https://blog.tensorflowcn.cn/2022/10/accelerating-tensorflow-on-intel-data-center-gpu-flex-series.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiggAhVjGLVpN-zQt2-nd7tSvZRLJW0qVeCvD7QMNuyTrH3IgCTZO0IWm-hq4wZtwZVdpiAHwi_NW3jjX1nBRwr16bVzfuRUyophmVIquDNkkvQ2bl3UMOG5viSeMG9HHl-xBO86xKg8agcGvKM5uqe9T9DGm8d2EYvuddIyUc6XlG-T-M6qVS-pIAj/s1600/Figure-2_PluggableDevice-diagram.png
英特尔 Jianhui Li、Zhoulong Jiang、Yiqiang Li 和 Google Penporn Koanantakool 发表
深度学习的普遍性推动了许多新型人工智能加速器的开发和部署。然而,使用户能够在这些硬件类型上有效地运行现有的人工智能应用程序是一个重大挑战。为了实现广泛采用,硬件供应商需要将他们的低级软件栈与高级人工智能框架无缝集成。另一方面,框架只能为市场上已经流行的初始设备添加特定于设备的代码 - 对于新的加速器来说这是一个鸡和蛋的问题。无法上游集成意味着硬件供应商需要维护他们定制的分支框架,并在每个新版本发布时重新集成到主要仓库,这既繁琐又不可持续。
认识到 TensorFlow 中需要模块化设备集成接口,英特尔和 Google 共同设计了 可插拔设备,这是一种机制,允许硬件供应商独立发布用于新设备支持的插件包,这些包可以与 TensorFlow 一起安装,而无需修改 TensorFlow 代码库。自可插拔设备在 TensorFlow 2.5 中发布以来,它一直是将新设备添加到 TensorFlow 的唯一方法。为了与原生设备实现功能对等,英特尔和 Google 还将分析 C 接口添加到 TensorFlow 2.7。TensorFlow 社区 迅速采用 可插拔设备,并一直在定期提交贡献以共同改进该机制。目前,有 3 个可插拔设备。今天,我们很高兴地宣布最新的可插拔设备 - 英特尔® TensorFlow 扩展*。
 |
| 图 1. Intel 数据中心 GPU Flex 系列 |
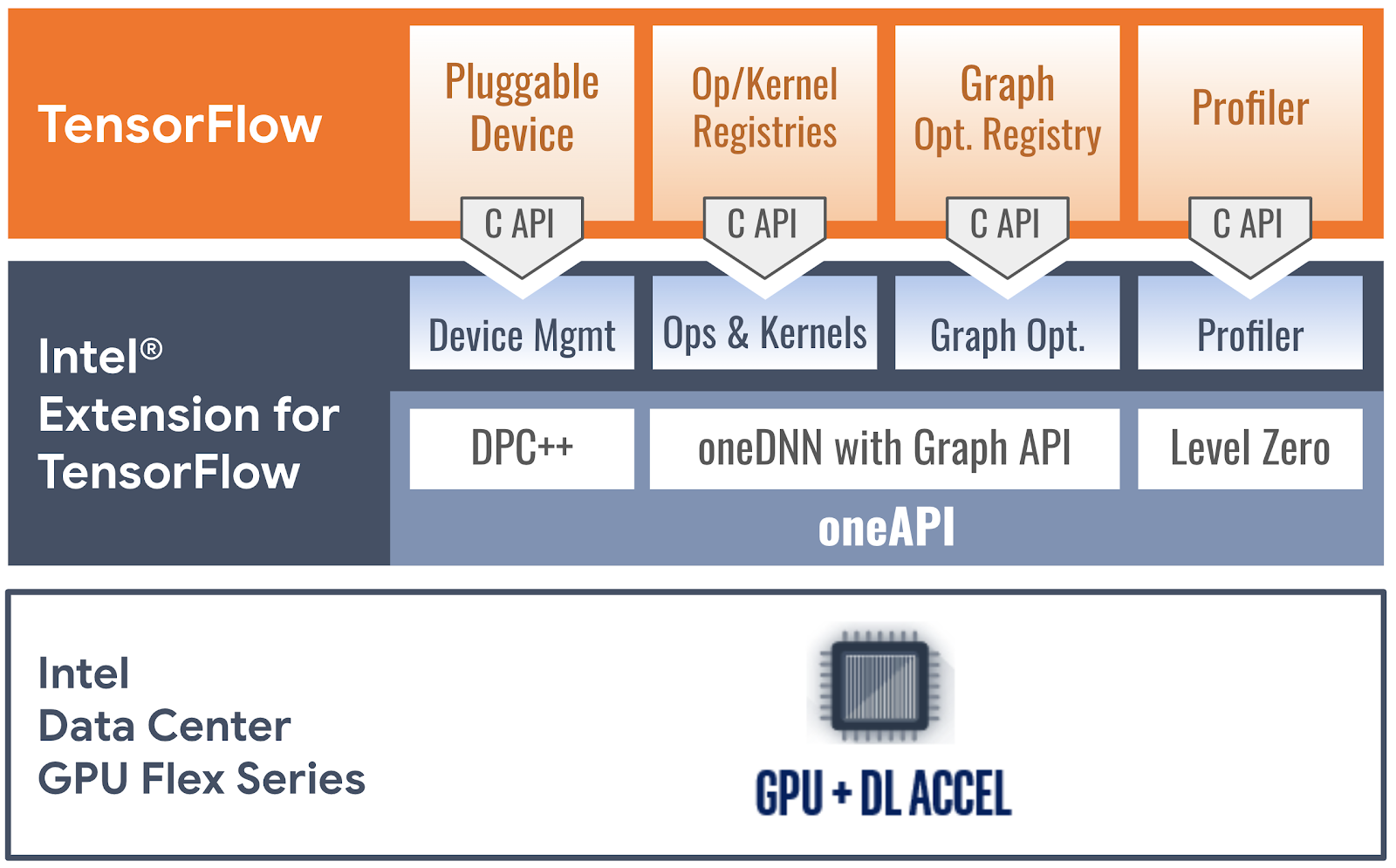
英特尔® TensorFlow 扩展* 在英特尔平台上加速基于 TensorFlow 的应用程序,重点关注英特尔的独立显卡,包括 Intel® 数据中心 GPU Flex 系列(图 1)和 Intel® Arc™ 显卡。它在 Linux 和 Windows 子系统 Linux (WSL2) 上运行。图 2 说明了插件如何使用 oneAPI 实现可插拔设备接口,oneAPI 是一种基于标准的开放统一编程模型,它在加速器架构之间提供一致的开发者体验。
- 设备管理:我们使用 C++ 和 SYCL 实现了 TensorFlow 的 StreamExecutor C API,以及 oneAPI SYCL 运行时提供的某些特殊支持(DPC++ LLVM SYCL 项目)。StreamExecutor C API 定义了流、设备、上下文、内存结构以及相关函数,所有这些函数都与 SYCL 运行时 中的相应实现具有简单的映射关系。
