https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjUWHnA_7lacHU7_YN1pyossotQN6g0udFkz7Y8qrFrpI9aTmrikKwiH6m0zLR4cawYIuvkClpO6uIlAJyCHiEGwYVx0vogaXbda9SyKXtgh5c7FbNELTzjwcLBPFFOthhYCwEk1Hv5P8Q/s1600/mentalmodel.png
由 Josh Gordon 发布
我最喜欢 TensorFlow 2.0 的一点是它提供了多个抽象级别,因此您可以为您的项目选择合适的抽象级别。在本文中,我将解释在创建神经网络时可以使用两种风格之间的权衡。第一种是符号式风格,您通过操作图层图来构建模型。第二种是命令式风格,您通过扩展类来构建模型。我将介绍这些风格,分享一些关于重要设计和可用性考虑因素的笔记,并以快速推荐结尾,以帮助您选择合适的风格。
符号式(或声明式)API
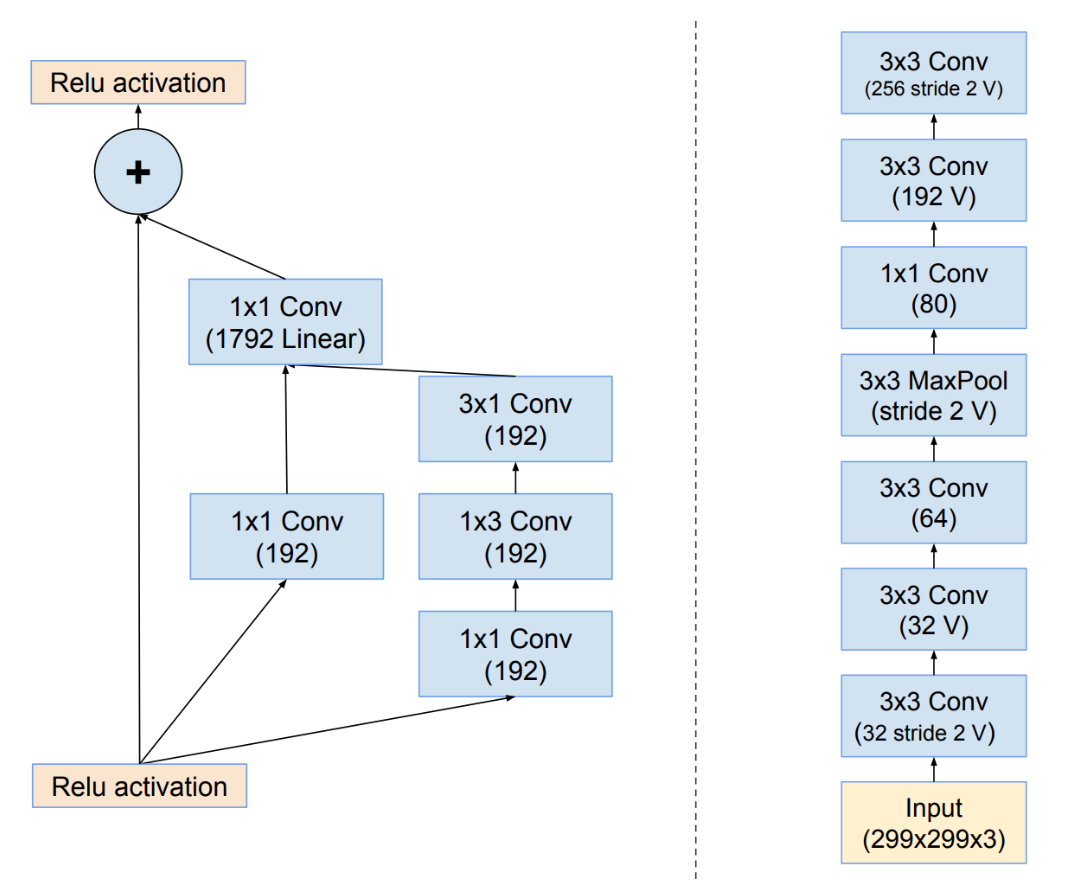
我们通常在想到神经网络时使用的思维模型是“图层图”,如下图所示。
此图可以是 DAG(如左侧所示)或堆栈(如右侧所示)。当我们以符号方式构建模型时,我们通过描述此图的结构来做到这一点。
如果这听起来很技术,您可能会惊讶地发现,如果您使用过 Keras,您已经拥有了这方面的经验。以下是一个使用
Keras 顺序式 API 以符号方式构建模型的快速示例。
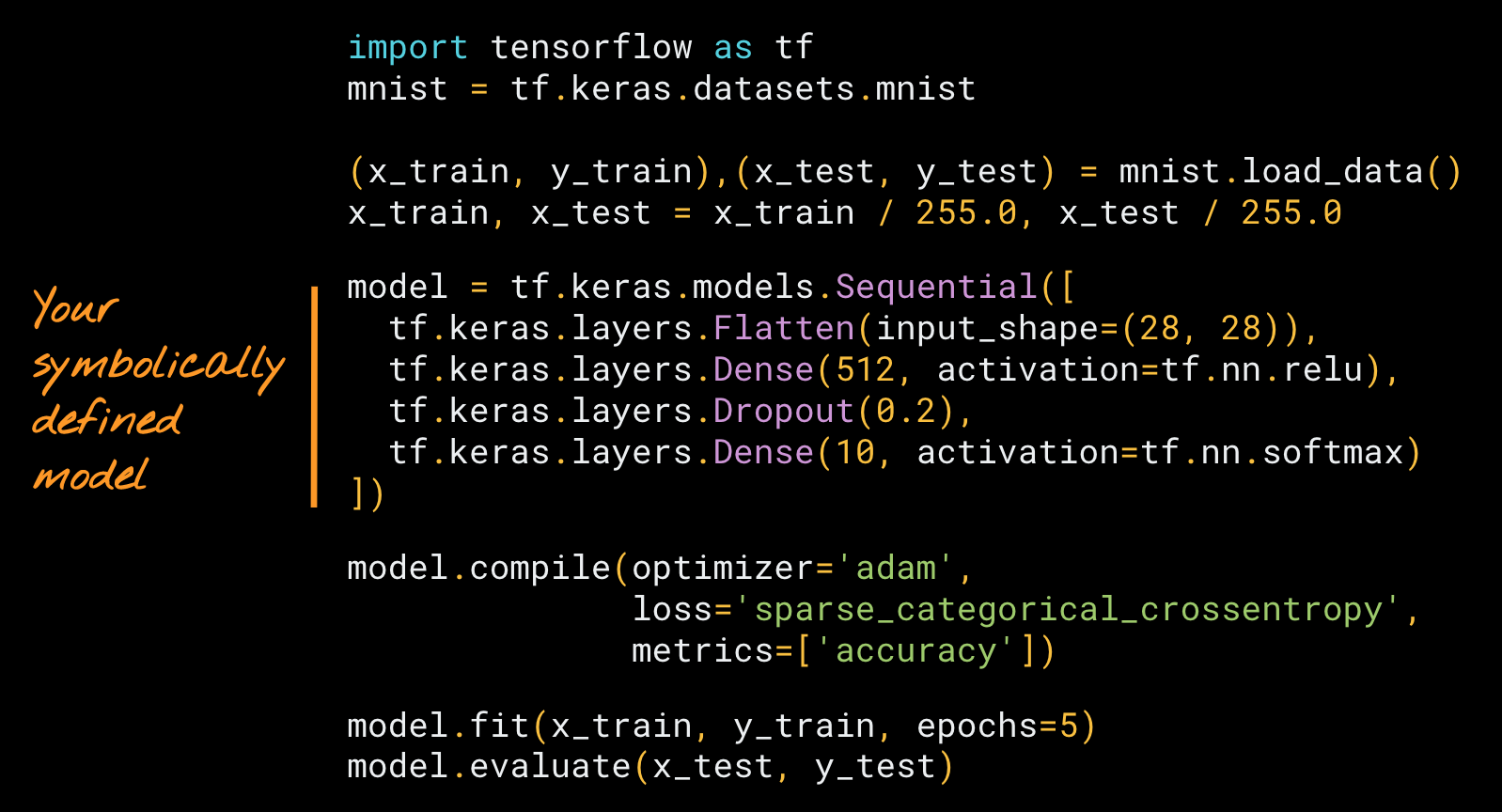 |
