
现代推荐器大量利用嵌入来创建每个用户和候选项目的向量表示。然后可以使用这些嵌入来计算用户和项目之间的相似性,以便向用户推荐更有趣和相关的候选项目。但在处理大规模数据时,尤其是在 在线机器学习 设置中,嵌入表的大小可能会急剧增长,积累数百万(有时甚至数十亿)个项目。在这个规模下,将这些嵌入表存储在内存中变得不可能。此外,很大一部分项目可能很少被看到,因此为这些很少出现的项目保留专用嵌入没有意义。更好的解决方案是用一个通用嵌入来表示这些项目。这可以在性能成本很小的情况下显着减小嵌入表的大小。这是动态嵌入表背后的主要动机。
TensorFlow 的内置 tf.keras.layers.Embedding 层在创建时具有固定大小,因此我们需要另一种方法。幸运的是,有一个 TensorFlow SIG 项目专门用于此目的:TensorFlow Recommenders Addons (TFRA)。您可以从其存储库中了解更多信息,但在高级别上,TFRA 利用动态嵌入技术来动态改变嵌入大小,并实现比静态嵌入更好的推荐结果。TFRA 与 TF2.0 完全兼容,并与熟悉的 Keras API 接口无缝协作,因此可以轻松集成到其他 TensorFlow 产品中,例如 TensorFlow Recommenders (TFRS)。
在本教程中,我们将通过利用 TFRS 和 TFRA 来构建一个电影推荐模型。我们将使用 MovieLens 数据集,其中包含匿名数据,显示用户对电影的评分。我们的主要重点是展示 TensorFlow Recommenders Addons 库中提供的动态嵌入如何用于在推荐设置中动态增加和减小嵌入表的大小。您可以在 此处 找到完整的实现,以及 此处 的演练。
我们将首先导入所需的库。
import tensorflow as tf import tensorflow_datasets as tfds # TFRA 对 TensorFlow 进行了一些修补,因此必须在导入 TF 之后导入它 import tensorflow_recommenders as tfrs import tensorflow_recommenders_addons as tfra import tensorflow_recommenders_addons.dynamic_embedding as de |
请注意我们如何在导入 TensorFlow 之后导入 TFRA 库。建议遵循此顺序,因为 TFRA 库将对 TensorFlow 应用一些修补程序。
让我们首先使用 TensorFlow Recommenders 构建一个基线模型。我们将遵循 本 TFRS 检索教程 的模式来构建一个双塔检索模型。用户塔将以用户 ID 作为输入,但项目塔将使用标记化的电影标题作为输入。
为了处理电影标题,我们定义了一个辅助函数,该函数将电影标题转换为小写,删除给定电影标题中的任何标点符号,并使用空格进行拆分以生成一个标记列表。最后,我们只从电影标题中获取最多max_token_length个标记(从开头开始)。如果电影标题的标记较少,则会获取所有标记。该数字是根据一些分析选择的,代表了数据集中标题长度的第 90 个百分位数。
max_token_length = 6 pad_token = "[PAD]" punctuation_regex = "[\!\"#\$%&\(\)\*\+,-\.\/\:;\<\=\>\?@\[\]\\\^_`\{\|\}~\\t\\n]" # 首先,我们将定义一个辅助函数来处理电影标题。 def process_text(x: tf.Tensor, max_token_length: int, punctuation_regex: str) -> tf.Tensor: return tf.strings.split( tf.strings.regex_replace( tf.strings.lower(x["movie_title"]), punctuation_regex, "" ) )[:max_token_length] |
我们还将标记化的电影标题填充到固定长度,并使用相同的随机种子拆分数据集,以便在训练周期中获得一致的验证结果。您可以在笔记本的“处理数据集”部分找到详细的代码。
我们的用户塔与TFRS 检索教程中的用户塔几乎相同(只是更深),但在电影塔中,在嵌入查找之后有一个GlobalAveragePooling1D层,它将电影标题标记的嵌入平均到单个嵌入。
