
我们的许多音乐推荐问题都涉及为用户提供满足他们当时聆听偏好和意图的有序项目集。我们根据用户与应用程序的先前交互来提供当前推荐,从抽象的角度来看,在我们不断向用户推荐内容时,我们面临着顺序决策过程。
强化学习 (RL) 是一种成熟的顺序决策工具,可用于解决顺序推荐问题。我们决定探索如何使用 RL 为用户打造聆听体验。在开始训练代理之前,我们需要选择一个 RL 库,该库可以让我们轻松地对解决方案进行原型设计、测试和潜在部署。
在 Spotify,我们将 TensorFlow 和扩展的 TensorFlow 生态系统(TFX、TensorFlow Serving 等)用作生产机器学习堆栈的一部分。我们很早就决定使用 TensorFlow Agents 作为我们的首选 RL 库,因为我们知道,将来,将我们的实验与生产系统集成将效率更高。
我们需要的技术缺失部分是离线 Spotify 环境,我们可以在线测试之前使用它来对代理进行原型设计、分析、探索和训练。TF-Agents 库的灵活性以及 TensorFlow 及其生态系统的广泛优势使我们能够干净地设计一个强大且可扩展的离线 Spotify 模拟器。
我们基于 TF-Agents 环境 原语设计模拟器,并使用我们开发的模拟器,训练和评估了用于项目推荐的顺序模型、普通 RL 代理 (PPG、DQN) 以及修改后的深度 Q 网络(我们称之为 Action-Head DQN (AH-DQN)),该网络解决了我们 RL 公式的大状态和动作空间带来的特定挑战。
通过现场实验,我们能够证明我们的离线性能估计与在线结果高度相关。这为大规模实验和强化学习在 Spotify 的应用打开了大门,这一切得益于 TensorFlow 和 TF-Agents 开启的技术基础。
在本文中,我们将详细介绍我们的 RL 问题以及我们如何使用 TF-Agents 来实现端到端的这项工作。
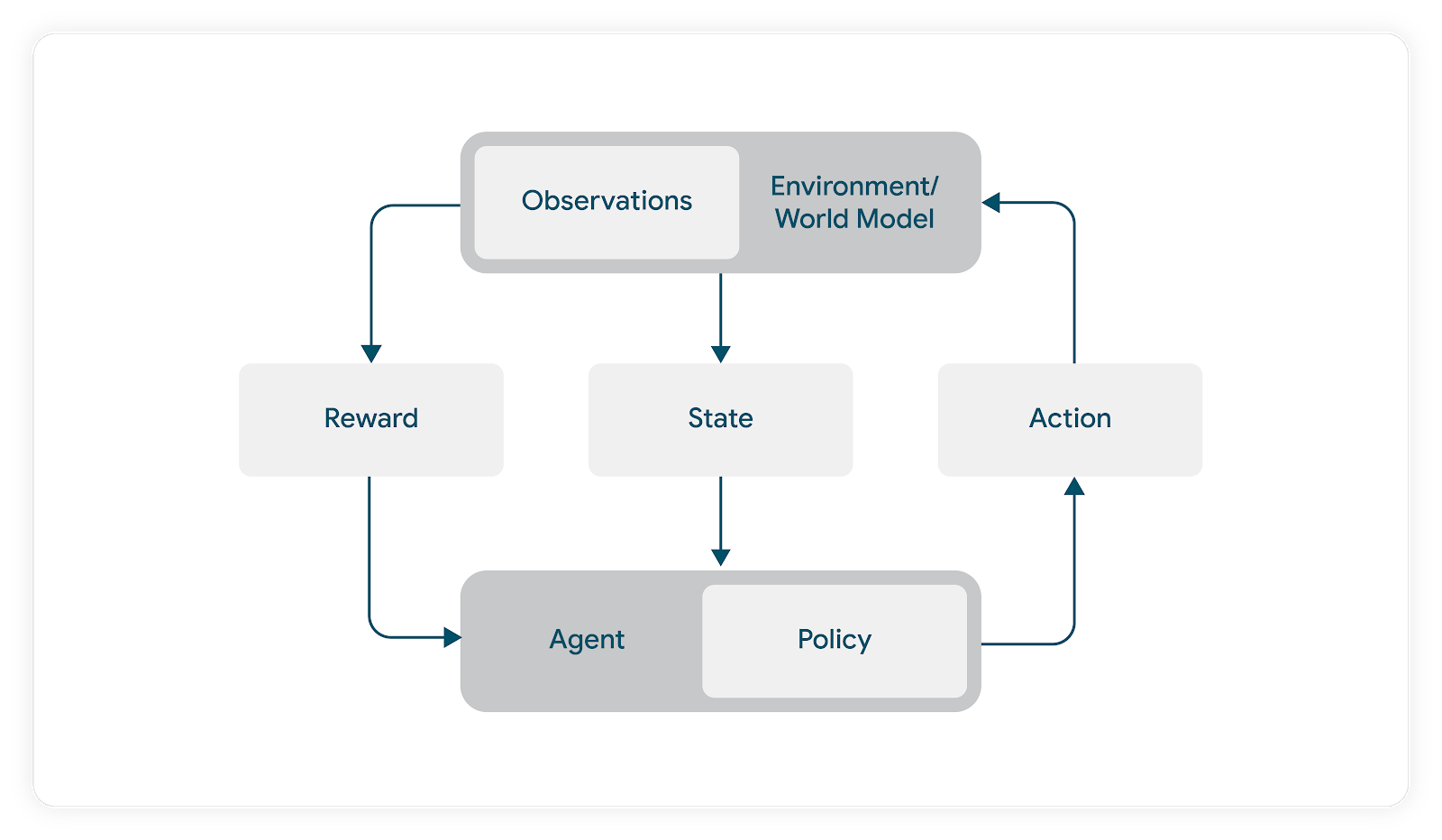
在我们的案例中,环境发出的奖励是用户对代理动作驱动的音乐推荐的响应。在没有模拟器的情况下,我们需要让真实用户接触代理,以观察奖励。我们使用基于模型的 RL 方法来避免让未经训练的代理与真实用户交互(这可能会在训练过程中损害用户的满意度)。
在此基于模型的 RL 公式中,代理不会针对真实用户进行在线训练。相反,它使用用户模型来预测对由代理动作得出的曲目列表的响应。使用此模型,我们优化动作,以最大限度地提高(模拟的)用户满意度指标。在训练阶段,环境使用此用户模型来返回代理推荐的动作的预测用户响应。