| 使用 Keras 顺序式 API 以符号方式构建的神经网络。您可以 在这里 运行此示例。 |
在上面的示例中,我们定义了一个图层堆栈,然后使用内置的训练循环
model.fit 对其进行了训练。
使用 Keras 构建模型就像“将乐高积木拼在一起”一样容易。为什么?除了匹配我们的思维模型之外,出于稍后讨论的技术原因,以这种方式构建的模型易于调试,这得益于框架提供的周到的错误消息。
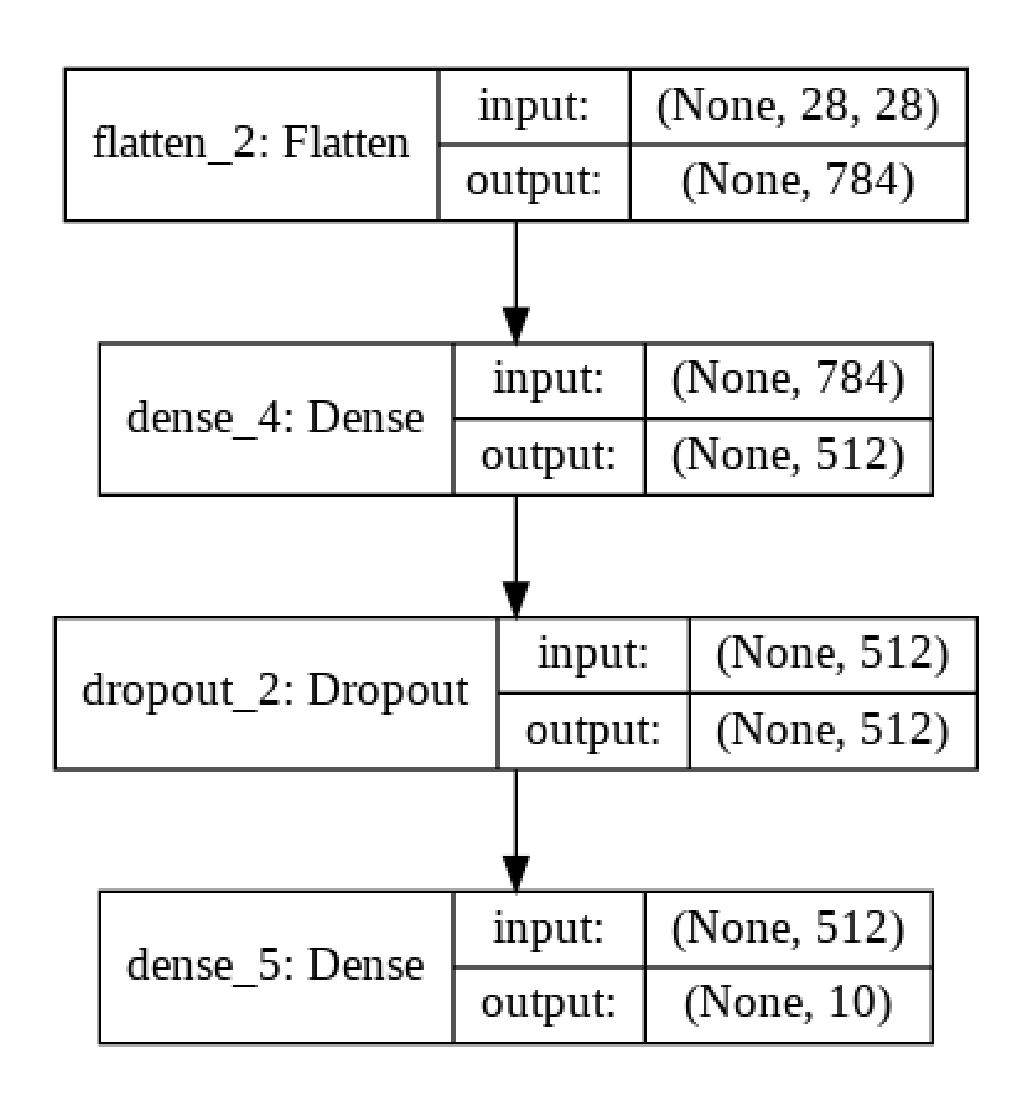 |
| 一个显示上面代码创建的模型的图(使用 plot_model 构建,您可以在此帖子的下一个示例中重复使用代码片段)。 |
TensorFlow 2.0 提供了另一个符号式模型构建 API:Keras 函数式 API。顺序式 API 用于堆栈,您可能已经猜到了,函数式 API 用于 DAG。
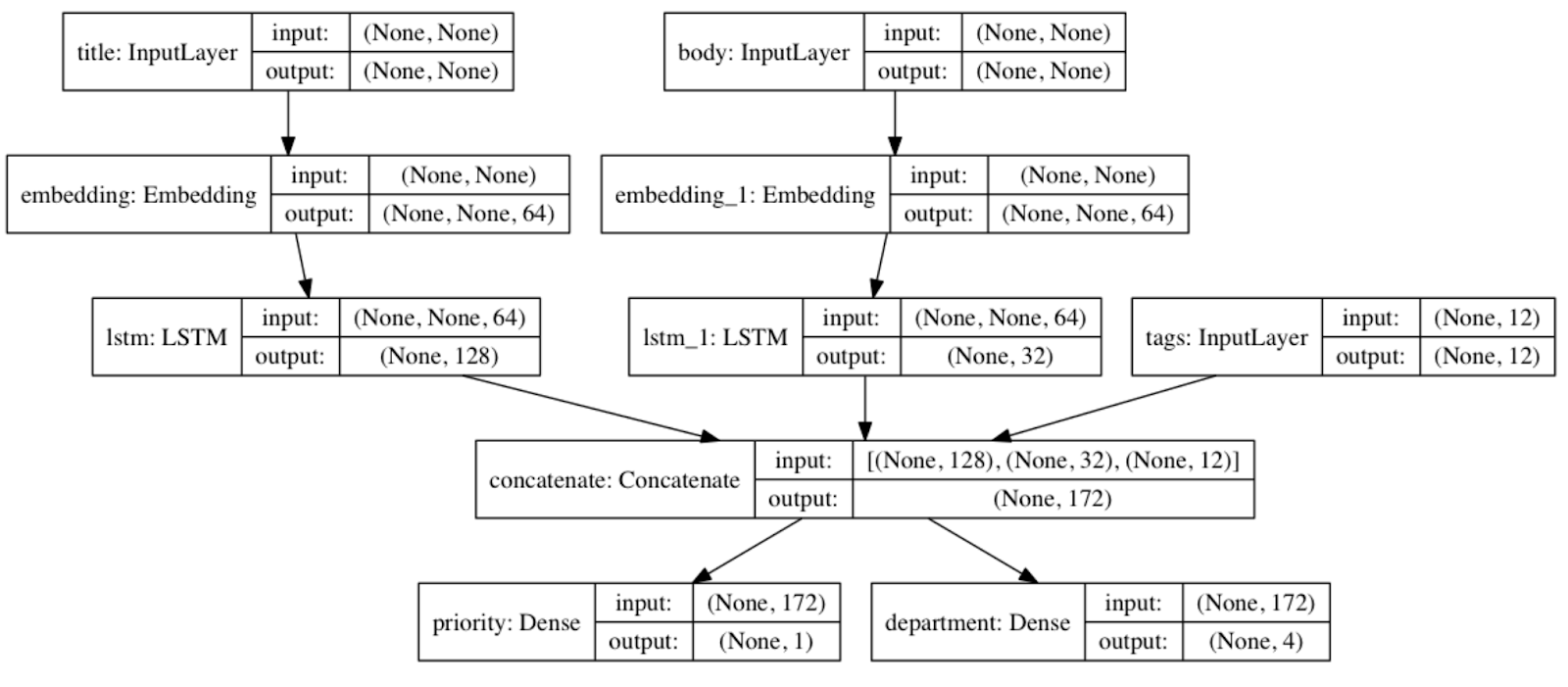 |
| 一个使用函数式 API 创建多个输入/多个输出模型的快速 示例。 |
函数式 API 是一种创建更灵活模型的方法。它可以处理非线性拓扑、具有共享层的模型以及具有多个输入或输出的模型。基本上,函数式 API 是一组用于构建这些图层图的工具。我们现在正在为此风格编写几个新的教程。
您可能已经体验过其他符号式 API。例如,TensorFlow v1(和 Theano)提供了更底层的 API。您将通过创建运算符图来构建模型,然后编译并执行这些运算符图。有时,使用此 API 会感觉您正在直接与编译器进行交互。对于许多人(包括作者)来说,使用它很困难。
