https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhRYzkKyQrRaG84yBvfz7mkIUvzhX2aSyOQ7Caf42biWnIm6SR-V783fFXB9A9AB5QqIiC1eg7EqDtwji0o5OVxS9Tys4mNx-mVa9fNKfBVkrnApU3cxiiC2qvRsb0i-ogPHVoUHMb-q_Q/s1600/model.png
作者:Alex Ingerman (产品经理) 和 Krzys Ostrowski (研究科学家)
据估计,全球有
30 亿部智能手机,以及
70 亿台联网设备。这些手机和设备不断生成新的数据。传统的分析和机器学习需要将这些数据集中收集,然后才能对其进行处理以产生洞察力、ML 模型,并最终产生更好的产品。这种集中式方法可能存在问题,尤其是在数据敏感或集中成本过高的情况下。如果我们能够直接在数据生成设备上运行数据分析和机器学习,同时仍然能够将学习到的内容聚合在一起,是不是更好?
TensorFlow Federated (TFF) 是一个开源框架,用于在分散数据上进行机器学习和其他计算的实验。它实现了一种称为
联邦学习 (FL) 的方法,该方法使许多参与的客户端能够训练共享的 ML 模型,同时将数据保留在本地。我们基于在 Google 开发联邦学习技术时的
经验 设计了 TFF,它为
移动键盘预测 和
设备上的搜索 提供 ML 模型。借助 TFF,我们很高兴将一个灵活的、开放的框架提供给所有 TensorFlow 用户,让他们可以本地模拟分散计算。
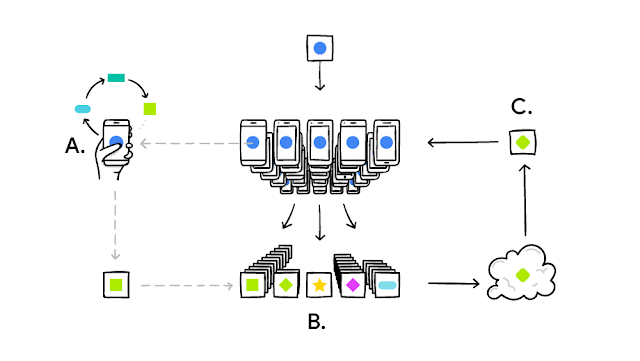 |
| TensorFlow Federated 使开发人员能够表达和模拟联邦学习系统。如下图所示,每部手机都在本地训练模型 (A)。它们的更新被聚合 (B) 以形成一个改进的共享模型 (C)。 |
为了说明 FL 和 TFF 的使用,让我们从最著名的图像数据集之一 MNIST 开始。原始的 NIST 数据集(MNIST 是从该数据集创建的)包含来自 3600 名志愿者的 810,000 个手写数字图像,我们的任务是构建一个能够识别数字的 ML 模型。我们通常的做法是将 ML 算法一次性应用于整个数据集。但如果我们无法将所有这些数据组合在一起,例如,因为志愿者不同意将原始数据上传到中央服务器怎么办?
借助 TFF,我们可以表达我们选择的 ML 模型架构,然后跨所有作者提供的数据训练它,同时将每个作者的数据分开并保留在本地。我们将在下面使用 TFF 的
联邦学习 (FL) API 展示如何做到这一点,该 API 使用由
Leaf 项目 处理的 NIST 数据集版本来分离每个志愿者所写的数字。
# Load simulation data.
source, _ = tff.simulation.datasets.emnist.load_data()
def client_data(n):
dataset = source.create_tf_dataset_for_client(source.client_ids[n])
return mnist.keras_dataset_from_emnist(dataset).repeat(10).batch(20)
# Wrap a Keras model for use with TFF.
def model_fn():
return tff.learning.from_compiled_keras_model(
mnist.create_simple_keras_model(), sample_batch)
# Simulate a few rounds of training with the selected client devices.
trainer = tff.learning.build_federated_averaging_process(model_fn)
state = trainer.initialize()
for _ in range(5):
state, metrics = trainer.next(state, train_data)
print (metrics.loss)
您可以在
联邦 MNIST 分类教程 中看到其余部分。
除了 FL API 之外,TFF 还附带了一组较低级别的基本原语,我们称之为
联邦核心 (FC) API。该 API 能够表达对分散数据集进行广泛计算。使用联邦学习训练 ML 模型是联邦计算的一个例子;在分散数据上评估它是另一个例子。
让我们用一个简单的例子来了解 FC API。假设我们有一组传感器,这些传感器正在捕获温度读数,并且想要计算这些传感器的平均温度,而无需将它们的数据上传到中央位置。借助 FC API,我们可以表达一种新的数据类型,指定其底层数据 (
tf.float32) 以及数据所在的位置(在分布式客户端上)。
READINGS_TYPE = tff.FederatedType(tf.float32, tff.CLIENTS)
然后指定该类型的联邦平均函数。
@tff.federated_computation(READINGS_TYPE)
def get_average_temperature(sensor_readings):
return tff.federated_average(sensor_readings)
在定义联邦计算后,TFF 会以一种可以在分散环境中运行的形式来表示它。TFF 的初始版本包含一个本地机器运行时,它模拟计算在持有数据的客户端集合中执行,每个客户端计算其本地贡献,而中央协调器会聚合所有贡献。但是,从开发人员的角度来看,联邦计算可以看作一个普通的函数,它恰好具有位于不同位置(分别在单个客户端和协调服务上)的输入和输出。
 |
| get_average_temperature 联邦计算表达式的说明。 |
使用 TFF 的声明式模型,表达
联邦平均算法 的简单变体也很简单
@tff.federated_computation(
tff.FederatedType(DATASET_TYPE, tff.CLIENTS),
tff.FederatedType(MODEL_TYPE, tff.SERVER, all_equal=True),
tff.FederatedType(tf.float32, tff.SERVER, all_equal=True))
def federated_train(client_data, server_model, learning_rate):
return tff.federated_average(
tff.federated_map(local_train, [
client_data,
tff.federated_broadcast(server_model),
tff.federated_broadcast(learning_rate)]))
借助 TensorFlow Federated,我们正朝着使该技术更广泛地被人们接受迈出一小步,并邀请社区参与在开放、灵活的平台之上开发联邦学习研究。您可以通过完成
教程,只需点击几下鼠标,就能在您的浏览器中试用 TFF。有许多参与方式:您可以对模型上的现有 FL 算法进行实验,将新的联邦数据集和模型贡献给
TFF 存储库,添加新的 FL 算法的实现,或使用新功能扩展现有算法。
随着时间的推移,我们希望 TFF 运行时能够适用于主要设备平台,并与其他有助于保护敏感用户数据的技术集成,包括
联邦学习的差分隐私(与
TensorFlow Privacy 集成)和
安全聚合。我们期待与社区一起开发 TFF,并使每个开发人员都能使用联邦技术。
准备好开始了吗?请访问
https://tensorflowcn.cn/federated/,立即试用 TFF!
致谢创建 TensorFlow Federated 是团队合作的结果。特别感谢 Brendan McMahan、Keith Rush、Michael Reneer 和 Zachary Garrett,他们都做出了重大贡献。






