作者:Hugging Face 团队 🤗
语言模型在过去几年中蓬勃发展,这得益于 Transformer 架构 的出现。虽然 Transformer 可用于许多 NLP 应用,但其中一个特别引人注目:文本生成。它满足了自动化口头任务的实际目标,以及我们对未来与聊天机器人互动的梦想。
文本生成可以显著影响用户体验。因此,优化生成过程以提高吞吐量和延迟至关重要。在这方面,XLA 是加速 TensorFlow 模型的绝佳选择。需要注意的是,某些任务(如文本生成)并非天生对 XLA 友好。
Hugging Face 团队 最近添加了支持 在 🤗 transformers 中使用 XLA 加速的文本生成,用于 TensorFlow 模型。本文深入探讨了为使文本生成模型与 TensorFlow XLA 兼容而必须做出的设计选择。通过这些将 XLA 兼容性整合进来的改变,我们能够显著提高文本生成模型的速度,比以前快约 100 倍。
为了理解为什么 XLA 对文本生成的实现非同小可,我们需要更详细地了解文本生成,并找出最能从 XLA 中获益的领域。
基于 Transformer 架构的流行模型(例如 GPT2)依赖于自回归文本生成来产生其输出。自回归文本生成(也称为语言建模)是指模型被反复调用来预测下一个标记,给定到目前为止生成的标记,直到达到某个停止条件。以下是典型文本生成循环的示意图
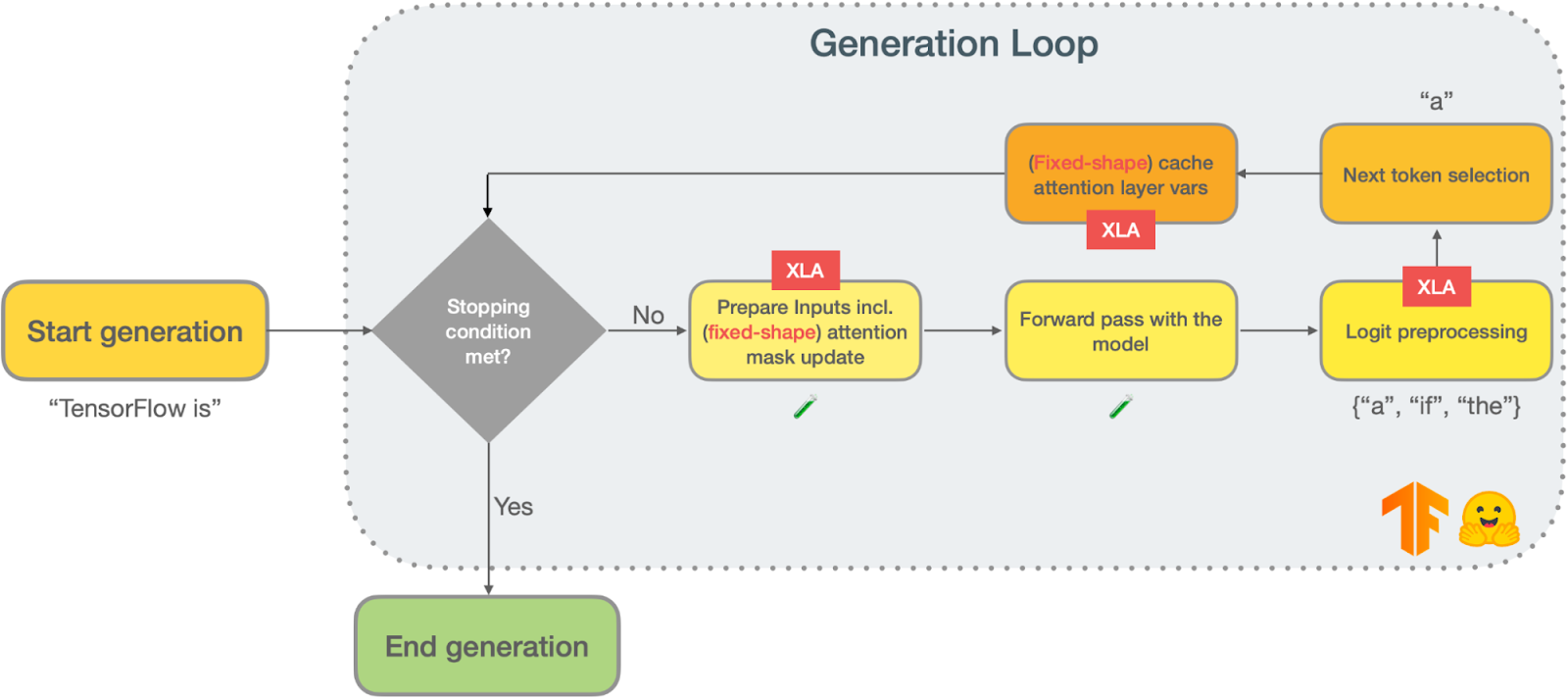 |
除了模型前向传递之外,任何自回归文本生成管道通常都包含两个主要阶段:logits 处理和下一个标记选择。
下一个标记选择
顾名思义,下一个标记选择是选择文本生成当前迭代的标记的过程。有几种策略可以执行下一个标记选择
您可以在 这篇博文中 阅读有关这些策略的更多信息。
Logit 预处理
文本生成中最不为人知的一步可能是模型前向传递和下一个标记选择之间的步骤。当使用文本生成模型执行前向传递时,您将获得每个标记的非归一化对数概率(也称为 logits)。在此阶段,您可以自由地操纵 logits 以赋予文本生成所需的行为。以下是一些示例
在您继续本文的 XLA 部分之前,您应该了解自回归文本生成的另一个技术方面。语言模型的输入是到目前为止生成的标记序列。因此,如果输入有 N 个标记,当前的前向传递将重复先前 N-1 个标记中的一些与注意力相关的计算。这些重复计算背后的实际细节值得(并且已经)有一篇博文来解释,即 GPT-2 图解。总之,您可以(并且应该)缓存来自掩蔽自注意力层的键和值,其中缓存的大小等于先前生成迭代中获得的输入标记数量。
在这里,我们确定了三个可以从 XLA 中获益的关键领域
作为 TensorFlow 用户,如果您想使用 XLA 编译您的函数,您必须首先确保它可以使用 tf.function 包装,并使用 AutoGraph 处理。对于自回归文本生成,您可以遵循许多不同的路径来完成它 - 本节将介绍 Hugging Face 🤗 做出的设计决策,但绝不是强制性的。
