发布者 Dan Kondratyuk、Liangzhe Yuan,Google 研究院和 Khanh LeViet,TensorFlow 开发者关系
我们很高兴地宣布 MoViNets(发音为“movie nets”),这是一个针对视频分类的新型移动优化模型架构系列。这些模型在 Kinetics-600 数据集 上进行了训练,能够识别 600 种不同的 人类动作(例如吹喇叭、机器人跳舞、保龄球等等),并可以实时对现代智能手机上捕获的视频流进行分类。您可以从 TensorFlow Hub 下载预训练的 TensorFlow Lite 模型,或者使用我们的 Android 和 Raspberry Pi 演示应用程序进行尝试,还可以使用 Colab 演示 和 TensorFlow 模型花园中的代码 微调您自己的 MoViNets。
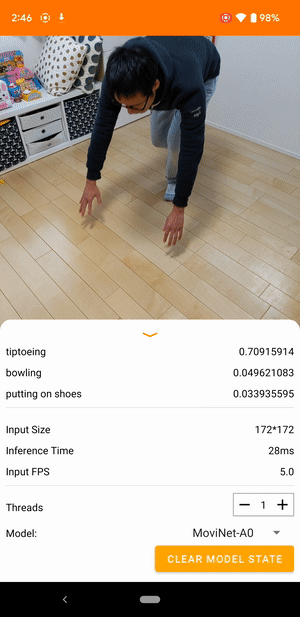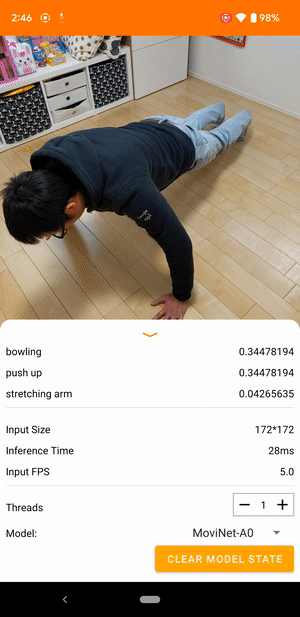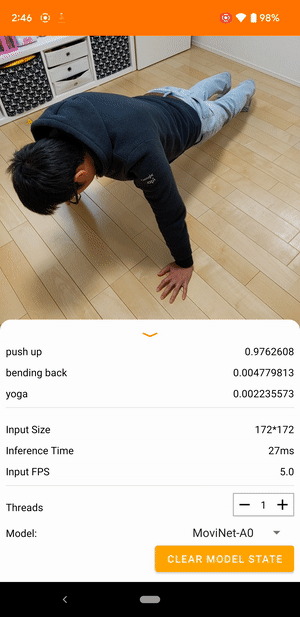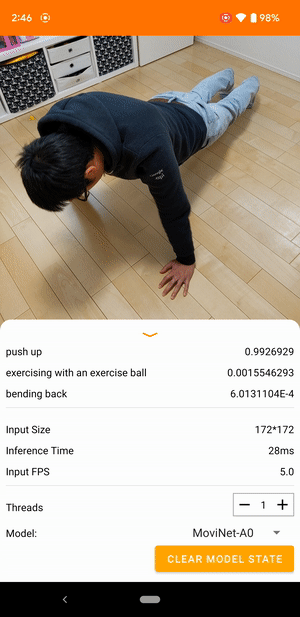 |
| 来自 TensorFlow Lite 视频分类参考应用程序的演示 |
视频分类是一项机器学习任务,它将视频帧作为输入,并从一组更大的类别中预测单个类别。视频动作识别是一种视频分类,其中预测的类别集由帧中发生的人类动作组成。视频动作识别类似于图像识别,两者都将输入图像作为输入并输出图像属于每个预定义类别的概率。但是,视频动作识别模型必须查看每个帧的内容以及相邻帧之间的空间关系,以了解视频中的动作。例如,如果您查看这些静止图像,很难说出这个人正在做什么。
 |
|
 |
但是,如果您观看完整的视频,就会清楚地看到这个人正在做跳绳运动。

MoViNets 是一个卷积神经网络系列,可以高效地处理视频流,在延迟仅为 3D ResNets 或基于变换器的分类器(如 ViT)的卷积视频分类器的一小部分的情况下,输出准确的预测。
基于帧的分类器对每个 2D 帧独立地输出预测,由于缺乏时间推理,导致性能低于最佳。另一方面,3D 视频分类器通过同时处理视频剪辑中的所有帧来提供高精度预测,但随着输入帧数的增加,会导致显着的内存和延迟损失。MoViNets 提供了来自 2D 基于帧的分类器和 3D 视频分类器的关键优势,同时减轻了它们的缺点。
