https://blog.tensorflowcn.cn/2022/09/automated-deployment-of-tensorflow-models-with-tensorflow-serving-and-github-actions.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj6g9FPO3ZE-4rsM-yQ4JpMLg4NX4srfqKg8dudM4-gFz27p4eoDmpEIdv3ZVYEydArXWTx9NvdQ-VQ_h_8ZTYEcNyMMd9vc_x_BOy9AAQGTXJL--8JUcAKd4CJseNgV26AYsmnfrCWAPGs0Y5MDjSSVZ5HS5gUI_5Oxe9NzGNI9xNQGwxnICOwMPXS/s1600/Screen-Shot-2022-07-09-at-9-26-47-AM.png
发布者 Chansung Park 和 Sayak Paul (ML-GDEs)

如果您是应用程序开发人员,或者您的组织没有专门的 ML 工程团队,那么在部署机器学习模型时,通常不会考虑端到端的机器学习管道或 MLOps。 TFX 和 TensorFlow Serving 可以帮助您创建 MLOps 基础设施的核心。
在这篇文章中,我们将分享如何使用 TensorFlow Serving 在运行在 Google Kubernetes Engine (GKE) 上的 Kubernetes (k8s) 集群中,通过一组 GitHub Actions 工作流程,将 TensorFlow 图像分类模型作为 RESTful 和 gRPC 服务提供。
概述
在任何 GitHub 项目中,您可以创建 版本,在使用免费帐户时,每个版本最多可包含 2 GB 的资产。这是管理不同版本机器学习模型的好地方,原因有很多。还可以将其替换为更私密的组件来管理模型版本,例如 Google Cloud Storage 存储桶。就我们的目的而言,GitHub 版本提供的 2 GB 空间就足够了。
 |
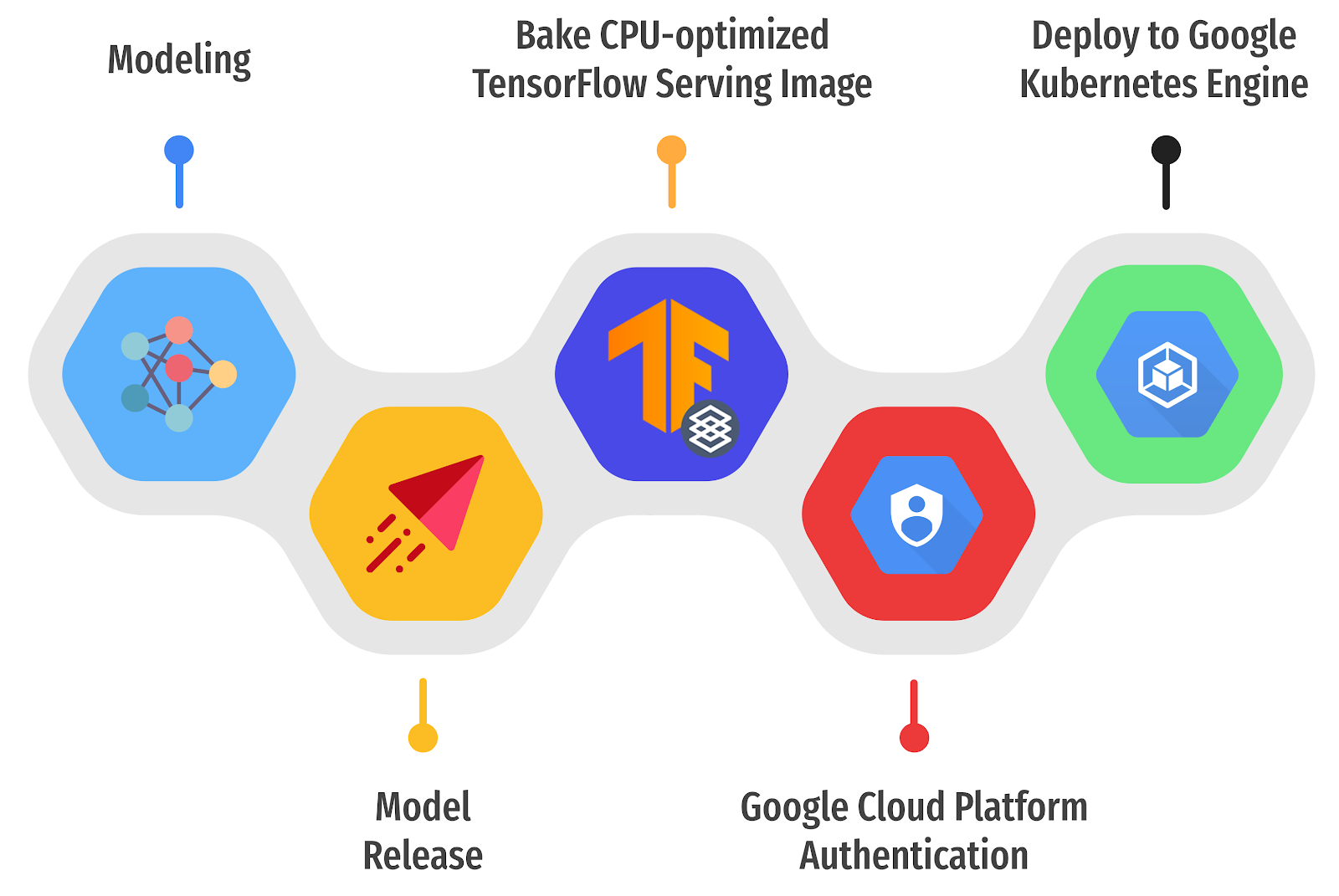
图 1. 在 GKE 上部署 TF Serving 的三个步骤(原文)。
|
基本思路是
- 自动检测 GitHub 版本中新发布的基于 TensorFlow 的 ML 模型版本
- 构建包含已发布 ML 模型的自定义 TensorFlow Serving Docker 镜像
- 通过一组 GitHub Actions 将其部署到运行在 GKE 上的 k8s 集群中。
整个工作流程在逻辑上可以分为三个子任务,因此编写三个单独的
复合 GitHub Actions 是个好主意
- 第二个子任务 构建自定义 TensorFlow Serving 镜像
- 从您的 GitHub 存储库中下载并解压缩您最新的已发布 SavedModel