在急切执行和 XLA 启用的图模式之间切换应尽可能少地出现意外情况。对于 transformers 库团队来说,这一设计决策至关重要。急切执行为 TensorFlow 用户提供了与 TensorFlow 交互的简便界面,极大地改善了用户体验。为了保持类似的用户体验水平,我们必须减少 XLA 转换的摩擦。
控制流
如前所述,文本生成是一个迭代过程。您根据已生成的內容来调节输入,其中第一次生成通常以起始标记“播种”。但是,这种延续性不是无限的 - 生成过程将在满足停止条件时终止。
为了处理这种连续过程,我们求助于 while 语句。 AutoGraph 可以自动处理 大多数 while 语句,无需更改,但如果 while 条件是张量,则它将被转换为 tf.while_loop ,该循环由 tf.function 创建。使用 tf.while_loop,您可以指定哪些变量将在迭代之间使用,以及它们是否为形状不变(您无法使用常规的 Python while 语句来做到这一点,稍后将详细介绍)。
使用 `tf.while_loop` 来执行文本生成自回归循环的一个优点是,停止条件变得清晰可辨 - 它们是循环的终止条件,对应于它的 `cond` 参数。以下两个例子,我们采用了 `tf.while_loop` 并显式地指定了条件
有时,`for` 循环会对一组输入重复执行相同的操作,例如在处理束搜索的候选者时。 AutoGraph 的策略 将很大程度上取决于条件变量的类型,但还有不依赖于 AutoGraph 的其他选择。例如,向量化可能是一个强大的策略 - 不是对每个数据点/切片应用一组操作,而是对数据的某个维度应用相同的操作。然而,它也有一些缺点。对于向量化操作,跳过操作是不理想的,因此你应该权衡取舍。
在束搜索候选循环中,一些迭代可以跳过,因为您可以提前判断结果将不会被使用。跳过的迭代比例很低,而向量化的可读性优势相当大,因此我们采用了一种向量化策略来执行束搜索中的候选处理。 这里 是一个从这种向量化中获益的 logit 处理示例。
if 语句的各分支现在必须转换为函数调用,而且两个分支都必须返回相同数量和类型的输出。这种改变会影响复杂的逻辑处理器,例如防止生成特定标记的处理器。 这里 是一个例子,它展示了我们的 XLA 移植将过滤不希望的标记作为逻辑处理的一部分。数据结构
在文本生成中,许多数据结构没有一个静态维度,该维度取决于到目前为止生成了多少个标记。这包括
等等。尽管 tf.while_loop 允许你 使用跨迭代具有不同形状的变量,但此过程将触发重新跟踪,这应尽可能避免,因为重新跟踪计算量大。如果你想深入了解,可以参考 关于跟踪的官方评论。