我们使用 Keras 来设计和训练我们的用户模型。然后,模拟器会解包序列化后的用户模型,并将其用于在代理训练和评估期间计算奖励。
从抽象的角度来看,我们需要构建的内容很明确。我们需要一种方法来模拟用户的聆听会话。对于给定的模拟用户和一些内容,实例化一个聆听会话,并让代理驱动该会话中的推荐。允许模拟用户“对”这些推荐做出“反应”,并让代理根据此结果调整其策略,以驱动一些预期的累积奖励。
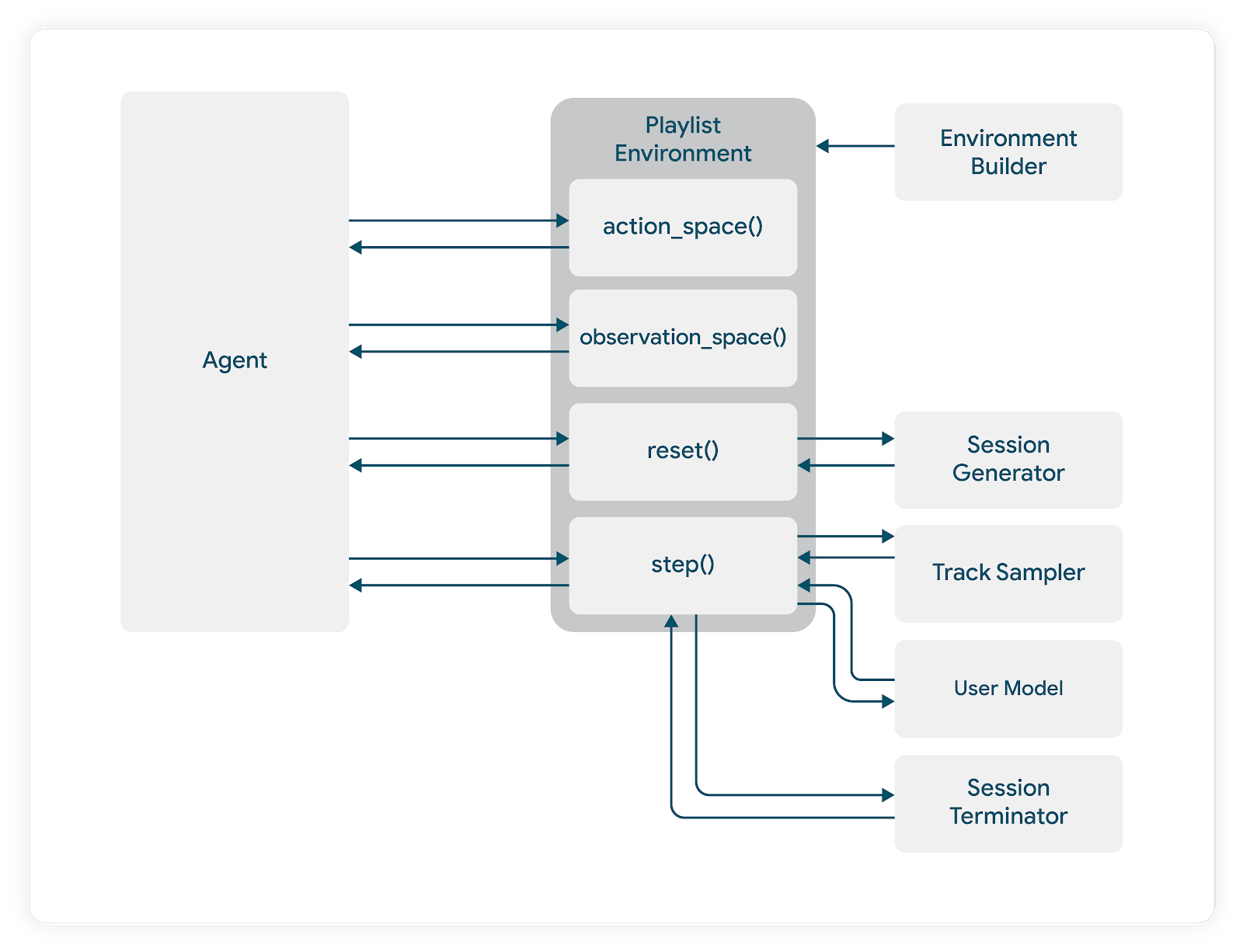
TensorFlow Agents 环境设计指导我们开发了系统的模块化组件,每个组件负责整体模拟的不同部分。
在我们的代码库中,我们定义了一个环境抽象,它要求为每个具体实例化定义以下内容
class AbstractEnvironment(ABC): _user_model: AbstractUserModel = None _track_sampler: AbstractTrackSampler = None _episode_tracker: EpisodeTracker = None _episode_sampler: AbstractEpisodeSampler = None def reset(self) -> List[float]: pass def step(self, action: float) -> (List[float], float, bool): pass def observation_space(self) -> Dict: pass def action_space(self) -> Dict: pass |
_episode_sampler 传递到环境。如前所述,我们还需要向模拟器提供训练后的用户模型,在本例中通过 _user_model 传递。
与任何代理环境一样,我们的模拟器要求我们指定 action_spec 和 observation_spec。在本例中,动作可以是连续的或离散的,具体取决于我们的代理选择以及我们如何建议将代理的动作转换为实际推荐。我们通常推荐从潜在项目池中抽取的有序项目列表。直接制定此动作空间会导致其组合复杂。我们还假设用户会与多个项目交互,因此,该领域中依赖于单一选择假设的先前工作不适用。
_track_sampler。由情节采样器提出的“示例播放模式”包含有关可以向模拟用户展示的项目的信息。曲目采样器使用这些信息和代理的动作,并返回实际的项目推荐。
