https://blog.tensorflowcn.cn/2019/03/introducing-tensorflow-privacy-learning.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgrs6k9apCn8m6tYRQossmZVO_35vtMnKHFMpxTv4F7zQWfYSx-3KbE72YaGQW3ZlbPXWqyqd1xC4ulgy86AFQt7xmPeknI_GafZpVlJcRmVXZJQF6x_2eYhkgMF9E8EvOfXrRgELJrcfc/s1600/mnist.png
作者:Carey Radebaugh(产品经理)和 Ulfar Erlingsson(研究科学家)
今天,我们很高兴宣布推出 TensorFlow Privacy (
GitHub),这是一个开源库,不仅可以帮助开发人员使用隐私训练机器学习模型,还可以帮助研究人员在具有强大隐私保证的机器学习方面推进技术发展。
现代机器学习越来越多地用于创建令人惊叹的新技术和用户体验,其中许多涉及训练机器从敏感数据(例如个人照片或电子邮件)中负责任地学习。理想情况下,经过训练的机器学习模型的参数应该编码一般模式而不是关于特定训练示例的事实。为了确保这一点,并在训练数据敏感时提供强大的隐私保证,可以使用基于 *
差分隐私* 理论的技术。特别是在使用用户数据进行训练时,这些技术提供了强大的数学保证,即模型不会学习或记住有关任何特定用户的详细信息。特别是对于深度学习,额外的保证可以有效地加强其他隐私技术提供的保护,无论是已建立的技术,如阈值和数据删除,还是新的技术,如
TensorFlow Federated 学习。

多年来,谷歌一直引领着差分隐私的基础研究以及实用差分隐私机制的开发(例如,参见
此处 和
此处),最近专注于机器学习应用(参见
这篇、
这篇 或
这篇 研究论文)。去年,谷歌发布了其
负责任的 AI 实践,详细介绍了我们对负责任地开发机器学习系统和产品的推荐实践;甚至在这份出版物之前,我们一直在努力让外部开发人员能够轻松地在自己的产品中应用这些实践。
我们努力的结果之一是今天宣布发布
TensorFlow Privacy 以及更新的
技术白皮书,更详细地描述其隐私机制。
要使用 TensorFlow Privacy,无需任何隐私或其底层数学知识:使用标准 TensorFlow 机制的用户无需更改其模型架构、训练程序或流程。相反,为了训练保护训练数据隐私的模型,您通常只需要进行一些简单的代码更改并调整与隐私相关的超参数。
示例:使用隐私学习语言
作为一个差分隐私训练的具体例子,让我们考虑在文本序列上训练字符级循环语言模型。使用神经网络进行语言建模是一项基本的深度学习任务,用于无数应用,其中许多应用基于
使用敏感数据进行训练。我们使用相同的模型架构训练两个模型——一个以标准方式训练,另一个使用差分隐私训练,该模型基于 TensorFlow Privacy
GitHub 存储库 中的示例代码。
这两个模型在对来自标准
宾夕法尼亚树库训练数据集 的金融新闻文章中的英语进行建模方面都表现良好。但是,如果这两个模型之间的微小差异是由于未能捕获语言分布的一些基本核心方面造成的,那么这将对差分隐私模型的效用产生怀疑。(另一方面,即使私有模型未能捕获训练数据中一些深奥的独特细节,其效用可能仍然很好。)
为了确认私有模型的效用,我们可以查看这两个模型在训练和测试数据集上的性能,并检查它们一致和不一致的句子集。为了查看它们之间的共性,我们可以测量它们在建模句子上的相似性,以查看这两个模型是否都接受相同的核心语言;在这种情况下,这两个模型都接受并高度评价(即,对超过 98% 的训练数据序列具有较低的困惑度)。例如,这两个模型都高度评价以下金融新闻句子(以斜体显示,因为它们明显属于我们想要学习的分布)
"市场几乎没有成交量,没有任何刺激因素"
"韩国和日本继续盈利"
"商业银行在各方面都更加强劲"
为了查看它们的差异,我们可以检查两个模型的得分差异很大的训练数据句子。例如,以下三个训练数据句子都被常规语言模型高度评价并接受,因为它们在标准训练期间被有效地记忆。但是,差分隐私模型对这些句子的评分非常低,并且不接受它们。(下面,句子以粗体显示,因为它们似乎超出了我们想要学习的语言分布。)
