https://blog.tensorflowcn.cn/2018/07/move-mirror-ai-experiment-with-pose-estimation-tensorflow-js.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiCKDbHm-J8K9uoEjVaKLMxILOeo2sATU_5PhMwRKuzZ3Y_zdQx7mxbFYn8gihkYiBd8WDbqaoEH1rygAMPmHlr1fkSS8P8ciQkmqUa6FpRsFt1BrL6cnBmKqASIXqE4mWIVuckvYFyLms/s1600/movemirror1.gif
由 Jane Friedhoff 和 Irene Alvarado 发表,Google 创意实验室创意技术专家
姿势估计,或从图像数据中检测人类及其姿势的能力,是机器学习和计算机视觉中最令人兴奋——也是最困难的主题之一。最近,谷歌分享了
PoseNet:一个最先进的姿势估计模型,可以从图像数据中提供高度准确的姿势数据(即使这些图像模糊、低分辨率或黑白)。这就是促使我们在第一时间为网络创建此姿势估计库的实验故事。
几个月前,我们对一个名为
Move Mirror 的有趣实验进行了原型设计,该实验可让您通过四处走动来探索浏览器中的图像。该实验创造了一种独特的翻页书般的体验,它会跟踪您的动作并以各种人类运动的图像(从运动和舞蹈到武术、表演等等)反映这些动作。我们希望在网络上发布体验,让其他人玩它,了解机器学习,并与朋友分享体验。不幸的是,我们遇到了一个问题:不存在公开可访问的针对网络的姿势估计模型。
通常,使用姿势数据意味着要么访问特殊硬件,要么具备 C++/Python 计算机视觉库的经验。因此,我们看到了一个独特的机会,可以通过将内部模型移植到
TensorFlow.js(一个允许您在浏览器中运行机器学习项目的 Javascript 库)来使姿势估计更广泛地可用。我们组建了一支团队,花费了几个月时间开发库,最终发布了
PoseNet,这是一个开源工具,允许任何网络开发人员在浏览器中玩弄基于身体的交互,完全在浏览器中完成,无需特殊的相机或 C++/Python 技能。
随着 PoseNet 的发布,我们终于可以发布
Move Mirror ——一个项目,证明了实验和游戏可以为严肃的工程工作增加价值。只有通过研究、产品
和创意团队之间的真正协作,我们才能构建 PoseNet 和 Move Mirror。

 |
| Move Mirror 是一款 AI 实验,可以找到您的姿势,并将您的动作与来自世界各地的数千张图像进行匹配。 |
继续阅读,深入了解我们如何进行实验、我们对浏览器中的姿势估计感到兴奋的原因以及我们对未来想法的期待。
什么是姿势估计?什么是 posenet?
正如您可能猜到的那样,姿势估计是一个相当复杂的问题:人类的形状和大小各不相同;有很多关节需要跟踪(以及这些关节在空间中可以有多种不同的连接方式);而且通常会在其他人和/或物体周围,导致视觉遮挡。有些人使用辅助设备,如轮椅或拐杖,这些设备可能会阻挡相机对身体的视野;其他人可能没有某些四肢;还有其他人可能具有非常不同的比例。我们希望我们的机器学习模型能够理解并智能地推断所有这些不同身体的数据。
 |
| 在这里,您可以看到 PoseNet 对使用辅助设备(如手杖、轮椅和假肢)的人员的关节检测结果。 |
过去,技术人员使用特殊相机和传感器(如立体图像、动作捕捉服和红外相机)以及可以从二维图像中提取姿势估计的计算机视觉技术(如
OpenPose)来解决姿势估计问题。这些解决方案虽然有效,但往往需要昂贵且分布不广的技术,或者需要熟悉计算机视觉库以及 C++ 或 Python。这使得普通开发人员难以快速入门
使用有趣的姿势实验。
当我们第一次遇到 PoseNet 时,它可以通过一个简单的网络 API 获得,这非常令人兴奋。突然之间,我们可以在 Javascript 中快速轻松地对姿势估计实验进行原型设计。我们所要做的就是向内部端点发送一个带有图像 base64 数据的 HTTP POST 请求——API 端点将几乎没有延迟地向我们发送姿势数据。这极大地降低了进行小型探索性姿势实验的入门门槛:只需几行 JavaScript、一个 API 密钥,我们就完成了!但当然,并非每个人都有能力运行自己的 PoseNet 后端,而且(合理地)并非每个人都愿意将自己的照片发送到中央服务器。我们如何才能让人们能够运行自己的姿势实验,而无需依赖我们的服务器或其他任何人的服务器?