我们还需要处理情节终止动态。在我们的模拟器中,重置规则由模型构建器设置,并基于对与特定音乐聆听体验相关的交互数据的经验调查。作为假设,我们可能会确定 92% 的聆听会话在 6 次连续曲目跳过后终止,并且我们将构建我们的模拟终止逻辑以匹配。它还要求我们在模拟器中设计抽象,使我们能够在每个步骤之后检查情节是否应该终止。
当情节重置时,模拟器将采样新的假设用户聆听会话对,并开始下一个情节。
与标准 TF Agents 环境一样,我们需要定义模拟的步骤动态。我们有模拟的可选动态,我们需要确保在每个步骤中强制执行这些动态。例如,我们可能希望同一个项目不能被推荐超过一次。如果代理的动作表明推荐了之前推荐过的项目,我们需要构建功能来根据此动作选择下一个最佳项目。
我们还需要根据需要在每个步骤中调用上述终止(和其他支持函数)。
到目前为止提到的功能共同创建了一个非常复杂的模拟设置。虽然 TF Agents 回放缓冲区 为我们提供了存储情节以进行代理训练和评估所需的功能,但我们很快意识到需要能够存储更多情节数据以进行调试,以及与标准代理性能度量不同的更详细的特定于模拟的评估。
因此,我们允许包含扩展的 _episode_tracker,它将存储有关用户模型预测的附加信息,指示采样的用户/内容对的信息以及更多信息。
我们的环境抽象为我们提供了一个模板,该模板与标准 TF-Agents 环境类相匹配。在我们可以实际创建具体的 TF-Agents 环境实例之前,需要解决我们环境的一些输入。这将分三个步骤进行。
首先,我们定义一个符合我们抽象的特定模拟环境。例如
class PlaylistEnvironment(AbstractEnvironment): def __init__( self, user_model: AbstractUserModel, track_sampler: AbstractTrackSampler, episode_tracker: EpisodeTracker, episode_sampler: AbstractEpisodeSampler, .... ): ... |
接下来,我们使用一个 *环境构建器类*,它将用户模型、曲目采样器等作为输入, *以及* 像 PlaylistEnvironment 这样的环境类。 构建器创建了此环境的具体实例
self.playlist_env: PlaylistEnvironment = environment_ctor( user_model=user_model, track_sampler=track_sampler, episode_tracker=episode_tracker, episode_sampler=self._eps_sampler, ) |
