发布者 Zonglin Li,Lu Wang,Maxime Brénon 和 Yuqi Li,软件工程师

今天,我们很高兴宣布一个新的设备上基于嵌入的搜索库,它允许您在几毫秒内从数百万个数据样本中快速找到相似的图像、文本或音频。

它的工作原理是使用模型将搜索查询嵌入到一个高维向量中,该向量表示查询的语义含义。然后,它使用 ScaNN(可扩展最近邻)从预定义的数据库中搜索相似项。为了将其应用于您的数据集,您需要使用 Model Maker Searcher API (教程) 来构建自定义 TFLite Searcher 模型,然后使用 Task Library Searcher API (视觉/文本) 将其部署到设备上。
例如,使用在 COCO 上训练的 Searcher 模型,搜索查询 跑道上的客机 将返回以下图像
 |
| 图 1:所有图像均来自 COCO 2014 训练和验证数据集。 图像 1 由 Mark Jones Jr. 根据 署名许可 发布。 图像 2 由 305 Seahill 根据 署名-禁止演绎许可 发布。 图像 3 由 tataquax 根据 署名-相同方式共享许可 发布。 |
在这篇文章中,我们将带您逐步完成使用新的 TensorFlow Lite Searcher 库构建文本到图像搜索功能(根据文本查询检索图像)的端到端示例。以下是一些主要步骤
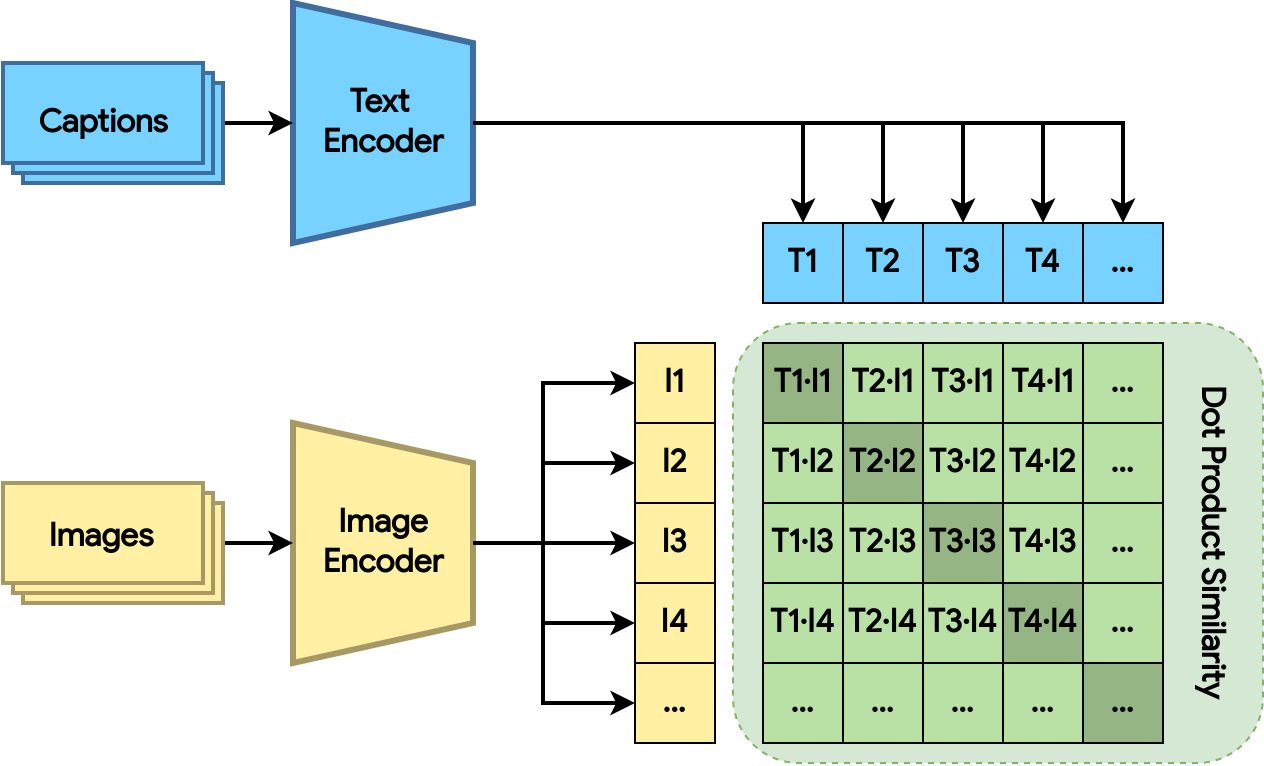 |
| 图 2:使用点积相似度距离训练双编码器模型。损失鼓励相关的图像和文本具有更大的点积(阴影绿色的正方形)。 |
双编码器模型由图像编码器和文本编码器组成。这两个编码器分别将图像和文本映射到高维空间中的嵌入。模型计算图像和文本嵌入之间的点积,损失鼓励相关的图像和文本具有更大的点积(更接近),而无关的图像和文本具有更小的点积(更远离)。
训练过程受到 CLIP 论文和这个 Keras 示例 的启发。图像编码器基于预训练的 EfficientNet 模型,文本编码器基于预训练的 通用句子编码器 模型。然后将来自两个编码器的输出投影到 128 维空间,并进行 L2 归一化。对于数据集,我们选择使用 COCO,因为它的训练和验证拆分对每个图像都包含人类生成的标题。请查看配套的 Colab 笔记本,了解训练过程的详细信息。
双编码器模型使得能够从数据库中检索没有标题的图像,因为一旦训练完成,图像嵌入器就可以直接从图像中提取语义含义,而无需任何人类生成的标题。
 |
| 图 3:使用图像编码器生成图像嵌入,并使用 Model Maker 创建 TFLite Searcher 模型。 |
一旦训练了双编码器模型,我们就可以使用它来创建 TFLite Searcher 模型,该模型根据文本查询从图像数据集中搜索最相关的图像。这可以通过以下三个步骤完成
#Configure ScaNN options. See the API doc for how to configure ScaNN.
scann_options = searcher.ScaNNOptions(
distance_measure='dot_product',
tree=searcher.Tree(num_leaves=351, num_leaves_to_search=4),
score_ah=searcher.ScoreAH(1, anisotropic_quantization_threshold=0.2))
# Load the image embeddings and corresponding metadata if any.
data = searcher.DataLoader(tflite_embedder_path, image_embeddings, metadata)
# Create the TFLite Searcher model.
model = searcher.Searcher.create_from_data(data, scann_options)
# Export the TFLite Searcher model.
model.export(
export_filename='searcher.tflite',
userinfo='',
export_format=searcher.ExportFormat.TFLITE)
在创建 Searcher 模型时,Model Maker 利用 ScaNN 对嵌入向量进行索引。嵌入数据集首先被划分为多个子集。在每个子集中,ScaNN 存储嵌入向量的量化表示。在检索时,ScaNN 选择几个最相关的分区,并使用快速、近似的距离对量化表示进行评分。此过程既节省了模型大小(通过量化),又实现了加速(通过分区选择)。查看 深入研究 了解更多关于 ScaNN 算法的信息。