def get_movie_title_lookup_layer(dataset: tf.data.Dataset) -> tf.keras.layers.Layer: movie_title_lookup_layer = tf.keras.layers.StringLookup(mask_token=pad_token) movie_title_lookup_layer.adapt(dataset.map(lambda x: x["movie_title"])) return movie_title_lookup_layer def build_item_model(movie_title_lookup_layer: tf.keras.layers.StringLookup): vocab_size = movie_title_lookup_layer.vocabulary_size() return tf.keras.models.Sequential([ tf.keras.layers.InputLayer(input_shape=(max_token_length), dtype=tf.string), movie_title_lookup_layer, tf.keras.layers.Embedding(vocab_size, 64), tf.keras.layers.GlobalAveragePooling1D(), tf.keras.layers.Dense(64, activation="gelu"), tf.keras.layers.Dense(32), tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) ]) |
接下来我们将训练模型。
训练模型很简单,只需要在模型上调用 `fit()` 方法并提供必要的参数即可。 我们将使用验证数据集 `validation_ds` 来衡量模型的性能。
history = model.fit(datasets.training_datasets.train_ds, epochs=3, validation_data=datasets.training_datasets.validation_ds) |
最后,输出如下所示
Epoch 3/3 220/220 [==============================] - 146s 633ms/step ...... val_factorized_top_k/top_10_categorical_accuracy: 0.0179 - val_factorized_top_k/top_50_categorical_accuracy: 0.0766 - val_factorized_top_k/top_100_categorical_accuracy: 0.1338 - val_loss: 12359.0557 - val_regularization_loss: 0.0000e+00 - val_total_loss: 12359.0557 |
我们在验证集上获得了 13.38% 的 top 100 类别准确率。
我们现在将学习如何在 TensorFlow Recommenders Addons (TFRA) 库中使用动态嵌入,而不是使用静态嵌入表。顾名思义,与预先为词汇表中的所有项目创建嵌入相反,动态嵌入仅在需要时才会增加嵌入表的大小。这种行为在处理数百万和数十亿个项目和用户时非常有效,就像一些公司所做的那样。 对于这些公司,发现无法容纳在内存中的静态嵌入表并不奇怪。静态嵌入表可能增长到数百 GB 甚至 TB 的大小,即使在云环境中,可用内存最大的实例也无法承受。
当您有一个具有高基数的嵌入表时,访问权重将非常稀疏。因此,使用基于哈希表的结构来保存权重,并且每次迭代所需的权重都会从底层表结构中检索。在这里,为了专注于库的核心功能,我们将专注于非分布式设置。在这种情况下,TFRA 将默认选择 cuckoo 哈希表。 但是,还有其他解决方案,例如 Redis、nvhash 等。
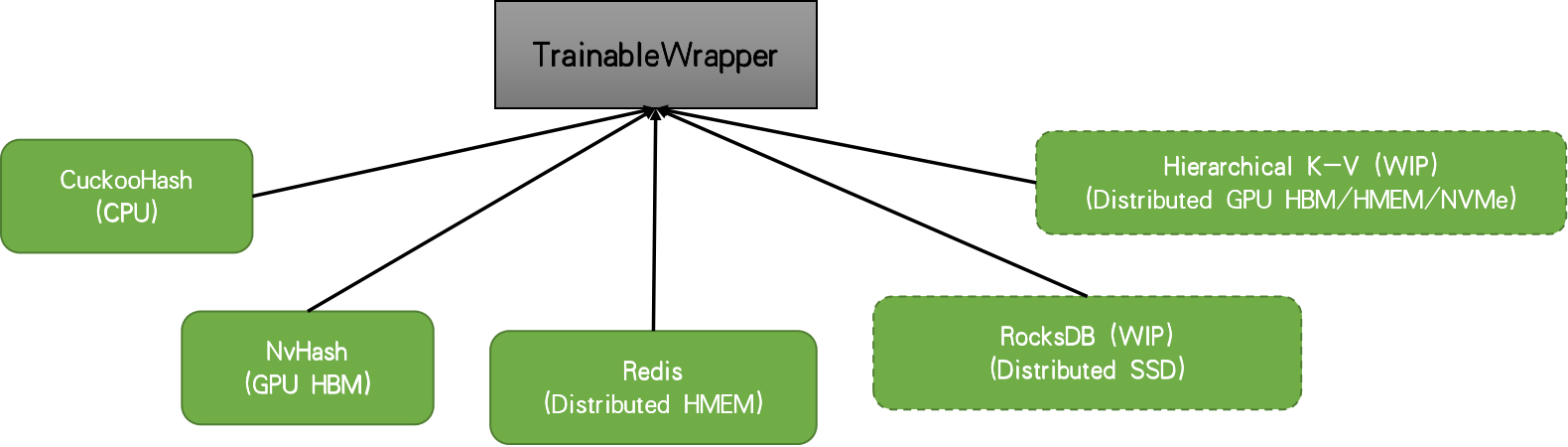 |
在使用动态嵌入时,我们用一些初始容量初始化表,并且该表将在模型训练期间看到更多 ID 时按需增长。有关动机和内部机制的更多信息,请参考 RFC。
目前,在 TFRA `dynamic_embedding` 模块中,有三种类型的嵌入可用
n_slots 作为参数,ID 会映射到层内的某个槽位。该层将返回大小为 [batch_size, n_slots, embedding_dim] 的张量。我们将使用 Embedding 来表示用户 ID,使用 SquashedEmbedding 来表示令牌 ID。请记住,每个电影标题都有多个令牌,因此,我们需要一种方法将生成的令牌嵌入减少到单个代表性嵌入。
注意:Embedding 的行为从 0.5 版更改为 0.6 版。请确保在此教程中使用 0.6 版。
有了它,我们就可以像在标准模型中一样定义两个塔。但是,这次我们将使用动态嵌入层而不是静态嵌入层。