我们意识到,这是一个将 TensorFlow.js 连接到 PoseNet 的绝佳机会。TensorFlow.js 允许用户直接在浏览器中运行机器学习模型——无需服务器。通过将 PoseNet 移植到 TensorFlow.js,任何拥有配备网络摄像头的台式电脑或手机的人都可以直接在网络浏览器中体验和玩弄这项技术,而无需担心低级计算机视觉库
或设置复杂的后台和 API。与 TensorFlow.js 团队的
Nikhil Thorat 和
Daniel Smilkov、Google 研究人员
George Papandreou 和
Tyler Zhu 以及
Dan Oved 密切合作,我们能够将 PoseNet 模型的一个版本移植到 TensorFlow.js。(您可以在
此处 阅读有关此过程的更多信息。)
一些让我们对 TensorFlow.js 中的 PoseNet 感到非常兴奋的事情
- 无处不在/可访问性:大多数开发人员都可以访问文本编辑器和网络浏览器,使用 PoseNet 就像在 HTML 文件中包含两个脚本标签一样简单——无需进行复杂的服务器设置。您也不需要任何特殊的超高分辨率或红外相机或传感器来获取数据——事实上,我们发现 PoseNet 在低分辨率、黑白和老式照片上仍然效果很好。
- 可分享性:由于所有内容都可以在浏览器中运行,因此 TensorFlow.js PoseNet 实验也可以在浏览器中轻松共享。无需创建特定于操作系统的构建——只需上传您的网页即可。
- 隐私:由于所有姿势估计都可以在浏览器中完成,这意味着您的图像数据永远不会离开您的计算机。与其将您的照片发送到天空中的某台服务器上,以便在中央服务上进行姿势分析(例如,当您使用可能无法控制或可能失败或出现任何问题的视觉 API 时),您可以完全在您的设备上进行所有姿势估计,控制您的图像去向。使用 Move Mirror,我们将 PoseNet 输出的 (x,y) 关节点数据与我们后端的姿势库进行匹配——但您的图像完全保留在您的计算机上。
好了,技术谈话就到这里,让我们谈谈设计吧!
设计和灵感
我们花了几个星期的时间玩弄不同的姿势估计原型。对于我们这些来自 C++ 或 Kinect 黑客的人来说,仅仅看到我们的骨骼在
我们的浏览器中,使用我们的网络摄像头反映回来,本身就是一个非常棒的演示。在最终确定成为
Move Mirror的概念之前,我们玩弄了轨迹、木偶以及各种其他愚蠢的东西。听到谷歌创意实验室中的许多人对搜索和探索感兴趣,这可能并不令人惊讶。在讨论我们可以用姿势估计做什么时,我们被能够通过姿势搜索档案的想法所吸引。如果您能摆出姿势并获得您正在做的舞蹈动作的结果,那会怎么样?或者——也许更有趣的是——如果您摆出姿势并获得相同的结果,但与您正在做的事情完全无关,那会怎么样?我们如何才能在人类运动的广度(从武术到烹饪到滑雪到婴儿迈出第一步)中找到奇怪的、意外的联系?这可能会让我们感到惊讶、高兴和发笑?