在上面的示例中,我们将数据集划分为 351 个分区(大约是我们拥有的嵌入数量的平方根),并在检索过程中搜索其中的 4 个,大约是数据集的 1%。我们还将 128 维浮点嵌入量化为 128 个 int8 值,以节省空间。
 |
| 图 4:使用 Task Library 和 TFLite Searcher 模型运行推理。它接收查询文本并返回最邻近的元数据。从那里我们可以找到相应的图像。 |
要使用 Searcher 模型查询图像,您只需要使用 Task Library 编写几行代码,如下所示
from tflite_support.task import text
# Initialize a TextSearcher object
searcher = text.TextSearcher.create_from_file('searcher.tflite')
# Search the input query
results = searcher.search(query_text)
# Show the results
for rank in range(len(results.nearest_neighbors)):
print('Rank #', rank, ':')
image_id = results.nearest_neighbors[rank].metadata
print('image_id: ', image_id)
print('distance: ', results.nearest_neighbors[rank].distance)
show_image_by_id(image_id)尝试来自 Colab 的代码。此外,请查看有关如何使用 Task Library Java 和 C++ API(尤其是在 Android 上)集成模型的 更多信息。每个查询通常在 Pixel 6 上只需要 6 毫秒。
以下是一些示例结果
查询:骑自行车的人
结果根据近似相似度距离进行排名。以下是一些检索到的图像样本。请注意,我们只显示其许可证允许的图像。
 |
| 图 5:所有图像均来自 COCO 2014 训练和验证数据集。 图像 1 由 Reuel Mark Delez 根据 署名许可 发布。 图像 2 由 Richard Masoner / Cyclelicious 根据 署名-相同方式共享许可 发布。 图像 3 由 Julia 根据 署名-相同方式共享许可 发布。 图像 4 由 Aaron Fulkerson 根据 署名-相同方式共享许可 发布。 图像 5 由 Richard Masoner / Cyclelicious 根据 署名-相同方式共享许可 发布。 图像 6 由 Richard Masoner / Cyclelicious 根据 署名-相同方式共享许可 发布。 |
我们将致力于支持更多除图像和文本以外的搜索类型,例如音频片段。
如果您有任何反馈,请联系 odml-pipelines-team@google.com。我们的目标是让您更轻松地使用设备上机器学习,我们重视您的意见!
我们要感谢 Khanh LeViet、Chuo-Ling Chang、Ruiqi Guo、Lawrence Chan、Laurence Moroney、Yu-Cheng Ling、Matthias Grundmann 以及 Robby Neale、Chung-Ching Chang、Tom Small 和 Khalid Salama 对这项工作的积极支持。我们还要感谢整个 ScaNN 团队:David Simcha、Erik Lindgren、Felix Chern、Phil Sun 和 Sanjiv Kumar。

2022 年 5 月 11 日 — 发布者 Zonglin Li,Lu Wang,Maxime Brénon 和 Yuqi Li,软件工程师 今天,我们很高兴宣布一个新的设备上基于嵌入的搜索库,它允许您在几毫秒内从数百万个数据样本中快速找到相似的图像、文本或音频。它的工作原理是使用模型将搜索查询嵌入到一个高维向量中,该向量表示查询的语义含义。然后,它使用 ScaNN(可扩展最近邻)从预定义的数据库中搜索相似项。为了将其应用于您的数据集,您需要使用 Model Maker Searcher API (教程) 来构建自定义 TFLite Searcher 模型,然后使用 Task Library Searcher API (视觉/文本) 将其部署到设备上。





