https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhGNfQavEiYMs5I_9uJf03gy79HVgHd-dJUV-C7mgOMs6GF5Ll0s55CTORGS-PfiZ72Sc6WJQhbktAPc5Q8CuqTfRx1x4Fju779bSb_gE1F_2hjvnj61OcWDrvoRfInJsB18-SvxVtvTVY/s320/p1.gif
发布者:Dan Oved,Google Creative Lab 自由创意技术人员,纽约大学 ITP 研究生。 编辑和插图:Irene Alvarado,创意技术人员和 Alexis Gallo,Google Creative Lab 自由平面设计师。
更新:PoseNet 2.0 现已发布,其准确性得到提升(基于 ResNet50),并包含新的 API、权重量化和对不同图像尺寸的支持。默认情况下,它在 2018 年 13 英寸 MacBook Pro 上以 10 fps 的速度运行。有关更多详细信息,请参阅 Github
自述文件。
我与 Google Creative Lab 合作,很高兴宣布发布
TensorFlow.js 版本的
PoseNet,这是一个机器学习模型,允许在浏览器中进行实时人体姿态估计。请尝试
此处 的实时演示。
 |
| PoseNet 可以使用单姿态算法检测图像和视频中的人体图形... |
那么,姿态估计到底是什么呢?姿态估计是指计算机视觉技术,它可以检测图像和视频中的人体图形,以便确定例如某人的肘部在图像中的位置。需要说明的是,这项技术
不识别图像中的人物 - 姿态检测与任何个人身份信息无关。该算法只是估计身体关键关节的位置。
 |
| ... 或者多姿态算法 - 所有这些都可以在浏览器中完成。 |
好的,为什么这令人兴奋呢?姿态估计有许多用途,从
互动装置(
响应 身体)到
增强现实、
动画、
健身用途等等。我们希望此模型的易用性能够激励更多开发人员和创客尝试并将姿态检测应用于他们自己独特的项目。虽然许多替代姿态检测系统已
开源,但它们都需要专用硬件和/或摄像头,以及相当多的系统设置。
使用在
TensorFlow.js 上运行的 PoseNet,任何拥有配备网络摄像头的桌面电脑或手机的人都可以直接在 Web 浏览器中体验这项技术。由于我们已经开源了此模型,因此 JavaScript 开发人员只需几行代码就可以对其进行调整并使用此技术。更重要的是,这实际上有助于保护用户隐私。由于 TensorFlow.js 上的 PoseNet 在浏览器中运行,因此不会有任何姿态数据离开用户电脑。
在我们深入了解如何使用此模型的细节之前,向所有使该项目成为可能的人员表示感谢:
George Papandreou 和
Tyler Zhu(Google 的研究人员,撰写了
《Towards Accurate Multi-person Pose Estimation in the Wild》 和
《PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model》 两篇论文),以及
Nikhil Thorat 和
Daniel Smilkov(Google Brain 团队的工程师,负责
TensorFlow.js 库)。
PoseNet 入门
PoseNet 可用于估计
单个姿态或
多个姿态,这意味着该算法有一个版本可以检测图像/视频中的一人,另一个版本可以检测图像/视频中的多人。为什么会有两个版本?单人姿态检测器速度更快,更简单,但它要求图像中只有一名主体(稍后将详细介绍)。我们首先介绍单姿态检测器,因为它更容易理解。
从高层次来说,姿态估计包含两个阶段
- 输入的 RGB 图像通过卷积神经网络进行处理。
- 使用单姿态或多姿态解码算法从模型输出中解码姿态、姿态置信度得分、关键点位置和关键点置信度得分。
等等,这些关键字都代表什么?让我们回顾一下最重要的几个
- 姿态 - 在最高级别上,PoseNet 将返回一个姿态对象,其中包含关键点列表以及每个检测到的人物的实例级置信度得分。
 |
| PoseNet 为每个检测到的人物以及每个检测到的姿态关键点返回置信度值。图片版权:“Microsoft Coco:通用对象上下文数据集”,https://cocodataset.org |
- 姿态置信度得分 - 这是决定姿态估计总体置信度的指标。它介于 0.0 到 1.0 之间。它可以用来隐藏置信度得分不够高的姿态。
- 关键点 - 人体姿态的估计部分,例如鼻子、右耳、左膝、右脚等。它包含位置和关键点置信度得分。PoseNet 目前检测到 17 个关键点,如下面的图示所示
 |
| PoseNet 检测到的 17 个姿态关键点。 |
- 关键点置信度得分 - 这是决定估计的关键点位置是否准确的指标。它介于 0.0 到 1.0 之间。它可以用来隐藏置信度得分不够高的关键点。