def build_de_user_model(user_id_lookup_layer: tf.keras.layers.StringLookup) -> tf.keras.layers.Layer: vocab_size = user_id_lookup_layer.vocabulary_size() return tf.keras.Sequential([ tf.keras.layers.InputLayer(input_shape=(), dtype=tf.string), user_id_lookup_layer, de.keras.layers.Embedding( embedding_size=64, initializer=tf.random_uniform_initializer(), init_capacity=int(vocab_size*0.8), restrict_policy=de.FrequencyRestrictPolicy, name="UserDynamicEmbeddingLayer" ), tf.keras.layers.Dense(64, activation="gelu"), tf.keras.layers.Dense(32), tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) ], name='user_model') def build_de_item_model(movie_title_lookup_layer: tf.keras.layers.StringLookup) -> tf.keras.layers.Layer: vocab_size = movie_title_lookup_layer.vocabulary_size() return tf.keras.models.Sequential([ tf.keras.layers.InputLayer(input_shape=(max_token_length), dtype=tf.string), movie_title_lookup_layer, de.keras.layers.SquashedEmbedding( embedding_size=64, initializer=tf.random_uniform_initializer(), init_capacity=int(vocab_size*0.8), restrict_policy=de.FrequencyRestrictPolicy, combiner="mean", name="ItemDynamicEmbeddingLayer" ), tf.keras.layers.Dense(64, activation="gelu"), tf.keras.layers.Dense(32), tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) ]) |
定义完用户塔和电影塔模型后,我们可以像往常一样定义检索模型。
作为模型构建的最后一步,我们将创建模型并编译它。
def create_de_two_tower_model(dataset: tf.data.Dataset, candidate_dataset: tf.data.Dataset) -> tf.keras.Model: user_id_lookup_layer = get_user_id_lookup_layer(dataset) movie_title_lookup_layer = get_movie_title_lookup_layer(dataset) user_model = build_de_user_model(user_id_lookup_layer) item_model = build_de_item_model(movie_title_lookup_layer) task = tfrs.tasks.Retrieval( metrics=tfrs.metrics.FactorizedTopK( candidate_dataset.map(item_model) ), ) model = DynamicEmbeddingTwoTowerModel(user_model, item_model, task) optimizer = de.DynamicEmbeddingOptimizer(tf.keras.optimizers.Adam()) model.compile(optimizer=optimizer) return model datasets = create_datasets() de_model = create_de_two_tower_model(datasets.training_datasets.train_ds, datasets.candidate_dataset) |