相比之下,在 Keras 中,抽象级别与我们的思维模型相匹配:图层图,就像乐高积木一样拼在一起。这感觉起来很自然,而且它是我们正在 TensorFlow 2.0 中标准化的模型构建方法之一。我将现在描述另一种方法(您很有可能也使用过它,或者很快就有机会尝试它)。
命令式(或模型子类化)API
在命令式风格中,您编写模型的方式就像编写 NumPy 一样。以这种风格构建模型感觉就像面向对象的 Python 开发。以下是一个子类化模型的快速示例。
从开发人员的角度来看,其工作原理是您扩展框架定义的模型类,实例化您的图层,然后以命令式方式编写模型的前向传播(反向传播会自动生成)。
TensorFlow 2.0 通过 Keras
子类化 API 开箱即用地支持这一点。它与顺序式 API 和函数式 API 一起,是您在 TensorFlow 2.0 中开发模型的推荐方法之一。
虽然这种风格对 TensorFlow 来说是新的,但您可能会惊讶地发现,它是在 2015 年由
Chainer 引入的(时间过得真快!)。从那时起,许多框架都采用了类似的方法,包括 Gluon、PyTorch 和 TensorFlow(使用 Keras 子类化)。令人惊讶的是,以这种风格在不同框架中编写的代码看起来非常相似,以至于可能难以
区分!
这种风格为您提供了极大的灵活性,但它也带来了并非显而易见的可用性和维护成本。稍后会详细介绍。
训练循环
以顺序式、函数式或子类化风格定义的模型可以通过两种方式进行训练。您可以使用内置的训练例程和损失函数(参见第一个示例,我们使用
model.fit 和