- 关键点位置 - 在原始输入图像中检测到关键点的二维 x 和 y 坐标。
第 1 部分:导入 TensorFlow.js 和 PoseNet 库
我们投入了大量工作来抽象化模型的复杂性并将功能封装到易于使用的函数中。让我们来了解一下如何设置 PoseNet 项目的基本知识。
可以使用 npm 安装库
npm install @tensorflow-models/posenet
并使用 es6 模块导入
import * as posenet from '@tensorflow-models/posenet';
const net = await posenet.load();
或者通过页面中的捆绑包导入
<html>
<body>
<!-- Load TensorFlow.js -->
<script src="https://unpkg.com/@tensorflow/tfjs"></script>
<!-- Load Posenet -->
<script src="https://unpkg.com/@tensorflow-models/posenet">
</script>
<script type="text/javascript">
posenet.load().then(function(net) {
// posenet model loaded
});
</script>
</body>
</html>
第 2a 部分:单人姿态估计
 |
| 示例单人姿态估计算法应用于图像。图片版权:“Microsoft Coco:通用对象上下文数据集”,https://cocodataset.org |
如前所述,单姿态估计算法比两种算法中更简单,速度也更快。它的理想用例是在输入图像或视频中只有一人且处于中心位置的情况。缺点是如果图像中有多人,则两个人物的所有关键点很可能会被估计为同一单一姿态的一部分 - 也就是说,例如,人物 1 的左臂和人物 2 的右膝可能会被算法混淆为属于同一个姿态。如果输入图像可能包含多人,则应该使用多姿态估计算法。
让我们回顾一下单姿态估计算法的输入
- 输入图像元素 - 包含用于预测姿态的图像的 HTML 元素,例如视频或图像标签。重要的是,输入的图像或视频元素应该是正方形。
- 图像缩放因子 - 0.2 到 1 之间的数字。默认为 0.50。在将图像输入网络之前要将其缩放多少倍。将此数字设置得更低可以缩小图像并提高输入网络时的速度,但会降低准确性。
- 水平翻转 - 默认为 false。是否应水平翻转/镜像姿态。对于视频,如果视频默认情况下被水平翻转(例如,网络摄像头),并且希望姿态以正确的方向返回,则应将此设置为 true。
- 输出步幅 - 必须为 32、16 或 8。默认为 16。在内部,此参数会影响神经网络中各层的高度和宽度。从高层次来说,它会影响姿态估计的准确性和速度。输出步幅的值越低,准确性越高,但速度越慢;输出步幅的值越高,速度越快,但准确性越低。要查看输出步幅对输出质量的影响,最好的方法是使用 单姿态估计演示。
现在让我们回顾一下单姿态估计算法的输出
- 姿态,包含姿态置信度得分和 17 个关键点数组。
- 每个关键点都包含关键点位置和关键点置信度得分。同样,所有关键点位置都在输入图像空间中具有 x 和 y 坐标,并且可以直接映射到图像上。
以下简短的代码块展示了如何使用单姿态估计算法
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
const imageElement = document.getElementById('cat');
// load the posenet model
const net = await posenet.load();
const pose = await net.estimateSinglePose(imageElement, scaleFactor, flipHorizontal, outputStride);
{
"score": 0.32371445304906,
"keypoints": [
{ // nose
"position": {
"x": 301.42237830162,
"y": 177.69162777066
},
"score": 0.99799561500549
},
{ // left eye
"position": {
"x": 326.05302262306,
"y": 122.9596464932
},
"score": 0.99766051769257
},
{ // right eye
"position": {
"x": 258.72196650505,
"y": 127.51624706388
},
"score": 0.99926537275314
},
...