这里的总结是,如果你不断地用相同输入张量形状和类型(即使它们有不同的数据)调用你的 tf.function 包装函数,并且不使用新的非张量输入,你就不会产生与跟踪相关的性能损失。
此时,你可能已经预料到为什么具有动态形状的循环对于文本生成来说不可取。特别是,模型的前向传递必须随着越来越多的生成标记作为其输入的一部分而重新跟踪,这将是不可取的。作为替代方案,我们对自回归文本生成的实现 使用静态形状 从最大可能的生成长度获得。由于 Transformer 架构中的注意力掩码机制,这些结构可以被填充并轻松忽略。类似地,当你的函数本身具有不同的可能的输入形状时,跟踪也是一个问题。对于文本生成,这个问题以相同的方式处理:你可以(也应该)填充你的输入提示以减少可能的输入长度。
基于 Transformer 的语言模型依赖于 位置嵌入 来处理输入标记,因为 Transformer 架构是置换不变的。这些位置嵌入通常是从结构的大小推导出来的。对于填充后的结构,这不再可能,因为输入序列的长度不再与生成标记的数量匹配。事实上,由于不同的模型在给定位置索引的情况下有不同的检索这些位置嵌入的方法,因此最直接的解决方案是在生成时使用标记的显式位置索引,并执行一些特定模型的手术来处理它们。
以下是我们进行的一些模型手术示例,这些手术使底层模型与 XLA 兼容
最后,为了让我们的用户了解 XLA 的潜在故障情况和限制,我们确保添加了信息丰富的代码内异常 (一个例子)。
总结一下,我们从一个简单的 TensorFlow 文本生成实现到一个 XLA 支持的实现的旅程包括
tf.while_loop 或矢量化替换依赖于张量的 for/while Python 循环条件;tf.cond 替换依赖于张量的 if/else 操作;Hugging Face 🤗 向 XLA 加速的 TensorFlow 文本生成的旅程充满了学习机会。但更重要的是,结果不言而喻:有了这些改变, **TensorFlow 文本生成可以比以前快 100 倍**!你可以在 这个 Colab 中自己尝试,并 在这里查看一些基准测试。
将 XLA 引入你的关键任务应用程序可以极大地影响降低成本和延迟。获得这些益处的关键在于理解 AutoGraph 和跟踪如何工作才能充分利用它们。查看本文中共享的资源,并试一试吧!
致谢
感谢 TensorFlow 团队为 XLA 提供支持。感谢 Joao Gante (Hugging Face) 领导了 🤗 Transformers 中 TensorFlow XLA 支持文本生成模型的开发。

2022 年 11 月 28 日 — 由 Hugging Face 团队 🤗 发布 语言模型在过去几年中随着 Transformer 架构 的出现而蓬勃发展。尽管 Transformers 可以用于许多 NLP 应用程序,但其中一个特别引人注目:文本生成。它迎合了自动化语言任务的实际目标,也迎合了我们对未来与聊天机器人的交互的梦想。文本生成可以极大地…