下图显示了使用多剪辑评估的 3D 网络的典型方法,其中多个重叠子剪辑的预测被平均在一起。较短的子剪辑会导致较低的延迟,但会降低整体精度。
 |
| 说明了用于 3D 视频网络的多剪辑评估的图示 |
MoViNets 采用混合方法,建议使用 因果卷积 来代替 3D 卷积,从而允许使用流缓冲区跨帧缓存中间激活。流缓冲区复制所有 3D 操作的输入激活,这些操作由模型输出,然后在下一个剪辑输入时输入回模型。
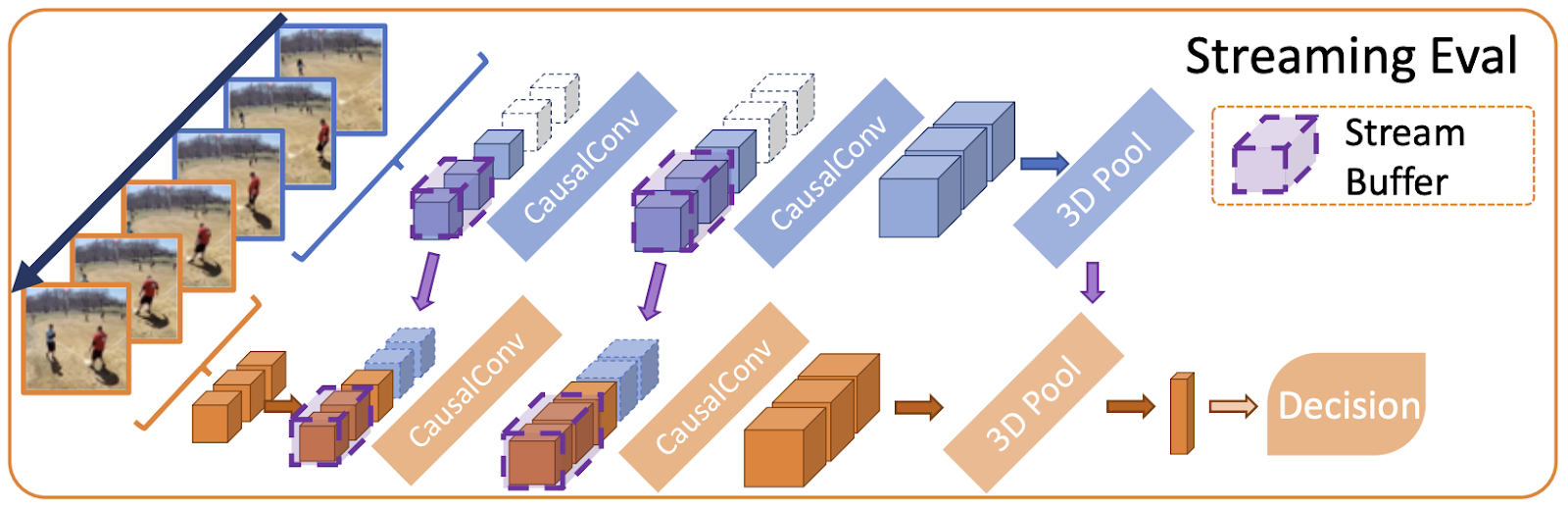 |
| 说明了 MoViNets 的流式评估的图示 |
结果是 MoViNets 可以一次接收一帧输入,从而减少峰值内存使用量,同时不会损失精度,预测结果等同于像 3D 视频分类器一样一次输入所有帧。MoViNets 还利用了 神经架构搜索 (NAS),通过在视频数据集(特别是 Kinetics 600)上搜索网络宽度、深度和分辨率上的模型高效配置。
结果是一组动作分类器,可以输出随时间稳定的预测,这些预测会根据帧内容平滑过渡。以下是一个 MoViNet-A2 在滑板视频剪辑的每一帧上进行预测的示例图。请注意,初始场景的运动量较少,预测相对恒定,而下一个场景的运动量更大,导致预测类别发生巨大变化。
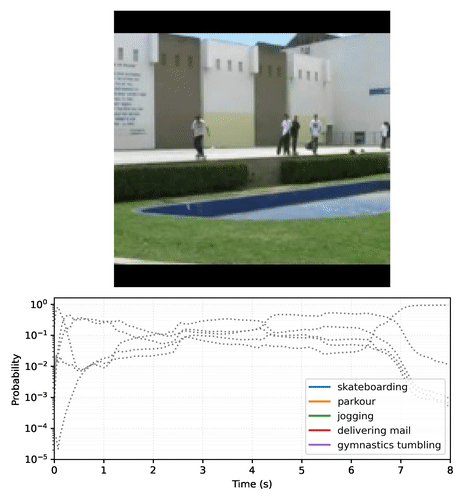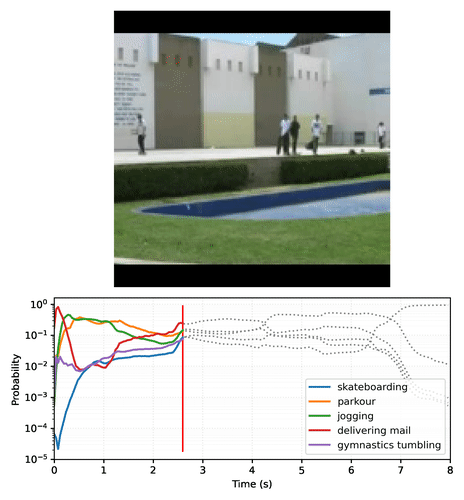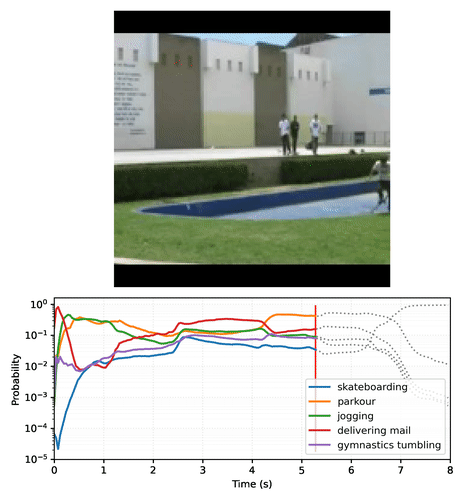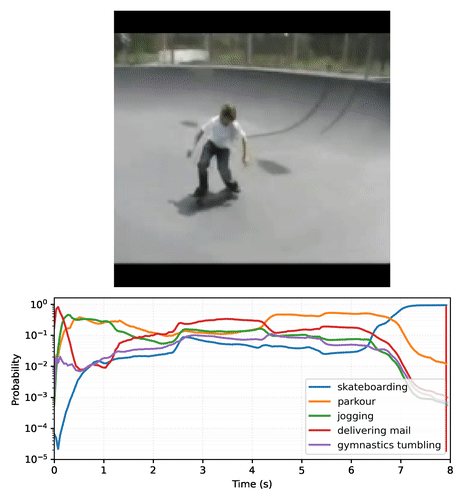 |
| 视频绘制了 MoViNet-A2 在 8 秒(25 帧/秒)滑板视频剪辑的示例上随时间的推移的前 5 个预测。使用 此 Colab 笔记本 创建您自己的图表。 |
MoViNets 需要进行一些修改才能在边缘设备上有效运行。我们从 MoViNet-A0-Stream、MoViNet-A1-Stream 和 MoViNet-A2-Stream 开始,它们代表可以在实时(20 帧/秒或更高)有效运行的较小模型。为了有效地量化 MoViNet,我们对模型架构进行了一些修改 - 硬 swish 激活被 ReLU6 替换,并且在原始架构中删除了 压缩和激励 层,这会导致 Kinetics-600 上的精度下降 3-4 个百分点。