发布者:Marat Dukhan 和 Frank Barchard,软件工程师

CPU 为 ML 推理提供了最广泛的覆盖范围,并且仍然是 TensorFlow Lite 的默认目标。因此,提高 CPU 推理性能是一个重中之重,我们很高兴地宣布,我们通过在 ARM CPU 上启用半精度推理,将 TensorFlow Lite 的 XNNPack 后端 中的浮点推理性能提高了一倍。这意味着更多 AI 功能可以部署到旧的和低端设备上。
传统上,TensorFlow Lite 支持机器学习模型中的两种数值计算:a) 使用 IEEE 754 单精度 (32 位) 格式的浮点运算,以及 b) 使用低精度整数的量化。虽然单精度浮点数提供了最大的灵活性和易用性,但它们在存储和内存方面的开销是 4 倍,并且与 8 位整数计算相比,性能开销更大。相比之下,半精度 (FP16) 浮点数是一种有趣的替代方案,它平衡了易用性和性能:处理器需要传输的字节数减少一半,并且每个向量运算产生的元素数量增加一倍。由于此特性,与传统的 FP32 方法相比,FP16 推理为浮点模型铺平了通往 2 倍加速的道路。
长期以来,CPU 上的 FP16 推理主要停留在研究阶段,因为缺乏对 FP16 计算的硬件支持限制了生产用例。然而,大约在 2017 年,新的移动芯片组开始包含对原生 FP16 计算的支持,到目前为止,大多数移动电话(包括高端和低端)都支持该功能。基于这种广泛的可用性,我们很高兴地宣布 TensorFlow Lite 和 XNNPack 中的半精度推理正式可用。
半精度推理已经在 Google Assistant、Google Meet、YouTube 和 ML Kit 的生产环境中经过了实战测试,并且在各种神经网络架构和移动设备上展现出接近 2 倍的加速。以下是在覆盖常见计算机视觉任务的九种公开模型上的基准测试结果。
这些模型在 5 种流行的移动设备上进行了基准测试,包括最近和较旧的设备(Pixel 3a、Pixel 5a、Pixel 7、Galaxy M12 和 Galaxy S22)。平均加速如下所示。
 |
| 与 5 种移动设备上的单精度 (FP32) 相比,使用半精度 (FP16) 推理的单线程推理加速。数字越大越好。 |
相同的模型还在三台笔记本电脑(MacBook Air M1、Surface Pro X 和 Surface Pro 9)上进行了基准测试。
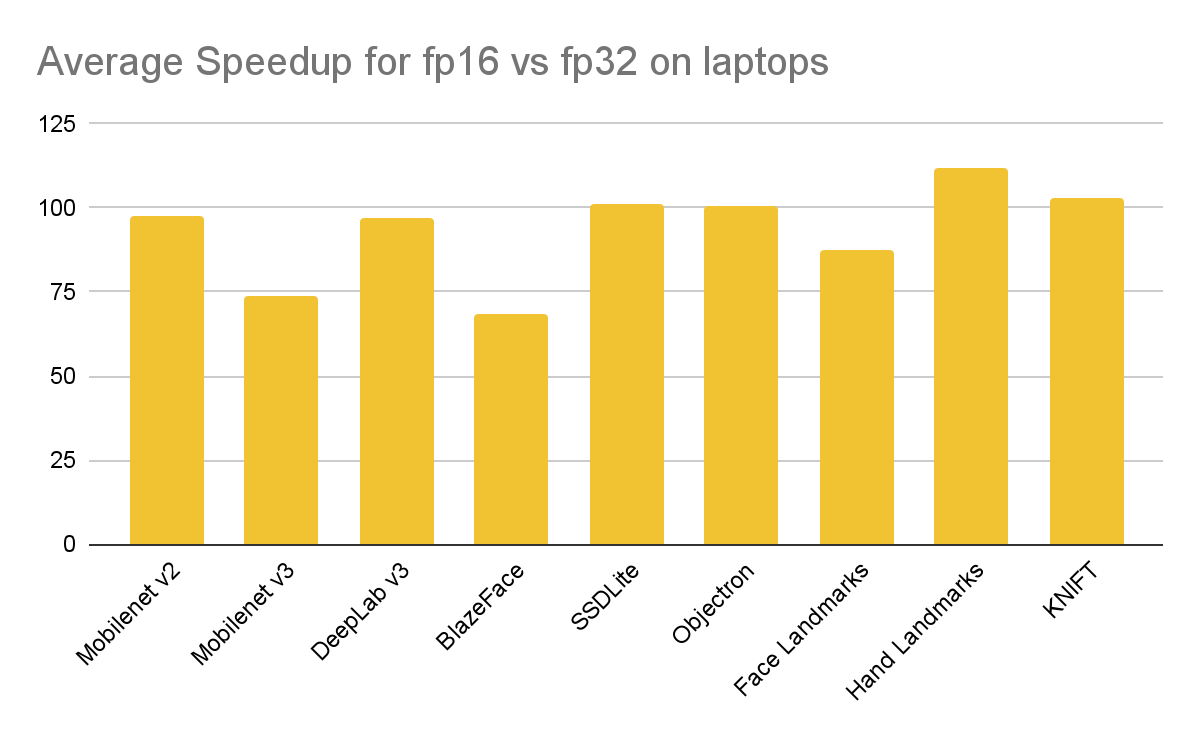 |
| 与 3 台笔记本电脑上的单精度 (FP32) 相比,使用半精度 (FP16) 推理的单线程推理加速。数字越大越好。 |
目前,XNNPack 支持的 FP16 硬件仅限于具有 ARMv8.2 FP16 算术扩展的 ARM 和 ARM64 设备,包括从 Pixel 3 开始的 Android 手机、Galaxy S9(Snapdragon SoC)、Galaxy S10(Exynos SoC)、具有 A11 或更新 SoC 的 iOS 设备、所有 Apple Silicon Mac 以及基于 Snapdragon 850 SoC 或更新版本的 Windows ARM64 笔记本电脑。
要利用 XNNPack 中的半精度推理,用户必须提供具有 FP16 权重和特殊“reduced_precision_support”元数据的浮点 (FP32) 模型,以指示模型与 FP16 推理的兼容性。可以使用 tf.lite.TargetSpec 对象的 _experimental_supported_accumulation_type 属性在模型转换期间添加元数据。
...