我们从
Land Lines(其中使用手势数据来探索 Google Earth 中的相似线)和 Cooper Hewitt
Gesture Match(这是一个使用姿势匹配来推荐档案中项目的现场安装)等项目中汲取灵感。然而,从审美角度来看,我们被更快的、更实时的方式吸引。我们喜欢这样的想法:有一股持续的图像流响应您的动作,将来自各行各业的人们模糊地连接在一起,通过您的动作连接。受
The Johnny Cash Project 中使用的动画描绘和延时摄影以及 YouTube 上
自拍延时 的趋势的启发,我们决定全力以赴,在浏览器中攻克实时响应式姿势匹配——本身就是一个复杂的问题。
构建 Move Mirror
虽然 PoseNet 已经为我们完成了姿势估计,但我们仍然有很多事情需要弄清楚。核心体验就是找到与用户姿势匹配的图像,这样如果你笔直地站立,右臂举起,Move Mirror 就会找到一张有人笔直站立,右臂举起的照片。为此,我们需要三个组件:一个图像数据集,一个用于该数据集的搜索技术,以及一个姿势匹配算法。让我们把它分解并逐个分析。
构建数据集:寻找多样性
为了创建一个有用的数据集,我们必须寻找能集体涵盖人类运动巨大多样性的图像。如果数据集没有涵盖其他姿势,那么拥有 400 张一个人举起右臂站立的图像就没有意义。为了保持体验的一致性,我们还决定只找到全身图像。最终,我们授权了一组视频,我们认为这些视频不仅代表了各种各样的运动,而且还代表了一组不同的体型、肤色、文化和身体能力。我们将这些视频分成大约 80,000 张静止帧,然后使用 PoseNet 处理每张图像并存储相关的姿势数据。接下来,让我们讨论一下难点:姿势匹配和搜索。
 |
| 我们使用 PoseNet 解析了数千张图像。你会注意到,并非所有图像都被正确解析,因此我们丢弃了一些图像,最终得到一个包含大约 80,000 张图像的数据集。 |
姿势匹配:定义相似性的挑战
为了让 Move Mirror 工作,我们首先必须弄清楚如何定义 "匹配"。匹配是指当用户摆出一个姿势时,我们根据接收到的姿势数据返回的图像。当我们谈论从 PoseNet 输出的 "姿势数据" 时,我们指的是一组 17 个身体或面部部位,例如肘部或左眼,这些部位被称为 "关键点"。PoseNet 返回每个关键点相对于输入图像的 x 和 y 位置,以及相关的置信度分数(稍后详细介绍)。
 |
| PoseNet 在面部和身体上检测到 17 个姿势关键点。每个关键点都有三个重要的数据:一个 (x,y) 位置(表示 PoseNet 在输入图像中找到该关键点的像素位置)和一个置信度分数(PoseNet 对其猜测正确的信心程度)。 |
确定 "相似性" 的含义成为了我们的第一个障碍。我们应该如何决定用户的一组 17 个关键点与我们数据集中的一张图像的一组 17 个关键点有多相似?我们尝试了几种不同的相似性度量方法,并最终确定了两种效果较好的方法:余弦相似性和考虑关键点置信度分数的加权匹配。
匹配策略 #1:余弦距离
如果我们将每组 17 个关键点转换为一个向量,并将所有向量绘制在高维空间中,那么找到两个最相似姿势的任务将转化为在该高维空间中找到两个最接近的向量。这正是余弦距离允许我们做的事情。
余弦相似性 是衡量两个向量之间相似性的一个指标:它基本上测量了两个向量之间的夹角,如果两个向量完全相反,则返回 -1;如果两个向量完全相同,则返回 1。重要的是,它衡量的是方向,而不是幅度。
虽然我们谈论的是向量和角度,但这并不局限于图表上的线条:你可以使用余弦相似性来,例如,获得两个等长字符串之间的
数值相似性。(如果你曾经使用过
