发布者:Mathieu Guillame-Bert、Richard Stotz、Luiz GUStavo Martins
两年前,我们 开源了 TensorFlow 决策森林 和 Yggdrasil 决策森林 的实验版本,这两个库用于在 TensorFlow 中训练和使用决策森林模型,例如随机森林和梯度提升树。从那时起,我们添加了许多新功能和改进。
 |
今天,我们很高兴地宣布 TensorFlow 决策森林已投入生产。在这篇文章中,我们将向您展示它附带的所有新功能 🙂。系好安全带!
决策森林是一种机器学习模型,它训练速度快,在表格数据集上表现非常好。非正式地说,决策森林由许多小的决策树组成。它们共同利用了 集体智慧原理,因此能够做出更好的预测。如果您想了解更多信息,请 查看我们的课程。
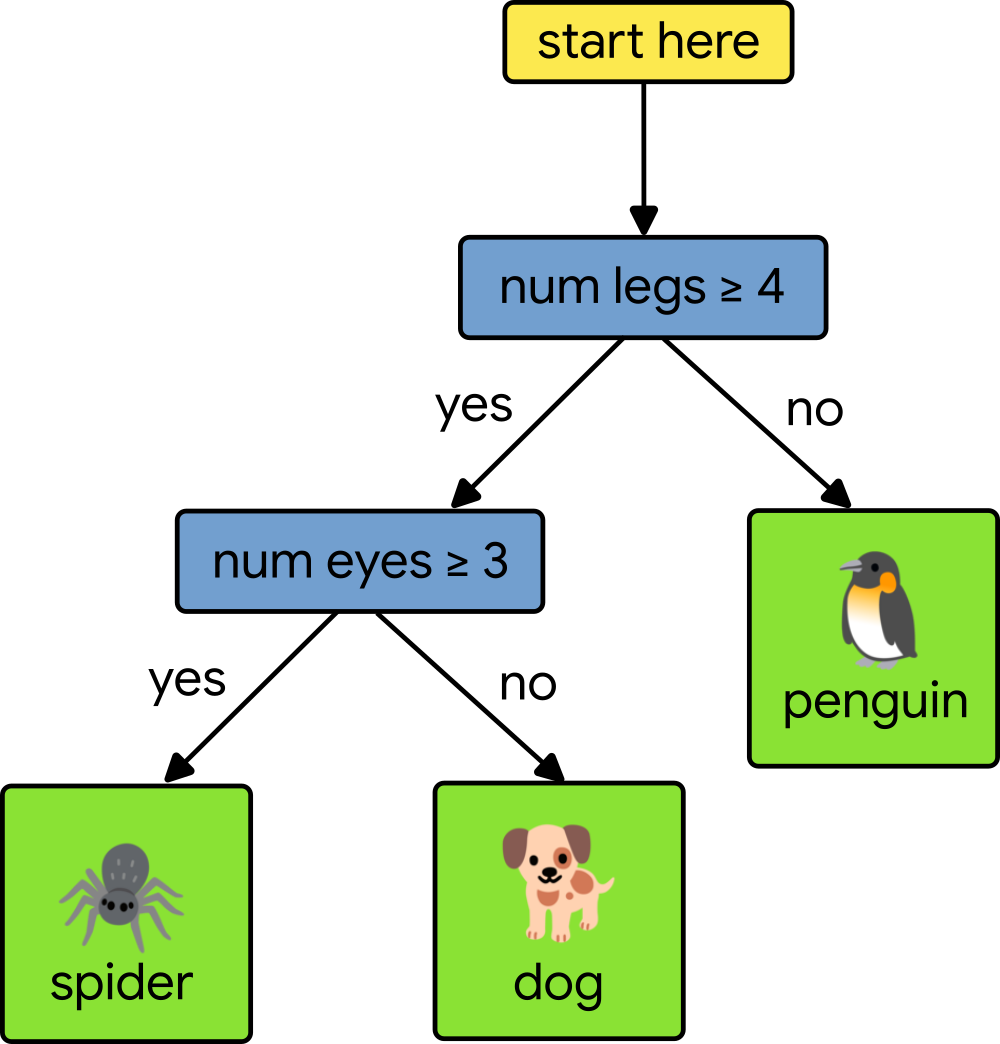 |
如果您是 TensorFlow 决策森林的新手,我们建议您尝试 初学者教程。以下是如何轻松使用 TF-DF
train_df = pd.read_csv("train.csv") train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="species") model = tfdf.keras.GradientBoostedTreesModel() model.fit(train_ds) model.save("my_model") |
以下是 TensorFlow 决策森林 (TF-DF) 在 1.x 版本中引入的主要新功能。
 |
与所有机器学习算法一样,决策森林也具有 超参数。这些参数的默认值可以得到不错的结果,但是,如果您真的想要为您的模型获得最好的结果,您需要“调整”这些参数。
TF-DF 使调整参数变得容易。例如,目标函数和分布配置会自动选择,您可以指定要调整的超参数,如下所示
tuner = tfdf.tuner.RandomSearch(num_trials=50) tuner.choice("min_examples", [2, 5, 7, 10]) tuner.choice("categorical_algorithm", ["CART", "RANDOM"]) tuner.choice("max_depth", [3, 4, 5, 6, 8]) tuner.choice("use_hessian_gain", [True, False]) tuner.choice("shrinkage", [0.02, 0.05, 0.10, 0.15]) tuner.choice("growing_strategy", ["LOCAL"]).choice("max_depth", [3, 4, 5, 6, 8]) tuner.choice("growing_strategy", ["BEST_FIRST_GLOBAL"], merge=True).choice("max_num_nodes", [16, 32, 64, 128, 256]) # ... Add all the parameters to tune model = tfdf.keras.GradientBoostedTreesModel(verbose=2, tuner=tuner) model.fit(training_dataset |
从 TF-DF 1.0 开始,您可以使用预配置的超参数调整搜索空间。只需在您的模型构造函数中添加 use_predefined_hps=True,调整过程就会自动完成
tuner = tfdf.tuner.RandomSearch(num_trials=50, use_predefined_hps=True) # 不需要配置每个超参数 tuned_model = tfdf.keras.GradientBoostedTreesModel(verbose=2, tuner=tuner) tuned_model.fit(train_ds, verbose=2) |
查看 超参数调整教程 以了解更多详细信息。并且,如果您的数据集很大,或者您有很多参数需要优化,您甚至可以使用 分布式训练来调整您的超参数。
