发布者:Amandeep Singh (沃达丰),Max Vökler (谷歌云)

作为全球最大的电信公司之一,沃达丰正在与谷歌云合作,以推动其整个数据景观的进步,包括其数据湖、数据仓库 (DWH),尤其是 AI/ML 战略。虽然沃达丰在一段时间内一直使用 AI/ML 进行生产,但不断增长的用例数量给工业化和可扩展性带来了挑战。对于沃达丰来说,关键是在一个高度监管的行业中快速构建和部署大规模的 ML 用例。虽然沃达丰的 AI 加速器平台(构建在谷歌云的 Vertex AI 之上)为实现这一目标提供了巨大帮助,但这篇博文将深入探讨 TensorFlow 数据验证 (TFDV) 如何帮助推进大规模数据治理。
在数据治理方面取得卓越成就是利用 AI 加速器平台进行扩展的关键推动因素。由于沃达丰在分布式团队中工作,并且在开发用例时承担着共同责任,因此避免跨越所有相关方的中断至关重要。
经常出现的一个问题是,表模式会修改,或者特征名称和数据类型会更改。这可能是由于各种原因造成的。例如,由 IT 团队负责的数据工程流程发生了更改。
机器学习中的数据契约是一组规则,定义了模型训练数据结构、数据类型和约束。这些契约提供了一种指定数据预期模式和统计信息的方式。以下可以包含在您的数据契约中
它还可以包含对数据的约束,例如
在模型生产化之前,契约由参与管道的利益相关者(例如 ML 工程师、数据科学家和数据所有者)商定。一旦数据契约商定,就不能更改。如果管道因更改而中断,则可以追溯到责任方。如果需要修改契约,则需要在利益相关者之间进行审查,并且在达成一致后,可以将更改实施到管道中。这有助于确保进入生产中模型的数据质量。
作为沃达丰简化数据治理工作的一部分,我们使用了数据契约。数据契约确保所有团队协同工作,有助于在整个数据生命周期中保持质量。这些契约是管理和验证用于机器学习的数据的强大工具。它们提供了一种确保数据质量高、没有错误并具有预期分布的方法。这篇文章涵盖了数据契约的基础知识,讨论了如何使用它们来更好地验证和理解数据,并展示了如何在结合 TFDV 的情况下使用它们来提高 ML 模型的准确性和性能。无论您是数据科学家、ML 工程师还是与机器学习合作的开发人员,了解数据契约对于构建高质量、准确的模型都至关重要。
利用这样的数据契约,在训练和预测管道中,我们都可以检测和诊断数据中的异常值、不一致和错误,以防止它们对模型造成问题。使用数据契约的另一个优点是它可以帮助我们检测数据漂移。数据漂移是 ML 模型性能下降的最常见原因。数据漂移是指模型的输入数据发生了变化,导致预测出现错误和不准确。使用数据契约可以帮助您识别此问题。
数据契约只是沃达丰在 AI 治理和可扩展性方面众多 KPI 中的一个例子。自 AI 加速器开发和发布以来,越来越多的市场正在使用该平台来生产化其用例,作为其中的一部分,我们拥有垂直扩展组件的资源。除了数据契约之外,这方面的例子还包括专门的日志记录、商定的模型指标计算方法和模型测试策略,例如 Champion/Challenger 和 A/B 测试。
TFDV 是 TensorFlow 团队提供的一个库,用于分析和验证机器学习数据。它提供了一种方式来检查数据是否符合数据契约。TFDV 还提供可视化选项,帮助开发人员了解数据,例如直方图和汇总统计信息。它允许用户定义数据约束并检测数据集之间的错误、异常和漂移。这可以帮助您检测和诊断数据中的异常值、不一致和错误,以防止它们对模型造成问题。
当您使用 TFDV 验证数据时,它将检查数据是否具有预期的模式。如果存在任何差异,例如缺少列或数据类型错误的列,TFDV 将引发错误并提供有关问题的详细 信息。