]
}
第 2b 部分:多人姿态估计
 |
| 示例多人姿态估计算法应用于图像。图片版权:“Microsoft Coco:通用对象上下文数据集”,https://cocodataset.org |
多人姿态估计算法可以估计图像中的多个姿态/人物。它比单姿态算法更复杂,速度也略慢,但它具有以下优势:如果图像中有多人,则检测到的关键点不太可能与错误的姿态相关联。因此,即使用例是检测单个人的姿态,此算法也可能更可取。
此外,此算法的一个吸引人的特性是,其性能不受输入图像中人物数量的影响。无论检测到 15 个人还是 5 个人,计算时间都将相同。
让我们回顾一下输入
- 输入图像元素 - 与单姿态估计相同
- 图像缩放因子 - 与单姿态估计相同
- 水平翻转 - 与单姿态估计相同
- 输出步幅 - 与单姿态估计相同
- 最大姿态检测 - 整数。默认为 5。要检测的最大姿态数量。
- 姿态置信度得分阈值 - 0.0 到 1.0。默认为 0.5。从高层次来说,这控制着返回的姿态的最小置信度得分。
- 非最大抑制 (NMS) 半径 - 以像素为单位的数字。从高层次来说,它控制了返回的姿势之间的最小距离。该值默认为 20,对于大多数情况来说可能没问题。如果调整姿势置信度得分不够好,则应该增加/减少该值以过滤掉不太准确的姿势。
让我们回顾一下输出
- 一个以姿势数组解析的 Promise。
- 每个姿势都包含与单人估计算法中描述的信息相同的信息。
这段简短的代码块展示了如何使用多人姿态估计算法
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
// get up to 5 poses
const maxPoseDetections = 5;
// minimum confidence of the root part of a pose
const scoreThreshold = 0.5;
// minimum distance in pixels between the root parts of poses
const nmsRadius = 20;
const imageElement = document.getElementById('cat');
// load posenet
const net = await posenet.load();
const poses = await net.estimateMultiplePoses(
imageElement, imageScaleFactor, flipHorizontal, outputStride,
maxPoseDetections, scoreThreshold, nmsRadius);
// array of poses/persons
[
{ // pose #1
"score": 0.42985695206067,
"keypoints": [
{ // nose
"position": {
"x": 126.09371757507,
"y": 97.861720561981
},
"score": 0.99710708856583
},
...
]
},
{ // pose #2
"score": 0.13461434583673,
"keypositions": [
{ // nose
"position": {
"x": 116.58444058895,
"y": 99.772533416748
},
"score": 0.9978438615799
},
...
]
},
...
]
如果你已经阅读到这里,你已经了解了开始使用 PoseNet
演示 的知识。这可能是一个很好的停止点。如果你想了解更多关于模型和实现的技术细节,我们邀请你继续阅读下面的内容。
好奇的思想:技术深入
在本节中,我们将深入探讨关于单人姿态估计算法的更多技术细节。从高层次来看,这个过程如下所示
 |
| 使用 PoseNet 的单人姿态检测流水线 |
需要注意的重要细节是,研究人员训练了 PoseNet 的
ResNet 和
MobileNet 模型。虽然 ResNet 模型具有更高的精度,但其庞大的尺寸和众多层会导致页面加载时间和推理时间对于任何实时应用来说都不理想。我们选择了 MobileNet 模型,因为它被设计用于在移动设备上运行。
重温单人姿态估计算法
处理模型输入:解释输出步幅
首先,我们将通过讨论输出步幅来介绍如何获取 PoseNet 模型输出(主要是热图和偏移向量)。
方便的是,PoseNet 模型对图像大小是不变的,这意味着它可以预测与原始图像相同比例的姿态位置,无论图像是否被缩小。这意味着 PoseNet 可以配置为通过在运行时设置我们上面提到的输出步幅来提高精度,但会降低性能。
输出步幅决定了我们相对于输入图像大小缩小输出的程度。它会影响层的尺寸和模型输出。输出步幅越高,网络中层的分辨率和输出越低,相应的精度也越低。在这个实现中,输出步幅可以是 8、16 或 32。换句话说,输出步幅为 32 会导致最快的性能,但精度最低,而 8 会导致最高的精度,但性能最慢。我们建议从 16 开始。