如上所述,为了最大限度地提高模型质量,您需要调整超参数。但是,此操作需要时间。如果您没有时间调整超参数,我们为您提供了一种新的解决方案:超参数模板。
超参数模板是一组通过测试数百个数据集而发现的超参数。要使用它们,您只需设置 hyperparameter_template 参数。
model = tfdf.keras.GradientBoostedTreesModel(hyperparameter_template="benchmark_rank1") model.fit(training_dataset) |
在我们的论文 "Yggdrasil 决策森林:一个快速且可扩展的决策森林库" 中,我们通过实验证明了结果几乎与手动超参数调整一样好。
查看 超参数索引 中的“超参数模板”部分以了解更多详细信息。
 |
TensorFlow 决策森林现在包含在 TensorFlow Serving 的正式版本中,以及在 Google Cloud 的 Vertex AI 中。无需任何特殊配置或自定义镜像,您现在就可以在 Google Cloud 中运行 TensorFlow 决策森林。
查看我们的 TensorFlow Serving 示例。
 |
在少于一百万个示例的数据集上训练 TF-DF 几乎是即时的。但是,在更大的数据集上,训练需要更长的时间。TF-DF 现在支持分布式训练。如果您的数据集包含数百万甚至数十亿个示例,您可以在数十台甚至数百台机器上使用分布式训练。
以下是一个示例
cluster_resolver = tf.distribute.cluster_resolver.TFConfigClusterResolver() strategy = tf.distribute.experimental.ParameterServerStrategy(cluster_resolver) with strategy.scope(): model = tfdf.keras.DistributedGradientBoostedTreesModel( temp_directory=..., num_threads=30, ) model.fit_on_dataset_path( train_path=os.path.join(dataset_path, "train@60"), valid_path=os.path.join(dataset_path, "valid@20"), label_key="my_label", dataset_format="csv") |
为了使训练决策森林更加容易,我们创建了 Simple ML for Sheets。Simple ML for Sheets 使您能够在 Google 表格中训练、评估和解释 TensorFlow Decision Forests 模型,无需任何编码!
 |
完成在 Google 表格中训练模型后,您可以将其导出回 TensorFlow Decision Forests,并像其他模型一样使用它。
查看Simple ML for Sheets 教程以获取更多详细信息。
我们希望您喜欢阅读这篇新闻,并希望新版本的 TensorFlow Decision Forests 对您的工作有所帮助。
要了解更多关于 TensorFlow Decision Forests 库的信息,请参阅以下资源
如果您有任何问题,请在discuss.tensorflow.org上使用标签“TFDF”提出问题,我们会尽力提供帮助。再次感谢。
-- TensorFlow Decision Forests 团队


2023 年 2 月 14 日 — 由 Mathieu Guillame-Bert、Richard Stotz、Luiz GUStavo Martins 发表 两年前,我们 开源了 TensorFlow Decision Forests 和 Yggdrasil Decision Forests 的实验版本,这两个库用于在 TensorFlow 中训练和使用决策森林模型,例如随机森林和梯度提升树。从那以后,我们添加了许多新功能和改进。今天,我们很高兴地宣布...