Word2Vec,那么你可能间接使用过余弦相似性。)事实上,这是一个非常有用的方法,可以将两个高维向量(两个长句子,或两个长数字数组)之间的关系简化为一个数字。
 |
| 一个简化的 Nish Tahir 的优秀示例。如果你不了解向量数学,也不要担心:重要的是要看到,我们能够将两个抽象的高维数据(5 维,对应 5 个独特的单词)转换为一个单一的、规范化的数字,代表它们的相似性。 |
我们的输入数据是 JSON,但我们可以很容易地将这些值压缩成一维数组,其中每个条目表示关键点的 X 或 Y 位置。只要我们保持结构的一致性和可预测性,生成的数组就可以以几乎相同的方式进行比较。所以这是我们的第一步:将数据从对象更改为数组。
 |
| 来自 PoseNet 的 JSON 片段,以及扁平化后的 X 和 Y 位置数组片段。(你会注意到,这个数组没有考虑置信度——我们稍后会讨论这个问题!) |
有了这个,我们就可以使用余弦相似性来获取我们输入的 34 个浮点数数组与我们数据库中的任何给定的 34 个浮点数数组之间的相似性度量。我们可以输入我们的两个长数组,并接收一个更容易解析的相似性分数,介于 -1 和 1 之间。现在,由于我们数据集中的所有图像都可能具有不同的宽度/高度,并且由于每个人都可能出现在图像的不同子集中(左上角、右下角、中心等),我们执行了两个额外的步骤,以便能够一致地比较数据
- 调整大小和缩放:我们使用每个人的边界框坐标对每张图像(以及相应的关键点坐标)进行裁剪和缩放,以达到一致的大小。
- 归一化:我们进一步归一化了结果关键点坐标,将其视为一个 L2 归一化向量数组。
具体来说,我们对第二步使用
L2 归一化,这意味着我们正在将向量缩放为单位范数(如果你将 L2 归一化向量中的每个元素平方并求和,则结果等于 1)。比较这两个图表,以了解归一化是如何转换向量的
 |
| 使用 L2 归一化缩放的向量 |
上面描述的两个步骤可以从视觉上理解如下
 |
| 规范化 Move Mirror 数据采取的步骤 |
有了归一化的关键点坐标(存储为向量数组),我们终于可以计算余弦相似度,并执行几个
计算,如下所示,得到一个可以解释为余弦距离的
欧几里得距离。公式如下
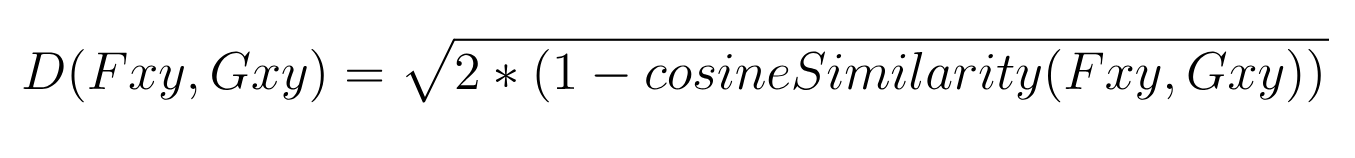
在上面的公式中,Fxy 和 Gxy 是两个在 L2 归一化后要比较的姿势向量。此外,Fxy 和 Gxy 只包含 17 个关键点中的每个关键点的 x 和 y 位置——不包含每个关键点的置信度分数。
Javascript 代码片段如下
// Great npm package for computing cosine similarity
const similarity = require('compute-cosine-similarity');
// Cosine similarity as a distance function. The lower the number, the closer // the match
// poseVector1 and poseVector2 are a L2 normalized 34-float vectors (17 keypoints each
// with an x and y. 17 * 2 = 32)
function cosineDistanceMatching(poseVector1, poseVector2) {
let cosineSimilarity = similarity(poseVector1, poseVector2);
let distance = 2 * (1 - cosineSimilarity);
return Math.sqrt(distance);
}
很酷吧?让匹配开始吧!