converter.target_spec.supported_types = [tf.float16]
converter.target_spec._experimental_supported_accumulation_type = tf.dtypes.float16
当兼容模型在具有 FP16 计算原生支持的硬件上委派给 XNNPack 时,XNNPack 将透明地用 FP16 等效项替换 FP32 运算符,并插入额外的运算符,将模型输入从 FP32 转换为 FP16,并将模型输出转换回从 FP16 到 FP32。如果硬件无法执行 FP16 算术运算,XNNPack 将使用 FP32 计算执行模型推理。因此,单个模型可以在最新的和旧的设备上透明地部署。
此外,XNNPack 代理提供了一个选项,无论模型元数据如何,都可以强制执行 FP16 推理。此选项适用于开发工作流,特别是用于测试使用 FP16 推理时模型的端到端准确性。除了具有原生 FP16 算术支持的设备之外,强制执行 FP16 推理还支持在具有 AVX2 扩展的 x86/x86-64 设备上的仿真模式:所有基本浮点运算都在 FP32 中计算,然后转换为 FP16,再转换回 FP32。请注意,这种模拟速度很慢,并且与原生 FP16 推理并不完全等效,但模拟了原生 FP16 算术中受限尾数精度和指数范围的影响。要强制执行 FP16 推理,请使用 --define xnnpack_force_float_precision=fp16 Bazel 选项构建 TensorFlow Lite,或明确应用 XNNPack 代理,并将 TFLITE_XNNPACK_DELEGATE_FLAG_FORCE_FP16 标志添加到传递到 TfLiteXNNPackDelegateCreate 调用的 TfLiteXNNPackDelegateOptions.flags 位掩码中。
TfLiteXNNPackDelegateOptions xnnpack_options =
TfLiteXNNPackDelegateOptionsDefault();
...
xnnpack_options.flags |= TFLITE_XNNPACK_DELEGATE_FLAG_FORCE_FP16;
TfLiteDelegate* xnnpack_delegate =
TfLiteXNNPackDelegateCreate(&xnnpack_options);
XNNPack 在 FP32 和 FP16 运算符之间提供了完全的特征一致性:所有支持 FP32 推理的运算符也支持 FP16 推理,反之亦然。特别是,稀疏推理 运算符支持在 ARM 处理器上的 FP16 推理。因此,用户可以在同一个模型中组合稀疏和 FP16 推理的性能优势。
除了大多数 ARM 和 ARM64 处理器之外,最新代号为 Sapphire Rapids 的英特尔处理器通过 AVX512-FP16 指令集支持原生 FP16 算术,并且最近宣布的 AVX10 指令集有望使此功能在 x86 平台上广泛可用。我们计划在未来的版本中针对这些指令集优化 XNNPack。
我们要感谢 Alan Kelly、Zhi An Ng、Artsiom Ablavatski、Sachin Joglekar、T.J. Alumbaugh、Andrei Kulik、Jared Duke、Matthias Grundmann 对 TensorFlow Lite 和 XNNPack 中的半精度推理做出的贡献。


2023 年 11 月 29 日 - 发布者:Marat Dukhan 和 Frank Barchard,软件工程师CPU 为 ML 推理提供了最广泛的覆盖范围,并且仍然是 TensorFlow Lite 的默认目标。因此,提高 CPU 推理性能是一个重中之重,我们很高兴地宣布,我们通过在 ARM CPU 上启用半精度推理,将 TensorFlow Lite 的 XNNPack 后端 中的浮点推理性能提高了一倍。…