- 运行 官方 或自定义构建的 TensorFlow Serving docker 镜像
- 将解压缩的 SavedModel 复制到正在运行的 TensorFlow Serving docker 容器中
- 提交正在运行的容器的更改,并使用特殊标记的新名称对其进行命名,以表示 GCR、GCP 项目 ID 和 latest
- 将提交的镜像推送到 GCR
- 第三个子任务 将自定义构建的 TensorFlow Serving 镜像部署到 GKE 集群
- 下载 Kustomize 工具包以处理覆盖配置
- 从各种 实验 中选择一个
- 根据所选实验将 Deployment、Service 和 ConfigMap 应用于当前连接的 GKE 集群
- ConfigMap 用于支持批处理的场景,以便将批处理配置动态地注入到 Deployment 中。
您可以自定义许多参数,例如 GCP 项目 ID、GKE 集群名称、将发布 ML 模型的存储库等等。参数的完整列表可以在
此处 找到。如上所述,GCP 凭据应事先设置为 GitHub Action 密钥。如果整个工作流程没有任何错误,您将看到类似于以下输出的内容。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tfs-server LoadBalancer xxxxxxxxxx xxxxxxxxxx 8500:30869/TCP,8501:31469/TCP 23m |
EXTERNAL-IP 和
PORT(S) 的组合代表外部用户可以连接到 k8s 集群中 TensorFlow Serving Pod 的端点。如您所见,公开了两个端口,
8500 和
8501 分别用于 RESTful 和 gRPC 服务。需要注意的是,我们使用了
LoadBalancer 作为服务类型,但您可能希望考虑包含
Ingress 控制器,例如
GKE Ingress,以使用 SSL/TLS 保护 k8s 集群,并在生产环境中定义更灵活的路由规则。您可以查看
过去运行 的完整日志。
在 GitHub Action 中构建自定义 TensorFlow Serving 镜像
如概述和 官方文档 中所述,可以分五个步骤构建自定义 TensorFlow Serving Docker 镜像。我们还提供了一个 笔记本 用于在本地测试这些步骤。在本节中,我们将展示如何为整个工作流程的这个部分子任务编写一个 复合 GitHub Action(注意,出于简洁起见,省略了 .inputs、.env 和 ${{ }} 用于环境变量)。
首先,可以使用外部 robinraju/release-downloader GitHub Action 下载模型,该 Action 包含有关 GitHub 存储库 URL 和最新版本资产列表中文件名的信息。默认文件名是 saved_model.tar.gz.