匹配策略 #2:加权匹配
好吧,几乎。这种方法仍然存在一个很大的缺陷。我们在上面的余弦相似性示例中的句子——"Jane 喜欢编程" 和 "Irene 喜欢编程"——是静态的:我们 100% 确信它们所代表的意义。但姿势估计并不像这样简单。实际上,当我们试图推断一个关节的位置时,我们几乎从未对它的位置有 100% 的把握。我们可以非常非常接近,但除非我们是一台 X 射线机,否则我们获得完全 100% 置信度的可能性很低。有时,我们根本无法看到一个关节,只能根据我们对人体的其他了解做出最佳猜测。
 |
| Posenet 为每个关键点返回一个置信度分数。模型预测具有更高置信度分数的关键点更准确。 |
因此,每个返回的关节数据也都有一个置信度分数。有时,我们对关节的位置非常自信(例如,如果我们可以清楚地看到它);其他时候,我们的信心非常低(例如,如果关节被切断或遮挡),以至于我们的数字必须带有 "耸肩表情符号" 作为免责声明。如果我们忽略这些置信度分数,我们就会失去关于我们数据的有价值的信息,我们可能会给那些我们并不十分确信的数据赋予过多的权重和重要性。这会产生噪声,导致一些非常奇怪和看似任意的匹配结果。
因此,虽然余弦距离技术很有用,并产生了良好的结果,但我们认为,我们可以通过加入置信度分数(该关节实际位于 PoseNet 预期位置的概率)来做得更好。具体来说,我们希望能够对关节数据进行加权,以便低置信度关节对距离度量的影响小于高置信度关节。Google 研究员
George Papandreou 和
Tyler Zhu 提供了一个公式,可以精确地做到这一点

在上面的公式中,F 和 G 是两个在 L2 归一化后要比较的姿势向量(在上一节中解释)。Fck 是 F 的第 k 个关键点的置信度分数。Fxy 和 Gxy 表示每个向量中第 k 个关键点的 x 和 y 位置。如果你不理解整个公式,也不要担心——重要的是要明白,我们正在使用关键点置信度分数来改进我们的匹配。下面的 Javascript 代码片段可能会更好地说明这一点
// poseVector1 and poseVector2 are 52-float vectors composed of:
// Values 0-33: are x,y coordinates for 17 body parts in alphabetical order
// Values 34-51: are confidence values for each of the 17 body parts in alphabetical order
// Value 51: A sum of all the confidence values
// Again the lower the number, the closer the distance
function weightedDistanceMatching(poseVector1, poseVector2) {
let vector1PoseXY = poseVector1.slice(0, 34);
let vector1Confidences = poseVector1.slice(34, 51);
let vector1ConfidenceSum = poseVector1.slice(51, 52);
let vector2PoseXY = poseVector2.slice(0, 34);
// First summation
let summation1 = 1 / vector1ConfidenceSum;
// Second summation
let summation2 = 0;
for (let i = 0; i < vector1PoseXY.length; i++) {
let tempConf = Math.floor(i / 2);