在沃达丰,在将管道投入生产之前,会针对输入数据达成模式协议。该协议在产品经理/用例所有者、数据所有者、数据科学家和 ML 工程师之间达成。正如图 1 所示,我们在管道中首先要做的事情是生成有关数据的统计信息。
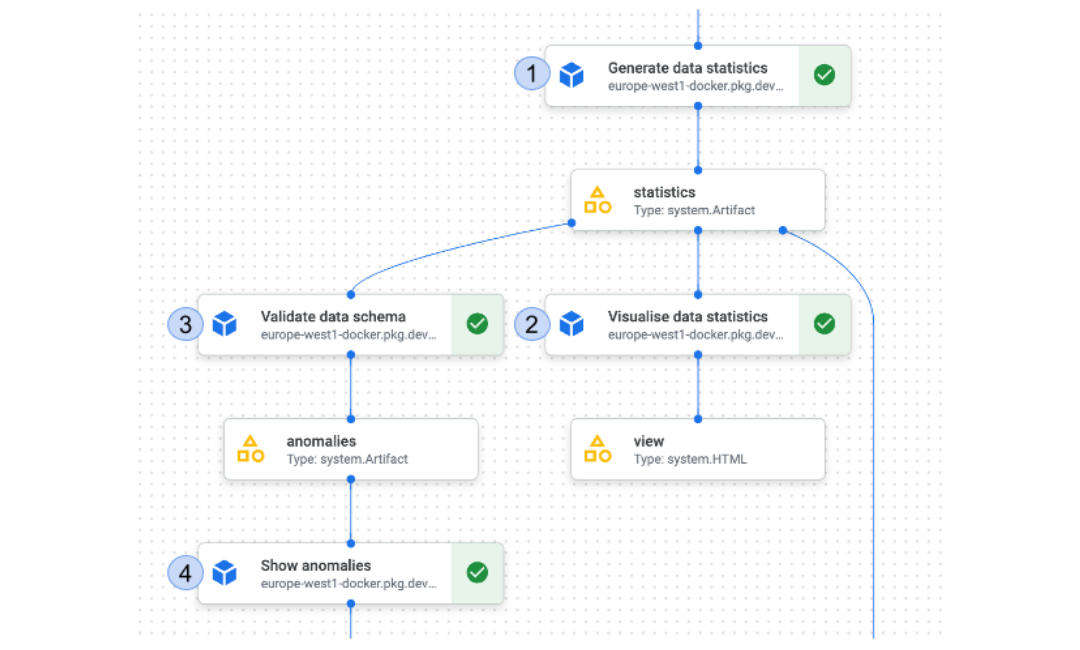 |
| 图 1:典型沃达丰训练管道中的数据契约组件 |
以下代码使用 TFDV 生成训练数据集的统计信息并对其进行可视化(步骤 2),从而可以轻松地了解数据的分布及其转换方式。此步骤的输出是一个 HTML 文件,显示有关输入数据集的一般统计信息。您还可以选择 HTML 网页上的各种功能来玩转统计信息,并更深入地了解数据。
# 生成训练统计信息 gen_statistics = generate_statistics( dataset=train_dataset.output, file_pattern=file_pattern, ).set_display_name("生成数据统计信息") # 可视化统计信息 visualised_statistics = visualise_statistics( statistics=gen_statistics.output, statistics_name="训练统计信息" ).set_display_name("可视化数据统计信息") |
步骤 3 与验证数据架构相关。在我们预定义的数据架构中,我们还为某些数据字段定义了一些阈值。我们可以对数据契约指定域约束,例如数值列的最小值和最大值,或分类列的允许值。当您验证数据时,TFDV 将检查数据集中的所有值是否都在指定的域内。如果任何值超出范围,TFDV 将提供警告并让您选择放弃或纠正数据。还可以指定数据契约中每个特征的值的预期分布。TFDV 将计算您数据的实际统计数据,如图 2 所示,并将它们与预期分布进行比较。如果有任何重大差异,TFDV 将提供警告并让您选择进一步调查数据。
此外,这使我们能够通过将您数据的实际统计信息与预期统计信息进行比较来检测数据中的异常值和异常现象(步骤 4)。它可以标记任何与预期分布显着偏离的数据点,并提供可视化来帮助您了解异常现象的性质。
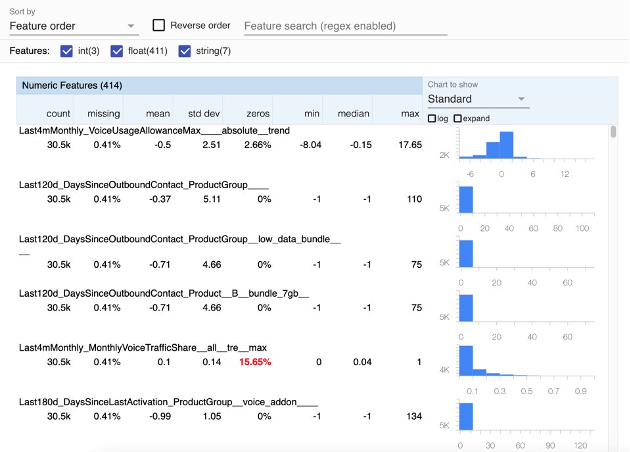 |
| 图 2:TFDV 生成的数据集统计信息的示例可视化 |
下面的代码使用 TFDV 库来验证数据架构并检测任何异常现象。validate_schema 函数接受两个参数:statistics 和 schema_path。Statistics 参数是先前步骤的输出,该步骤生成统计信息,而 schema_path 是在第一行中构建的数据架构文件路径。此函数检查数据是否符合数据架构文件中指定的数据架构。
# 从基础 GCS 路径 + 文件名构造 schema_path tfdv_schema_path = ( f"{pipeline_files_gcs_path}/{tfdv_schema_filename}" ) # 验证数据架构 validated_schema = validate_schema( statistics=gen_statistics.output, schema_path=tfdv_schema_path ).set_display_name("Validate data schema") # 显示异常现象,如果检测到任何异常现象则失败 anomalies = show_anomalies( anomalies=validated_schema.output, fail_on_anomalies=True ).set_display_name("Show anomalies") |
下一个代码块调用 show_anomalies 函数,该函数接受两个参数:anomalies 和 fail_on_anomalies。