其次,应解压缩下载的文件以获取 TensorFlow Serving 可以理解的实际 SavedModel。
运行:
使用: "composite"
步骤:
- 名称: 下载 最新 SavedModel 版本
使用: robinraju/release-downloader@v1.3
带有:
仓库: $MODEL_RELEASE_REPO
文件名: $MODEL_RELEASE_FILE latest: true
- name: Extract the SavedModel
run: |
mkdir MODEL_NAME
tar -xvf $MODEL_RELEASE_FILE --strip-components=1 --directory $MODEL_NAME
- name: Run the CPU Optimized TensorFlow Serving container
run: |
docker run -d --name serving_base $BASE_IMAGE_TAG
- name: Copy the SavedModel to the running TensorFlow Serving container
run: |
docker cp $MODEL_NAME serving_base:/models/$MODEL_NAME
- id: push-to-registry
name: Commit and push the changed running TensorFlow Serving image
run: |
export NEW_IMAGE_NAME=tfserving-$MODEL_NAME:latest
export NEW_IMAGE_TAG=gcr.io/$GCP_PROJECT_ID/$NEW_IMAGE_NAME
echo "::set-output name=NEW_IMAGE_TAG::$(echo $NEW_IMAGE_TAG)"
docker commit --change "ENV MODEL_NAME $MODEL_NAME" serving_base $NEW_IMAGE_TAG
docker push $NEW_IMAGE_TAG |
第三,我们可以通过将自定义的 SavedModel 放入运行中的 TensorFlow Serving Docker 容器中来修改它。为此,我们需要运行从官方镜像或自定义构建的镜像实例化的基础 TensorFlow Serving 容器。我们使用 CPU 优化版本作为基础镜像,该镜像通过 从源代码编译获得,它已在 此处 公开提供。
第四,SavedModel 应复制到运行中的 TensorFlow Serving 容器内的 /models 目录中。在最后一步,我们设置了 MODEL_NAME 环境变量,以让 TensorFlow Serving 知道将哪个模型作为服务公开,并提交我们对基础镜像所做的这两个更改。最后,更新后的 TensorFlow Serving Docker 镜像可以被推送到指定的 GCR 中。
有关 TensorFlow Serving 参数的说明
在这篇文章中,我们考虑了三个 TensorFlow Serving 特定的参数:
tensorflow_inter_op_parallelism, tensorlfow_inter_op_parallelism 和批处理选项。在这里,我们简要概述了它们。
并行线程:
tesorflow_intra_op_parallelism 控制用于并行执行单个操作的线程数量。
tensorflow_inter_op_parallelism 控制用于并行执行多个独立操作的线程数量。要了解更多信息,请参考
此资源。
批处理:如上所述,我们可以通过将
enable_batching 参数设置为 True 来允许 TensorFlow Serving 批处理请求。如果我们这样做,我们还需要在单独的文件中定义 TensorFlow 的批处理配置(通过
batching_parameters_file 参数传递)。有关我们可以在该文件中指定的选项的更多信息,请参考
此资源。
配置 TensorFlow Serving
拥有自定义 TensorFlow Serving Docker 镜像后,您可以使用 k8s 资源对象(如
Deployment 和
ConfigMap)部署它,如下所示。本节介绍如何编写
ConfigMap 以写入批处理配置,以及如何编写
Deployment 以添加 TensorFlow Serving 特定的运行时选项。我们还将向您展示如何挂载
ConfigMap 以将批处理配置注入 TensorFlow Serving 的
batching_parameters_file 选项。
apiVersion: apps/v1 kind: Deployment ...