"
aer banknote berlitz calloway … ssangyong swapo wachter
naczelnik 站在那里
我的上帝,我知道我是正确的,我是无辜的"
以上所有句子似乎在金融新闻中都应该非常罕见;此外,它们似乎是隐私保护的合理候选者,例如,因为这些罕见、奇怪的句子可能会识别或揭示有关在敏感数据上训练的模型中个人的信息。三个句子中的第一个是训练数据中出现的一个长序列随机词,这是出于技术原因;第二个句子部分是波兰语;第三个句子——虽然看起来很自然的英语——并非来自我们正在建模的金融新闻语言。这些例子是手动选择的,但完整检查确认,差分隐私模型不接受的训练数据句子通常位于金融新闻文章的正常语言分布之外。此外,通过评估测试数据,我们可以验证这些深奥的句子是私有模型和非私有模型之间质量下降的基础(困惑度分别为 1.13 和 1.19)。因此,虽然标称困惑度损失约为 6%,但私有模型在我们在乎的句子上的性能可能几乎没有下降。
显然,至少部分程度上,这两个模型的差异是由于私有模型未能记住对训练数据来说不正常的罕见序列。我们可以通过利用我们之前关于测量神经网络中无意记忆的
工作 来量化这种影响,该工作有意在训练数据中插入独特的随机 *金丝雀* 句子,并评估金丝雀对训练模型的影响。在这种情况下,插入单个随机金丝雀句子足以使非私有模型完全记住该金丝雀。但是,使用差分隐私训练的模型在面对任何单个插入的金丝雀时是无法区分的;只有当相同的随机序列在训练数据中出现很多次时,私有模型才会学到有关它的任何信息。值得注意的是,这对所有类型的机器学习模型都是如此(例如,参见上面来自 MNIST 训练数据的稀有示例的图表),即使模型隐私的数学形式上限过大,理论上无法提供任何保证也是如此。
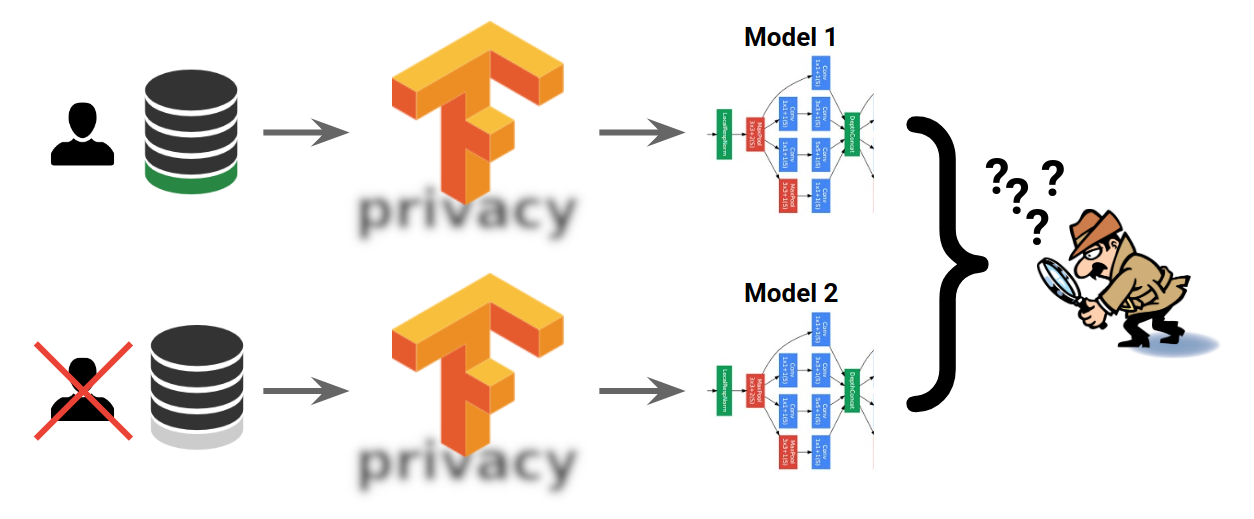
TensorFlow Privacy 可以防止对稀有细节的这种记忆,并且如上图所示,可以保证两个机器学习模型将无法区分某些示例(例如,某些用户的数据)是否用于它们的训练。
下一步和进一步阅读
要开始使用 TensorFlow Privacy,您可以查看
GitHub 存储库 中的示例和教程。特别是,这些包括一个详细的教程,说明如何使用传统的 TensorFlow 机制执行 MNIST 基准机器学习任务的差分隐私训练,以及 TensorFlow 2.0 和 Keras 的更新的更 *急切* 的方法。
使用 TensorFlow Privacy 所需的关键新步骤是设置三个新的超参数,它们控制梯度创建、裁剪和噪声的方式。在训练过程中,差分隐私通过使用经过修改的随机梯度下降优化模型来确保,该方法将由训练数据示例引起的多个梯度更新平均在一起,将每个梯度更新裁剪到一定的最大范数,并将高斯随机噪声添加到最终平均值。这种学习方式对每个训练数据示例的影响设置了最大边界,并确保由于添加的噪声,没有单个示例会独自产生任何影响。设置这三个超参数可能是一门艺术,但 TensorFlow Privacy 存储库包含有关如何在具体示例中选择它们的指南。
我们希望 TensorFlow Privacy 能够发展成为训练具有强大隐私保证的机器学习模型的最佳技术中心。因此,我们鼓励所有感兴趣的各方参与进来,例如,通过执行以下操作
- 在 这篇 或 这篇 博客文章中进一步了解差分隐私及其在机器学习中的应用。
- 对于从业人员,尝试在您自己的机器学习模型上应用 TensorFlow Privacy,并通过调整超参数、模型容量和架构、激活函数等来试验隐私和效用之间的平衡。
- 对于研究人员,尝试通过改进分析(例如,模型参数选择)来推进具有强大隐私保证的现实世界机器学习技术发展。
- 通过提交 pull 请求,为 TensorFlow Privacy 做出贡献。
- 通过在 GitHub 上提交问题,提出问题并分享您的评论或疑虑。
致谢
我们要感谢 Galen Andrew、Nicholas Carlini、Steve Chien、Brendan McMahan、Ilya Mironov 和 Nicolas Papernot 对 TensorFlow Privacy 的贡献。