注意 DynamicEmbeddingOptimizer 围绕标准 TensorFlow 优化器的使用。必须将标准优化器包装在 DynamicEmbeddingOpitmizer 中,因为它将提供训练存储在哈希表中的权重所需的专用功能。现在我们可以训练我们的模型了。
训练模型非常简单,但会涉及更多额外的工作,因为我们希望记录一些额外的信息。我们将通过 tf.keras.callbacks.Callback 对象进行日志记录。我们将命名为 DynamicEmbeddingCallback。
epochs = 3 history_de = {} history_de_size = {} de_callback = DynamicEmbeddingCallback(de_model, steps_per_logging=20) for epoch in range(epochs): datasets = create_datasets() train_steps = len(datasets.training_datasets.train_ds) hist = de_model.fit( datasets.training_datasets.train_ds, epochs=1, validation_data=datasets.training_datasets.validation_ds, callbacks=[de_callback] ) for k,v in de_model.dynamic_embedding_history.items(): if k=="step": v = [vv+(epoch*train_steps) for vv in v] history_de_size.setdefault(k, []).extend(v) for k,v in hist.history.items(): history_de.setdefault(k, []).extend(v) |
我们将循环从 fit() 函数中移出,该循环遍历各个 epoch。然后在每个 epoch 中,我们重新创建数据集,因为这将提供训练数据集的不同随机排列。我们将在循环中训练模型一个 epoch。最后,我们将记录的嵌入大小累积在 history_de_size 中(这是由我们的自定义回调提供的)以及性能指标在 history_de 中。
回调的实现如下。
class DynamicEmbeddingCallback(tf.keras.callbacks.Callback): def __init__(self, model, steps_per_logging, steps_per_restrict=None, restrict=False): self.model = model self.steps_per_logging = steps_per_logging self.steps_per_restrict = steps_per_restrict self.restrict = restrict def on_train_begin(self, logs=None): self.model.dynamic_embedding_history = {} def on_train_batch_end(self, batch, logs=None): if self.restrict and self.steps_per_restrict and (batch+1) % self.steps_per_restrict == 0: [ self.model.embedding_layers[k].params.restrict( num_reserved=int(self.model.lookup_vocab_sizes[k]*0.8), trigger=self.model.lookup_vocab_sizes[k]-2 # UNK & PAD tokens ) for k in self.model.embedding_layers.keys() ] if (batch+1) % self.steps_per_logging == 0: embedding_size_dict = { k:self.model.embedding_layers[k].params.size().numpy() for k in self.model.embedding_layers.keys() } for k, v in embedding_size_dict.items(): self.model.dynamic_embedding_history.setdefault(f"embedding_size_{k}", []).append(v) self.model.dynamic_embedding_history.setdefault(f"step", []).append(batch+1) |