spec:
containers:
- image: gcr.io/gcp-ml-172005/tfs-resnet-cpu-opt:latest
name: tfs-k8s
imagePullPolicy: Always
args: ["--tensorflow_inter_op_parallelism=2",
"--tensorflow_intra_op_parallelism=8",
"--enable_batching=true",
"--batching_parameters_file=/etc/tfs-config/batching_config.txt"]
...
volumeMounts:
- mountPath: /etc/tfs-config/batching_config.txt
subPath: batching_config.txt
name: tfs-config
… |
在 Deployment 的 spec.containers.image 中可以指定自定义构建的 TensorFlow Serving Docker 镜像的 URI,并在 spec.containers.args 中提供参数来定制 TensorFlow Serving 的行为。这篇文章展示了如何配置三种类型的自定义行为:tensorflow_inter_op_parallelism、tensorflow_intra_op_parallelism 和 enable_batching。
apiVersion: v1 kind: ConfigMap
metadata:
name: tfs-config
data:
batching_config.txt: |
max_batch_size { value: 128 }
batch_timeout_micros { value: 0 }
max_enqueued_batches { value: 2 }
num_batch_threads { value: 2 } |
当 enable_batching 设置为 true 时,我们可以通过在 ConfigMap 中定义其特定的批处理相关配置来进一步定制批处理推理。然后,可以使用 spec.containers.volumeMounts 将 ConfigMap 作为文件挂载,并且可以在 Deployment 中的 batching_parameters_file 参数中指定要查找的配置文件。
使用 Kustomize 管理各种实验
如你所见,有许多参数可以决定 TensorFlow Serving 的行为,并且它们的最佳值通常需要通过运行实验来找到。实际上,我们在许多不同的环境设置中实验了各种参数:不同的节点数量、不同的 vCPU 内核数量以及不同的 RAM 容量。
├── base | ├──kustomization.yaml | ├──deployment.yaml | └──service.yaml
└── experiments
├── 2vCPU+4GB+inter_op2 ... ├── 4vCPU+8GB+inter_op2
... ├── 8vCPU+64GB+inter_op2_w_batch | ├──kustomization.yaml | ├──deployment.yaml | └──tfs-config.yaml
... |
我们使用 kustomize 来管理各种实验的 YAML 文件。我们将 Deployment 和 Service 的通用 YAML 文件保存在 base 目录中,而特定实验环境和配置的 YAML 文件则保存在 experiments 目录中。借助 kustomize,我们可以轻松地将 base YAML 文件中的内容覆盖为不同的副本数量、不同的 tensorflow_inter_op_parallelism、tensorflow_intra_op_parallelism、enable_batching 值以及批处理配置。
runs:
using: "composite"
steps:
- name: Setup Kustomize
...
- name: Deploy to GKE
working-directory: .kube/
run: |-
./kustomize build experiments/$TARGET_EXPERIMENT | kubectl apply -f - |
成本
我们为此目的使用了 GCP 成本估算器。假设每个实验配置每月运行 24 小时(这对我们的实验来说已经足够了)。
| 机器配置(E2 系列) | 价格(美元)
|
2 个 vCPU,4GB 内存,8 个节点
| 11.15 |
4 个 vCPU,8GB 内存,4 个节点
| 11.15 |
8 个 vCPU,16GB 内存,2 个节点
| 11.15
|
| 8 个 vCPU,64GB 内存,2 个节点 | 18.21 |
结论
在这篇文章中,我们讨论了如何使用各种配置自动部署和试验已经训练好的模型。我们利用 TensorFlow Serving、Kubernetes 和 GitHub Actions 来简化部署和实验过程。我们希望您发现此设置有用且可靠,并在您自己的模型部署项目中使用它。
致谢






