https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgJJA_TAnRLgTMh153J8IaH0lAO1F0ywI0OocsQ9SrccCt0flADSkyHoWfqdnwZ4PET2veSBWs6lo55sAjCQxR7zUx8hAeyFxsupAEarMbu_atXwr6nHuBlUpB095LDjyMA_vqjSCVN7yA/s1600/genomics.jpeg
作者:Gunjan Baid、Helen Li 和 Pi-Chuan Chang
编者注:本文内容与
Google DeepVariant 博客 上发布的内容相同。
简介
本文将 DNA 测序错误校正描述为一个多类分类问题,并提出了两种深度学习解决方案。我们的第一种方法校正单个读中的错误,而第二种方法(如图 1 所示)从多个读中构建共识,以预测正确的 DNA 序列。我们
Colab 笔记本教程 使用
Nucleus 和
TensorFlow 库实现了第二种方法。我们的目标是展示如何将 Nucleus 与 TensorFlow 结合使用,以解决基因组学中的机器学习问题。

问题概述
虽然 DNA 测序速度越来越快,成本也越来越低,但它仍然是一个容易出错的过程。Illumina 等公司开发的下一代测序 (NGS) 技术的原始数据的错误率约为 1%。Pacific BioSciences (PacBio) 等公司开发的越来越流行的第三代技术的错误率约为 15%。测序错误可以分为替换、插入和缺失,后两种通常称为插入缺失。所有这些错误都会对下游分析步骤(如变异调用和基因组组装)造成不利影响。
获得更高质量数据集的一种简单方法是丢弃可能包含错误的数据,方法是丢弃整个读或修剪质量低的区域。这种方法并不理想,因为它会导致最终数据集变小。此外,某些序列上下文自然具有更高的错误率,从而导致抽样偏差。因此,存在大量研究致力于开发更复杂的方法来进行错误校正。大多数已开发的方法可以分为两类:
- 对单个读进行操作并旨在确定正确读序列的方法
- 基于共识的方法,对多个读进行操作并旨在确定正确的底层 DNA 序列
深度学习概述
本文中提出的两种方法都使用深度神经网络,深度神经网络学习将输入映射到输出的函数。神经网络由多个线性层和非线性运算层组成,这些层按顺序应用于输入。神经网络已成功应用于各种问题,包括
图像分类 和
自然语言翻译。最近,它们还被用于基因组学中的问题,例如
蛋白质结构预测 和
变异调用。
方法
Nucleus
我们的实现依赖于
Nucleus,这是一个由 Google Brain 的基因组学团队开发的用于处理基因组数据的库。Nucleus 使用专门的读写器对象,可以轻松读取、写入和分析常见的基因组文件格式,如 BAM、FASTA 和 VCF。Nucleus 允许我们:
- 查询 VCF 文件以获取给定基因组区域中的所有变异
- 查询 BAM 文件以获取映射到给定基因组范围内的所有读
- 查询 FASTA 文件以获取从给定位置开始的参考序列
我们还使用 Nucleus 将数据写入
TFRecords,TFRecords 是一种二进制文件格式,由协议缓冲区消息组成,可以轻松地被 TensorFlow 读取。在读取 TFRecords 后,我们使用
Estimator API 来训练和评估卷积神经网络。
数据
以下是我们在实现中使用的一些文件。所有数据都是公开可用的,
教程 包含下载链接和说明。
NA12878_sliced.bam - 来自染色体 20(位置 10,000,000-10,100,000)的 Illumina HiSeq 读,下采样到 30x 覆盖率。
NA12878_sliced.bam.bai - NA12878_sliced.bam 的索引。
NA12878_calls.vcf.gz - 来自 Genome in a Bottle 的 NA12878 的变异真值集。
NA12878_calls.vcf.gz.tbi - NA12878_calls.vcf.gz 的索引。
hs37d5.fa.gz - hs37d5 的参考基因组。
hs37d5.fa.gz.fai 和 hs37d5.fa.gz.gzi - hs37d5.fa.gz 的索引文件。
网络架构
卷积神经网络通常用于计算机视觉任务,但也
适用于基因组学。每个卷积层都会重复将学习的过滤器应用于输入。网络早期出现的卷积过滤器学习识别输入中的低级特征,例如图像中的边缘和颜色梯度,而后期过滤器则学习识别更复杂的低级特征组合。对于 DNA 序列输入,低级卷积过滤器充当基序检测器,类似于
序列标志 的位置权重矩阵。
在我们的实现中,我们使用了一个标准的卷积架构,它包含两个卷积层,后面跟着三个全连接层。我们使用非线性 ReLU 层来提高模型的表达能力。卷积层之后的最大池化缩小了输入体积,全连接层之后的 dropout 充当正则化器。注意,我们没有在最后一个全连接层之后包含 softmax 层,因为我们使用的损失函数在内部应用 softmax。每层的详细信息可以在 教程 中找到。 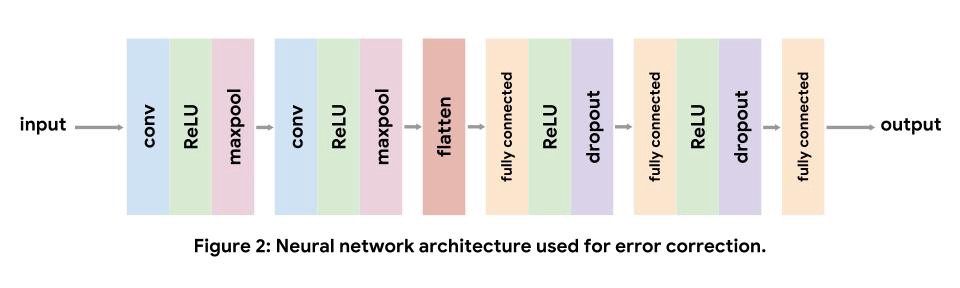
方法 1:单个读的错误校正
为了校正测序读中的错误,我们可以使用深度学习来训练一个神经网络,该网络可以解决一个更通用的任务:填补 DNA 序列中的缺失碱基。这种方法的目标是开发一个模型,该模型能够理解 DNA 序列的语法。仅靠真实序列的语法可能不足以开发出一个可用于生产环境的解决方案。尽管如此,这仍然是一个简单的示例应用程序。