然后,我们将模型转换为 TensorFlow Lite 并使用 基于整数的训练后量化(以及 float16 量化)来减小模型尺寸,并在移动 CPU 上加快运行速度。基于整数的训练后量化过程会导致精度进一步下降 2-3 个百分点。与原始 MoViNets 相比,量化后的 MoViNets 在完整 10 秒 Kinetics 600 剪辑上的精度有所下降(总共下降 5-7 个百分点),但在实践中,它们能够对日常人类动作(例如俯卧撑、跳舞和弹钢琴)提供非常准确的预测。将来,我们计划使用 量化感知训练 来弥合这一精度差距。
我们在真实硬件上对量化后的 A0、A1 和 A2 进行基准测试,模型推断时间在 Pixel 4 CPU 上分别达到 200、120 和 60 帧/秒。在实践中,由于输入管道开销,我们在使用摄像头作为输入在 Android 上运行时,会看到更接近 20-60 帧/秒的延迟增加。
训练自定义模型
您可以使用 TensorFlow 模型花园中的 MoViNet 代码库 训练您自己的视频分类器模型。提供的 Colab 笔记本 提供了有关如何在另一个数据集上微调预训练的视频分类器的具体步骤。
未来步骤
我们很高兴看到由 MoViNets 提供支持的设备上在线视频动作识别,它展示了高效的性能。将来,我们计划支持 MoViNets 的量化感知训练,以减轻量化精度损失。我们还对将 MoViNets 扩展为更多设备上视频任务(例如视频目标检测、视频目标分割、视觉跟踪、姿态估计等)的骨干感兴趣。
致谢
我们要感谢 Yeqing Li 在 TensorFlow 模型花园中支持 MoViNets,Boqing Gong、Huisheng Wang 和 Ting Liu 提供项目指导,Lu Wang 提供代码审查,以及 TensorFlow Hub 团队托管我们的模型。

2022 年 4 月 14 日 — 发布者 Dan Kondratyuk、Liangzhe Yuan,Google 研究院和 Khanh LeViet,TensorFlow 开发者关系 我们很高兴地宣布 MoViNets(发音为“movie nets”),这是一个针对视频分类的新型移动优化模型架构系列。这些模型在 Kinetics-600 数据集 上进行了训练,能够识别 600 种不同的 人类动作(例如吹喇叭、机器人跳舞、保龄球等等)