anomalies 参数是先前 validate_schema 函数的输出,其中包含检测到的任何异常现象。fail_on_anomalies 参数是一个标志,当设置为 true 时,如果检测到任何异常现象,将使管道失败。此函数将显示任何检测到的异常现象,看起来像这样。
anomaly_info { key: "producer_used" value { description: "示例包含数据架构中缺少的值:Microsoft (<1%)、Sony Ericsson (<1%)、Xiaomi (<1%)、Samsung (<1%)、IPhone (<1%)。 " severity: ERROR short_description: "意外的字符串值" reason { type: ENUM_TYPE_UNEXPECTED_STRING_VALUES short_description: "意外的字符串值" description: "示例包含数据架构中缺少的值:Microsoft (<1%)、Sony Ericsson (<1%)、Xiaomi (<1%)、Samsung (<1%)、IPhone (<1%)。 " } path { step: "producer_used" } } } |
所有上述组件都是使用自定义 KFP 组件和 TFDV 在内部开发的。
作为 AI Booster 平台的一部分,我们还为不同的建模库提供了模板,例如 XGBoost、TensorFlow、AutoML 和 BigQuery ML。这些模板基于 Kubeflow Pipelines (KFP) 管道,提供各种可定制组件,可以轻松地集成到您的机器学习工作流程中。
我们的模板为我们的数据科学家和机器学习工程师提供了一个起点,但它们完全可定制,以满足他们的特定需求。但是,当管道投入生产时,我们确实强制在管道中包含某些组件。如图 1 所示,我们要求所有生产管道都包含数据契约组件。这些组件不是特定于特定模型的,而是旨在在数据被用于训练或预测时使用。
自动化此步骤有助于我们的数据验证过程,使其更有效率且不易出现人为错误。它让所有利益相关者都确信,无论何时模型投入生产,模型使用的都是符合标准的数据,不会出现意外情况。此外,它还有助于使用本地数据在不同市场中复制用例。但最重要的是,它有助于合规性和隐私。它确保我们以符合公司政策和法规的方式使用数据,并提供一个框架来跟踪和监控数据的使用,以确保数据得到适当使用。
数据契约在确保机器学习模型中使用数据的质量和完整性方面发挥着至关重要的作用。数据契约提供
它们还有助于确保数据使用一致且可重现,这可以帮助提高模型的准确性和性能,并降低预测中出现错误和不准确的风险。与 TFDV 等工具一起使用的数据契约有助于自动化数据验证过程,使其更有效率且不易出现人为错误。将此概念应用于 AI Booster 帮助我们在沃达丰迈出了工业化 AI/ML 用例的关键一步。
有关 TFDV 的更多信息,请参见 tensorflow.org 上的 用户指南 和 教程。特别感谢沃达丰的 Amandeep Singh 和 Google Cloud 的 Max Vökler 为创建此设计和撰写本文做出的贡献。