回调执行两件事
steps_per_logging 次迭代记录嵌入层的尺寸restrict=True(默认情况下设置为 False),则将嵌入表的大小缩减为总词汇量大小的 80%。让我们了解一下缩减大小的含义以及为什么它很重要。
我们尚未讨论的一个重要话题是如何缩减嵌入表的大小,如果它超过了某个预定义的阈值。这是一个强大的功能,因为它允许我们定义一个阈值,超过该阈值嵌入表不应该增长。这将允许我们在保持内存需求低于我们可能拥有的内存限制的情况下使用大型词汇表。我们通过在嵌入层的底层变量上调用 restrict() 来实现这一点,如 DynamicEmbeddingCallback 中所示。restrict() 接受两个参数:num_reserved(缩减后的尺寸)和 trigger(应触发缩减的尺寸)。控制缩减执行方式的策略使用层构造中的 restrict_policy 参数定义。您可以看到我们使用的是 FrequencyRestrictPolicy。这意味着最不常用的项目将从嵌入表中删除。回调使用户能够通过在 DynamicEmbeddingCallback 中设置 steps_per_restrict 和 restrict 参数来设置缩减应触发的频率。
当您有流式数据时,缩减嵌入表的大小更有意义。想想一个在线学习环境,您每天(甚至每小时)都在一些传入数据上训练模型。您可以将外部循环(即 epoch)视为天。每天您都会收到一个数据集(例如,包含前一天的用户交互),您将从之前的检查点训练模型。在这种情况下,您可以使用 DynamicEmbeddingCallback 来触发限制,如果嵌入表的大小超过了 trigger 参数中定义的大小。
在这里,我们分析了三种变体的性能。
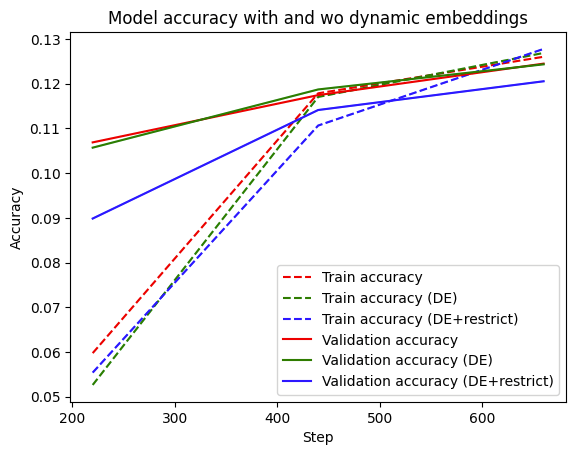 |
您可以看到,使用动态嵌入的模型(实线绿色)与基线(实线红色)具有可比的验证性能。您也可以在训练准确率中看到类似的趋势。实际上,动态嵌入通常可以在大规模在线学习设置中被视为提高准确率。
最后,我们可以看到 restrict 对验证准确率有负面影响,这是可以理解的。由于我们正在处理一个相对较小的数据集,其中包含少量项目,因此缩减可能会删除最好保留在表中的嵌入。例如,您可以增加 restrict 函数中的 num_reserved 参数(例如,将其设置为 int(self.model.lookup_vocab_sizes[k]*0.95)),这将产生接近没有 restrict 时的性能的性能。
接下来,我们来看看嵌入表随着时间的推移到底有多“动态”。
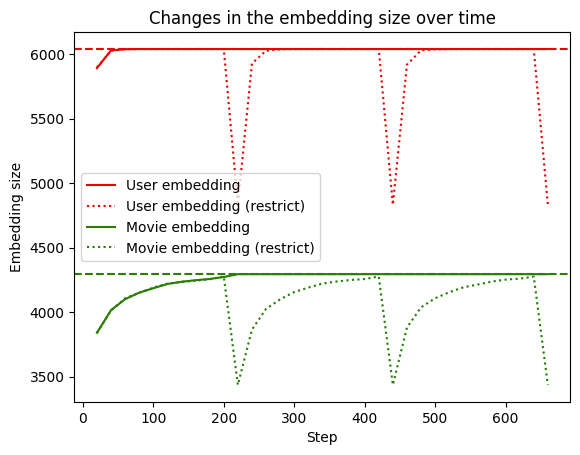 |
我们可以看到,当没有使用 restrict 时,嵌入表的大小会增长到词汇表的完整大小(虚线),并保持在那里。但是,当 restrict 被触发(点线)时,大小会下降,然后随着遇到新的 ID 再次增长。
还需要注意的是,构建一个合适的验证集并非易事。需要考虑诸如样本外验证、时间外验证、分层抽样等因素,并需谨慎处理。然而,在本练习中,我们并未关注这些因素,而是通过从现有数据集随机采样来创建验证集。
使用动态嵌入表是在处理包含数百万或数十亿个实体的大型项目集时进行表示学习的一种强大方法。在本教程中,我们学习了如何使用 TensorFlow Recommender Addons 库提供的 dynamic_embedding 模块来实现这一点。我们首先探索了数据,并通过提取用于模型训练和评估的特征来构建 tf.data.Dataset 对象。接下来,我们定义了一个使用静态嵌入表的模型作为评估基线。然后,我们创建了一个使用动态嵌入的模型,并在数据上对其进行了训练。我们发现,使用动态嵌入,嵌入表仅按需增长,并且仍然可以实现与基线相当的性能。我们还讨论了如何使用 restrict 功能来缩小嵌入表,如果它超过了预定义的阈值。
我们希望本教程能为您提供关于 TFRA 和动态嵌入的良好概念性介绍,并帮助您思考如何利用它来增强您自己的推荐系统。如果您想进行更深入的讨论,请访问 TFRA 存储库。


2023 年 4 月 19 日 — 发布者 Thushan Ganegedara (GDE), 荣海东 (Nvidia), 魏伟 (Google)现代推荐系统大量利用嵌入来创建每个用户和候选项目的向量表示。这些嵌入可以用来计算用户和项目之间的相似度,以便向用户推荐更有趣和相关的候选项目。但是,当处理大规模数据时,p…