model.compile),或者,如果您需要自定义训练循环的额外复杂性(例如,如果您想编写自己的梯度裁剪代码)或损失函数,您可以像下面这样轻松地做到这一点。
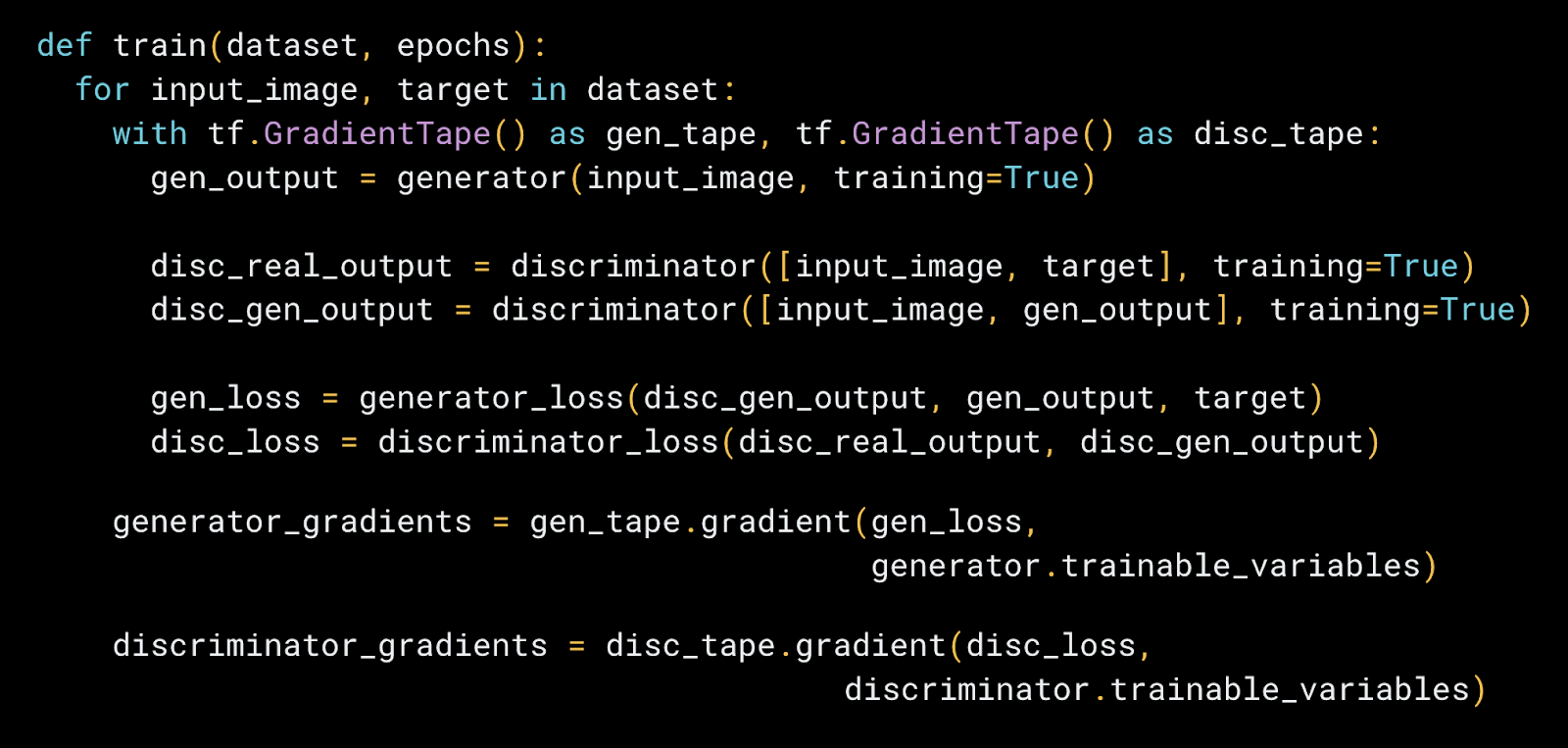 |
| 一个用于 Pix2Pix 的自定义训练循环和损失函数的示例。 |
这两种方法都非常重要,可以帮助降低代码复杂度和维护成本。基本上,您可以根据需要使用额外的复杂性,而在不需要时,则可以使用内置方法,并将时间花在研究或项目上。
现在我们已经了解了符号式风格和命令式风格,让我们来看看它们的权衡。
符号式 API 的优点和局限性
优点
使用符号式 API,您的模型是一个类似图的数据结构。这意味着您的模型可以被检查或总结。
- 您可以将其作为图像绘制以显示图(使用
keras.utils.plot_model),或者简单地使用 model.summary() 来查看图层的描述、权重和形状。
同样,在将图层拼在一起时,库设计者可以运行广泛的图层兼容性检查(在构建模型时,以及在执行之前)。
- 这类似于编译器中的类型检查,可以大大减少开发人员的错误。
- 大多数调试将在模型定义阶段进行,而不是在执行期间。您有保证,任何编译的模型都可以运行。这可以加快迭代速度,并简化调试过程。
符号式模型提供一致的 API。这使它们易于重用和共享。例如,在迁移学习中,您可以访问中间图层激活以从现有模型构建新的模型,如下所示。
from tensorflow.keras.applications.vgg19 import VGG19