let tempSum = vector1Confidences[tempConf] * Math.abs(vector1PoseXY[i] - vector2PoseXY[i]);
summation2 = summation2 + tempSum;
}
return summation1 * summation2;
}
这种策略让我们得到了更准确的结果。即使人们的身体被遮挡或超出画面,它在找到与用户正在做的事情相似的姿势的图像方面也做得更好。
 |
| Move Mirror 尝试根据 PoseNet 估计的姿势找到匹配的图像。匹配精度取决于 PoseNet 的精度以及数据集的多样性。 |
大规模搜索姿势数据:80,000 张图像,约 15 毫秒
最后,我们必须弄清楚如何在规模上进行搜索和匹配。起初,对我们的匹配进行暴力搜索很容易:将一个传入的姿势与一个包含 10 个姿势的数据库中的每个条目进行比较,这不成问题。但当然,10 张图像是不够的:为了涵盖各种各样的运动,我们需要至少数万张图像。正如你可能预料到的,在一个包含 80,000 个条目的数据库中对每个条目运行距离函数,会导致结果不是实时的!所以我们的下一个问题是如何快速推断出哪些条目可以跳过,以及哪些条目实际上是相关的。我们越能自信地跳过条目,我们就越快能返回匹配结果。
我们从
Zach Lieberman 和
Land Lines 实验 中得到启发,并使用了一种名为“
vantage-point tree” 的数据结构(javascript 库
在这里)遍历我们的姿态数据。vantage-point tree 递归地将数据分成两类:距离某个 vantage-point 比阈值更近的数据和距离更远的数据。这种递归排序创建了一个可以遍历的树形数据结构。(如果你熟悉
K-D tree,这有点类似。你可以阅读更多关于 vantage-point tree 的详细内容
这里)。
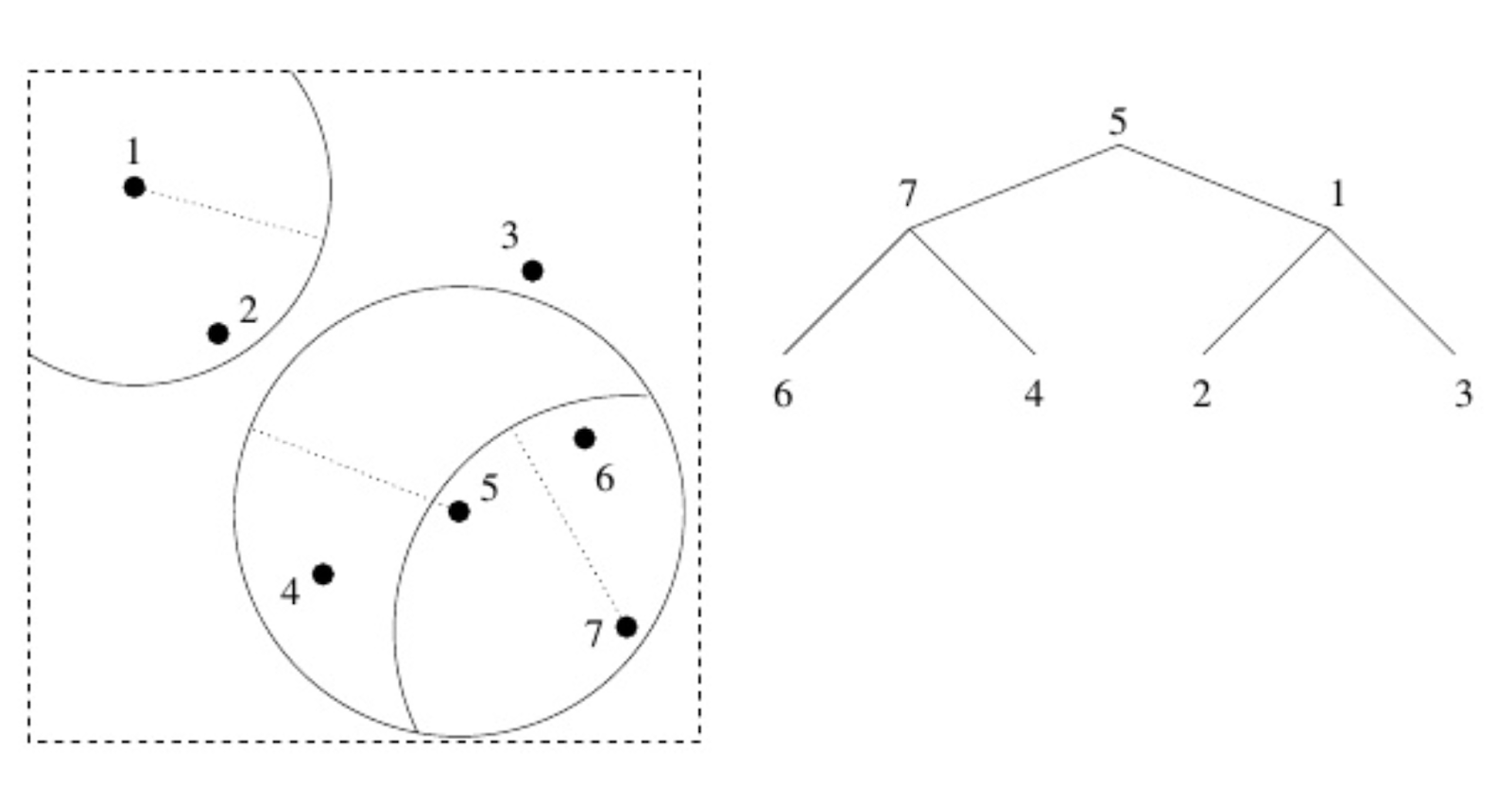
让我们更详细地讨论一下 vp tree。如果你不完全理解接下来的描述,也不用担心——重要的是理解一般原理。我们在数据空间中有一组点,并选择一个点(可以随机选择!)作为根节点(在上图中,它是点 5)。我们在它周围画一个圆,所以一些数据在圆内,一些数据在圆外。然后我们选择两个新的 vantage-point:一个在圆内,一个在圆外(这里,1 和 7)。我们将这两个点作为第一个 vantage-point 的子节点添加。然后,对于这两个点,我们做完全相同的事情:在它们周围画一个圆,选择一个点在圆内,一个点在圆外,使用这些 vantage-point 作为子节点,依此类推。关键是,如果你从点 5 开始,发现点 7 比点 1 更接近你想去的地方,你就知道不仅可以丢弃点 1,而且还可以丢弃它的子节点。
使用这种树形结构,我们不再需要单独比较每一个条目:如果传入的姿态与 vantage-tree 中的某个节点不够相似,我们可以假设该节点的任何子节点都不会那么相似。与对所有数据库条目进行暴力搜索相比,我们可以通过遍历树来搜索——这样可以安全且自信地切断我们知道不相关的数据库的巨大部分。
vantage-point tree 让我们能够极大地提高搜索结果速度,并实现我们期望的实时体验。这是一个很难实现的目标,但使用它的体验和我们期望的一样神奇。
如果你想自己尝试这些技术,这里有一个使用 javascript 库
vptree.js 构建 vp tree 的 javascript 代码的要点。虽然我们使用了自己的距离匹配函数,但我们鼓励你探索和玩弄其他可能性——你只需要在构建 vp tree 时替换传递给它的距离函数。
const similarity = require('compute-cosine-similarity');
const VPTreeFactory = require('vptree');