最后,我们使用一个转换类,它从我们实例化的环境类构造一个 TF-Agents *环境*
class TFAgtPyEnvironment(py_environment.PyEnvironment): def __init__(self, environment: AbstractEnvironment): super().__init__() self.env = environment |
这将在我们的环境构建器内部执行
class EnvironmentBuilder(AbstractEnvironmentBuilder): def __init__(self, ...): ... def get_tf_env(self): ... tf_env: TFAgtPyEnvironment = TFAgtPyEnvironment( self.playlist_env ) return tf_env |
接下来,我们将讨论如何使用我们的模拟器来训练 RL Agent 生成播放列表。
正如所述,强化学习提供了一套方法,可以自然地适应音乐收听的顺序性;允许我们在会话进行时适应用户不断变化的偏好。
我们可以尝试使用 RL 解决的一个具体问题是自动音乐播放列表生成。给定一组(大型)曲目,我们希望学习如何创建最佳播放列表以推荐给用户,以最大限度地提高满意度指标。我们的用例不同于标准的板式推荐任务,在标准的板式推荐任务中,目标通常是最多选择序列中的一个项目。在我们的案例中,我们假设用户对板式中的多个项目做出了响应,这使得板式推荐系统不直接适用。另一个复杂之处在于,推荐所取出的曲目集一直在变化。


我们观察到许多朴素、启发式、模型驱动和 RL 策略的方向一致性。
有关我们基于模型的 RL 方法和智能体设计的具体信息,请参阅我们的 KDD 论文。
我们要感谢所有过去和现在为这项工作做出贡献的 Spotify 团队成员。特别感谢 Mehdi Ben Ayed 在帮助我们开发 RL 代码库方面所做的早期工作。我们还要感谢 TensorFlow Agents 团队 在整个项目中给予我们支持和鼓励(以及使之成为可能的 库)。






 由 Spotify 的 Surya Kanoria、Joseph Cauteruccio、Federico Tomasi、Kamil Ciosek、Matteo Rinaldi 和 Zhenwen Dai 发表
由 Spotify 的 Surya Kanoria、Joseph Cauteruccio、Federico Tomasi、Kamil Ciosek、Matteo Rinaldi 和 Zhenwen Dai 发表 