base = VGG19(weights=’imagenet’)
model = Model(inputs=base.input,
outputs=base_model.get_layer(‘block4_pool’).output)
image = load(‘elephant.png’)
block4_pool_features = model.predict(image)
符号式模型由数据结构定义,这使得它们很自然地可以复制或克隆。
- 例如,顺序式 API 和函数式 API 为您提供了
model.get_config()、model.to_json()、model.save()、clone_model(model),以及从数据结构(无需访问用于定义和训练模型的原始代码)重新创建相同模型的能力。
虽然精心设计的 API 应该匹配我们对神经网络的思维模型,但同样重要的是要匹配我们作为程序员的思维模型。对于我们中的许多人来说,这就是命令式编程风格。在符号式 API 中,您正在操作“符号张量”(这些是尚未保存任何值的张量)来构建您的图。Keras 顺序式 API 和函数式 API “感觉”起来像命令式 API。它们的设计使得许多开发人员没有意识到他们一直在以符号方式定义模型。
局限性
当前一代的符号式 API 最适合开发模型,这些模型是图层的定向无环图。这在实践中涵盖了大多数用例,但有一些特殊的用例不适合这种简洁的抽象,例如,动态网络,如树形 RNN 和递归网络。
这就是 TensorFlow 还提供命令式模型构建 API 风格(Keras 子类化,如上所示)的原因。您可以使用顺序式 API 和函数式 API 中所有熟悉的图层、初始化器和优化器。这两种风格也完全可互操作,因此您可以混合匹配(例如,您可以在另一个模型类型中嵌套一个模型类型)。您可以使用一个符号式模型并在子类化模型中将其用作一个图层,反之亦然。
命令式 API 的优点和局限性
优点
您的前向传播以命令式方式编写,这使得您可以轻松地用自己的实现替换库实现的部分(例如,图层、激活函数或损失函数)。这感觉起来很自然,而且是深入了解深度学习基本原理的绝佳方法。
- 这使得您可以轻松地快速尝试新想法(DL 开发工作流程变得与面向对象的 Python 一样),对于研究人员来说尤其有用。
- 使用 Python,您也可以轻松地在模型的前向传播中指定任意控制流。
命令式 API 为您提供了最大的灵活性,但它也有一定的成本。我也很喜欢以这种风格编写代码,但我想花点时间强调一下它的局限性(了解权衡很重要)。
局限性
重要的是,当使用命令式 API 时,您的模型由类方法的主体定义。您的模型不再是一个透明的数据结构,而是一个不透明的字节码片段。当使用这种风格时,您是在牺牲可用性和可重用性以换取灵活性。
调试在执行期间进行,而不是在定义模型时进行。
- 几乎没有对输入或层间兼容性进行检查,因此当使用这种风格时,许多调试负担从框架转移到了开发人员身上。
命令式模型可能更难重用。例如,您无法使用一致的 API 访问中间图层或激活函数。
- 相反,提取激活函数的方法是编写一个具有新的调用(或前向)方法的新类。这最初写起来可能很有趣,而且很简单,但如果没有标准,它可能会成为技术债务的来源。
命令式模型也更难检查、复制或克隆。
- 例如,