出于教学目的,我们将问题简化为以下几种情况:
- 仅考虑具有替换错误的区域,忽略插入缺失错误
- 仅考虑没有已知变异的区域
我们可以使用参考基因组的区域来训练神经网络。该网络的输入是固定长度的 DNA 序列,以我们想要预测的碱基为中心。网络的输出是所有可能碱基的分布,最终预测是概率最高的碱基。标签集使用参考基因组中观察到的碱基生成。由于我们只使用映射到没有已知真实变异的区域的读,因此我们可以明确地将参考基因组中存在的碱基表示为标签。
我们通过将参考基因组分成固定长度的非重叠部分来生成输入序列。在训练、评估和测试时,我们通过将参考序列中的碱基归零来模拟缺失的碱基,如图 3 所示(位置 5)。除了使用参考基因组来模拟缺失数据之外,我们还可以将这种模型应用于测序读中的数据,特别是质量分数低于阈值值的碱基。
方法 2:基于共识的错误校正
错误校正的最终目标是确定底层 DNA 序列,而不是校正单个读。在本节中,我们通过聚合序列堆积来使用多个读的共识,直接确定 DNA 序列,而无需校正单个读的中间步骤。下图 4 展示了堆积的示例。注意,该图仅显示落在窗口内的读的部分。

出于教学目的,我们将问题简化为以下几种情况:
- 仅考虑具有替换错误的区域,忽略插入缺失错误
- 仅考虑没有已知变异的区域

与第一种方法不同,我们没有使用参考基因组来训练该模型。相反,我们的训练数据来自映射的 Illumina HiSeq 读。该网络的输入是映射读中观察到的归一化碱基计数矩阵,以我们想要预测的正确碱基的位置为中心。
Clairvoyante(用于变异调用的神经网络)的作者以及
Jason Chin 的示例方法 中使用了类似的特征化。网络的输出是所有可能碱基的分布,最终预测是概率最高的碱基。与第一种方法类似,标签集使用参考基因组中观察到的碱基生成。我们使用包含错误的示例(堆积中至少有一个读与中心位置的参考不匹配)和不包含错误的示例(堆积中的所有读都与中心位置的参考匹配)的混合示例。

结论
配套教程 实现了本文中介绍的第二种方法。虽然我们开发的示例还不够复杂,无法部署到生产环境中,但我们希望它们能帮助开发者学习如何在基因组学中高效地应用 Nucleus 和深度学习。







{kind=link}