const poseData = [ […], […], […], …] // an array with all the images’ pose data
let vptree ; // where we’ll store a reference to our vptree
// Function from the previous section covering cosine distance
function cosineDistanceMatching(poseVector1, poseVector2) {
let cosineSimilarity = similarity(poseVector1, poseVector2);
let distance = 2 * (1 - cosineSimilarity);
return Math.sqrt(distance);
}
function buildVPTree() {
// Initialize our vptree with our images’ pose data and a distance function
vptree = VPTreeFactory.build(poseData, cosineDistanceMatching);
}
findMostSimilarMatch(userPose) {
// search the vp tree for the image pose that is nearest (in cosine distance) to userPose
let nearestImage = vptree.search(userPose);
console.log(nearestImage[0].d) // cosine distance value of the nearest match
// return index (in relation to poseData) of nearest match.
return nearestImage[0].i;
}
// Build the tree once
buildVPTree();
// Then for each input user pose
let currentUserPose = [...] // an L2 normalized vector representing a user pose. 34-float array (17 keypoints x 2).
let closestMatchIndex = findMostSimilarMatch(currentUserPose);
let closestMatch = poseData[closestMatchIndex];
在
Move Mirror 中,我们最终只使用了与用户姿态最匹配的图像。但在调试时,我们实际上可以遍历树并找到,比如,前 10 个或前 20 个最接近的图像。我们实际上构建了一个调试工具来以这种方式探索数据,它在帮助我们探索数据集中的漏洞方面非常有用。
 |
| 我们的调试工具,以及按最相似到最不相似(由上述算法确定)排序的结果图像。 |
未来
我们非常享受在游泳者、厨师、舞者和婴儿中找到自己,这种技术可以带我们去更多有趣的地方。想象一下,在你的客厅(以及你的浏览器的隐私保护下)搜索舞蹈动作、经典电影片段或音乐视频的档案!或者想象一下将它反过来,使用姿态估计来帮助指导家庭瑜伽锻炼或物理治疗。Move Mirror 只是我们希望未来会出现的令人愉快且易于访问的浏览器姿态实验的寒武纪大爆发的一个实验。
尝试在
Move Mirror 网站上摆个姿势。如果你有兴趣为
TensorFlow.js 玩弄 PoseNet,你可以查看
仓库 和一篇配套的
博客文章。你还会在
Experiments with Google 网站上找到更多实验。我们很乐意看到你做了什么——别忘了使用 #tensorflowjs 和 #posenet 分享你的精彩项目!