- 操作和内核注册:TensorFlow 的 内核和操作注册 C API 允许添加特定于设备的内核实现和自定义操作。为了确保足够的模型覆盖率,我们匹配了 TensorFlow 原生 GPU 设备的操作覆盖率,通过调用来自 oneAPI 深度神经网络库(oneDNN)的高度优化的深度学习原语,实现了大多数性能关键操作。其他操作使用 SYCL 内核或 Eigen 数学库实现。我们的插件将 Eigen 移植到使用 SYCL 的 C++,以便它可以生成程序来实现设备操作。
- 图形优化:Flex 系列 GPU 插件通过 图形 C API 在 Grappler 中优化 TensorFlow 图形,并通过 oneDNN 图形 API 将性能关键的图形分区卸载到 oneDNN 库。它从 TensorFlow 接收一个 protobuf 序列化的图形,反序列化图形,识别并用自定义操作替换适当的子图形,并将图形发送回 TensorFlow。当 TensorFlow 执行处理后的图形时,自定义操作将映射到与它们关联的 oneDNN 图形分区相应的 oneDNN 优化实现。
- 探查器:探查器 C API 允许可插拔设备以 TensorFlow 本地探查格式通信探查数据。Flex 系列 GPU 插件从 TensorFlow 获取序列化 XSpace 对象,使用通过 oneAPI Level Zero 低级设备接口获得的运行时数据填充对象,并将对象返回给 TensorFlow。用户可以使用 TensorFlow 的探查工具(如 TensorBoard)显示 Flex 系列 GPU 上特定操作的执行配置文件。
|
| 图 2. 英特尔® TensorFlow 扩展* 如何使用 oneAPI 软件组件实现可插拔设备接口 |
要安装插件,请运行以下命令
$ pip install tensorflow==2.10.0 $ pip install intel-extension-for-tensorflow[gpu] |
有关更详细的信息,请参阅
英特尔博客。对于英特尔® TensorFlow 扩展的特定问题和反馈,请
在此 提供反馈。
我们致力于与社区一起不断改进可插拔设备,以便设备插件能够尽可能透明地运行 TensorFlow 应用程序。如果您想将新设备与 TensorFlow 集成,请参阅我们的可插拔设备
教程 和
示例代码。我们期待通过可插拔设备在 TensorFlow 中启用更多 AI 加速器。
贡献者:Anna Revinskaya (Google)、Yi Situ (Google)、Eric Lin (Intel)、AG Ramesh (Intel)、Sophie Chen (Intel)、Yang Sheng (Intel)、Teng Lu (Intel)、Guizi Li (Intel)、River Liu (Intel)、Cherry Zhang (Intel)、Rasmus Larsen (Google)、Eugene Zhulenev (Google)、Jose Baiocchi Paredes (Google)、Saurabh Saxena (Google)、Gunhan Gulsoy (Google)、Russell Power (Google)






