softplus(0.01 * t[..., 1:]))),
])
# Do inference.
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.05), loss=negloglik)
model.fit(x, y, epochs=500, verbose=False);
# Make predictions.
yhats = [model(x_tst) for _ in range(100)]DenseVariational 层添加了一个额外的输出,以对标签分布的尺度进行建模。与我们之前的解决方案一样,我们得到了一个模型集合,但这一次,它们都报告了 _y_ 作为 _x_ 的函数的可变性。让我们绘制这个集合
negloglik 函数,同时对模型进行局部修改以处理越来越多的不确定性类型。API 还允许您自由地在最大似然学习、II 型最大似然和完全贝叶斯处理之间切换。我们相信此 API 极大地简化了概率模型的构建,并很高兴将其与世界分享。VariationalGaussianProcess 层,它使用变分近似(类似于我们在上面情况 3 和 4 中所做的)来对完整的 Gaussian Process 进行近似,从而构建出一个高效且灵活的回归模型。为了简单起见,我们将仅考虑关于输入和标签之间关系形式的认知不确定性。在我们将要做的假设方面,我们将简单地假设我们正在拟合的函数在局部是平滑的:它可以在整个数据集上尽可能地变化,但如果两个输入彼此接近,它将返回相似的值。num_inducing_points = 40
model = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=[1], dtype=x.dtype),
tf.keras.layers.Dense(1, kernel_initializer='ones', use_bias=False),
tfp.layers.VariationalGaussianProcess(
num_inducing_points=num_inducing_points,
kernel_provider=RBFKernelFn(dtype=x.dtype),
event_shape=[1],
inducing_index_points_initializer=tf.constant_initializer(
np.linspace(*x_range, num=num_inducing_points,
dtype=x.dtype)[..., np.newaxis]),
unconstrained_observation_noise_variance_initializer=(
tf.constant_initializer(
np.log(np.expm1(1.)).astype(x.dtype))),
),
])
# Do inference.
batch_size = 32
loss = lambda y, rv_y: rv_y.variational_loss(
y, kl_weight=np.array(batch_size, x.dtype) / x.shape[0])
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.01), loss=loss)
model.fit(x, y, batch_size=batch_size, epochs=1000, verbose=False)
# Make predictions.
yhats = [model(x_tst) for _ in range(100)]
DistributionLambda 是一种特殊的 Keras 层,它使用 Python lambda 来构建一个以层输入为条件的分布。layer = tfp.layers.DistributionLambda(lambda t: tfd.Normal(t, 1.))
distribution = layer(2.)
assert isinstance(distribution, tfd.Normal)
distribution.loc
# ==> 2.
distribution.stddev()
# ==> 1.negloglik 损失函数,因为 Keras 将模型最后一层的输出传递给损失函数,而对于本文中的模型,所有这些层都返回分布。有关如何使用这些层的更多方法,请参见 使用 TensorFlow Probability 层构建变分自编码器 文章。DenseVariational 层使用变分推断来学习其权重上的分布。这是通过最大化 ELBO(证据下界)目标来实现的。
DenseVariational 分别计算 ELBO 的两项。第一项是通过用 Q 中的单个随机样本进行近似来计算的。如果我们仔细观察该项,那么对于 w 的任何特定值,它恰好是我们一直在本文中用于回归的负对数似然损失。因此,通过简单地从 Q 中抽取一组随机权重,然后计算常规损失,我们就自动地近似了 ELBO 的第一项。def prior_trainable(kernel_size, bias_size=0, dtype=None):
n = kernel_size + bias_size
return tf.keras.Sequential([
tfp.layers.VariableLayer(n, dtype=dtype),
tfp.layers.DistributionLambda(lambda t: tfd.Independent(
tfd.Normal(loc=t, scale=1),
reinterpreted_batch_ndims=1)),
])DistributionLambda 层的常规 Keras 模型!这里唯一的新组件是 VariableLayer,它简单地返回可训练变量的值,忽略任何输入(因为先验分布不以任何输入为条件)。请注意,如果我们想将此转换为不可训练的先验分布,我们将向 VariableLayer 构造函数传递 trainable=False。

2019 年 3 月 12 日 — 由 Pavel Sountsov、Chris Suter、Jacob Burnim、Joshua V. Dillon 和 TensorFlow Probability 团队发布
背景在 2019 年的 TensorFlow Dev Summit 上,我们宣布了 TensorFlow Probability (TFP) 中的概率层。在这里,我们将更详细地演示如何使用 TFP 层来管理回归预测中固有的不确定性。
回归与概率回归 是最基本的…