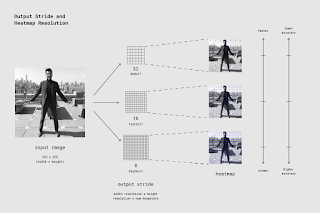 |
| 输出步幅决定了我们相对于输入图像大小缩小输出的程度。更高的输出步幅速度更快,但会导致精度降低。 |
在幕后,当输出步幅设置为 8 或 16 时,层中的输入步幅量会减少以创建更大的输出分辨率。然后使用
空洞卷积 来使后续层中的卷积滤波器具有更宽的视野(当输出步幅为 32 时,不应用空洞卷积)。虽然 Tensorflow 支持空洞卷积,但 TensorFlow.js 不支持,因此我们
提交了一个 PR 来包含它。
模型输出:热图和偏移向量
当 PoseNet 处理图像时,实际上返回的是一个热图以及一个偏移向量,可以解码这些向量来找到图像中与姿态关键点相对应的高置信度区域。我们将在稍后讨论这些的含义,但现在下面的图示从高层次上说明了每个姿态关键点是如何与一个热图张量和一个偏移向量张量相关的。
 |
| PoseNet 返回的 17 个姿态关键点中的每一个都与一个热图张量和一个偏移向量张量相关联,用于确定关键点的精确位置。 |
这两个输出都是 3D 张量,具有我们将称为分辨率的高度和宽度。分辨率由输入图像大小和输出步幅根据以下公式决定
Resolution = ((InputImageSize - 1) / OutputStride) + 1
// Example: an input image with a width of 225 pixels and an output
// stride of 16 results in an output resolution of 15
// 15 = ((225 - 1) / 16) + 1
热图
每个热图都是一个大小为分辨率 x 分辨率 x 17 的 3D 张量,因为 17 是 PoseNet 检测到的关键点数量。例如,如果图像大小为 225,输出步幅为 16,则这将是 15x15x17。第三维(17 维)中的每个切片对应于特定关键点的热图。该热图中的每个位置都有一个置信度得分,它是该关键点类型的一部分存在于该位置的概率。可以将其视为将原始图像分成一个 15x15 的网格,其中热图分数提供了一种分类,说明每个关键点在每个网格方块中存在的可能性。
偏移向量
每个偏移向量都是一个大小为分辨率 x 分辨率 x 34 的 3D 张量,其中 34 是关键点数量 * 2。如果图像大小为 225,输出步幅为 16,则这将是 15x15x34。由于热图是对关键点位置的近似,因此偏移向量在位置上与热图点相对应,并用于预测关键点的精确位置,方法是从相应的热图点沿着向量移动。偏移向量的前 17 个切片包含向量的 x,后 17 个切片包含 y。偏移向量大小与原始图像的比例相同。
从模型的输出估计姿态
在图像通过模型后,我们执行一些计算来从输出估计姿态。例如,单人姿态估计算法返回一个姿态置信度得分,该得分本身包含一个关键点数组(按部分 ID 索引),每个关键点都有一个置信度得分和 x、y 位置。
要获取姿态的关键点
- 对热图进行 sigmoid 激活以获得分数。
- scores = heatmap.sigmoid()
- 对关键点置信度分数进行 argmax2d 以获取热图中每个部分得分最高的 x 和 y 索引,这实际上是该部分最有可能存在的位置。这将产生一个大小为 17x2 的张量,其中每行都是热图中每个部分得分最高的 y 和 x 索引。
- heatmapPositions = scores.argmax(y, x)
- 通过获取与热图中该部分的 x 和 y 索引相对应的偏移量的 x 和 y 来检索每个部分的偏移向量。这将产生一个大小为 17x2 的张量,其中每行都是对应关键点的偏移向量。例如,对于索引为 k 的部分,当热图位置为 y 和 d 时,偏移向量为
- offsetVector = [offsets.get(y, x, k), offsets.get(y, x, 17 + k)]
- 要获取关键点,每个部分的热图 x 和 y 乘以输出步幅,然后加上它们对应的偏移向量,该向量与原始图像的比例相同。
- keypointPositions = heatmapPositions * outputStride + offsetVectors
- 最后,每个关键点置信度得分是其热图位置的置信度得分。姿态置信度得分是关键点分数的平均值。
多人姿态估计
我们希望随着更多模型移植到 TensorFlow.js,机器学习的世界对新的编码人员和制造商来说变得更加容易访问、更加友好和更加有趣。TensorFlow.js 上的 PoseNet 只是让这成为可能的一小步尝试。我们很想看看你做了什么——别忘了使用 #tensorflowjs 和 #posenet 分享你很棒的项目!