model.save()、model.get_config() 和 clone_model 不适用于子类模型。 同样,model.summary() 只能提供一个层列表(不提供关于它们如何连接的信息,因为这是不可访问的)。
机器学习系统中的技术债务
重要的是要记住,模型构建只是实际机器学习工作中的一小部分。 以下是我最喜欢的关于该主题的插图之一。 模型本身(你在代码中指定层、训练循环等的部分)是中间的微型方框。
符号定义的模型在可重用性、调试和测试方面具有优势。 例如,在教学中 - 如果学生使用 Sequential API,我可以立即调试他们的代码。 当他们使用子类模型(无论框架如何)时,则需要更长的时间(错误可能更微妙,并且类型很多)。
结束语
TensorFlow 2.0 开箱即用地支持这两种风格,因此您可以为您的项目选择合适的抽象级别(和复杂性)。
- 如果您的目标是易用性、低概念开销,并且您喜欢将模型视为层图:使用 Keras Sequential 或 Functional API(就像将乐高积木拼在一起)和内置的训练循环。 对于大多数问题来说,这是正确的方法。
- 如果您喜欢将模型视为面向对象的 Python/Numpy 开发人员,并且您优先考虑灵活性和可破解性,那么 Keras Subclassing 是适合您的 API。
我希望这将是一个有用的概述,感谢您的阅读! 要了解有关 TensorFlow 2.0 堆栈的更多信息,除了这些模型构建 API 之外,请查看
这篇文章。 要了解更多关于 TensorFlow 和 Keras 之间的关系,请前往
这里。