mPOD, Inc. 的 CEO Jeffrey Ly 和 CMO Joanna Ashby 的客座文章。
mPOD 是一家获得 NIH 资助的种子前创业公司,总部位于纽约市的强生创新中心(JLABS)。在这篇文章中,我们想与大家分享我们在 mPOD 独立开发的一款硬件设备,该设备将 TensorFlow Lite Micro (TFLM) 作为核心技术,名为 DxTrack。

mPOD DxTrack 利用 TFLM 和低成本硬件,能够在不到 10 秒的时间内对目前可用的侧向流动分析 (LFA) 进行准确、快速和客观的解读。LFA 作为诊断工具,因为它们成本低廉且易于使用,无需特殊技能或设备。LFA 最近因 COVID-19 快速抗原检测而广受欢迎,也广泛用于检测怀孕、疾病追踪、性病、食物不耐受和治疗药物,以及大量生物标志物,每年售出数十亿次检测。mPOD Dxtrack 可用于任何类型的视觉读取侧向流动分析,展示了 TFLM 的医疗用例,可以对我们的日常生活产生直接影响。
LFA 从将样本(鼻拭子、唾液、尿液、血液等)加载到下图中的 (1) 开始。样本流到绿色结合区 (2) 后,它会被标记上信号部分。通过毛细作用,样本将继续流动,直到在 (3) 被固定,对于这些 LFA 测试,两条线表示阳性结果,一条线表示阴性结果。
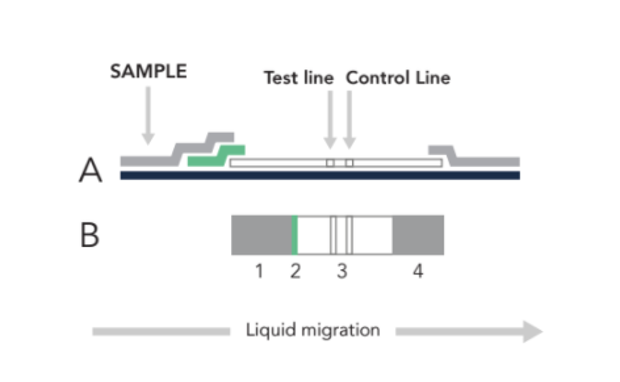 |
| 图 1. 侧视图 (A) 和顶视图 (B) 的侧向流动分析 (LFA) 样本,其中样本(鼻拭子、唾液、尿液、血液等)在 (1) 被加载,然后流到绿色区域 (2),在那里目标被标记上信号部分。通过毛细作用,样本将继续流动,直到在 (3) 被固定以形成测试线。多余的材料在 (4) 被吸收。 |
 |
| 图 2. 这是侧向流动分析 (LFA) 测试的 3 种可能的结果类别。 |
 |
| 图 3. 这是 NOWDiagnostics ADEXUSDx 侧向流动分析 (LFA) 的示意图,用于在护理点 (POC) 和非处方 (OTC) 环境中收集和运行唾液样本。 |
当正确使用时,这些测试非常有效;但是,自我测试对普通用户进行解释提出了挑战。设备之间存在显著的差异,难以判断你看到的测试线是阴性……还是一个微弱的阳性?
 |
| 图 4. mPOD DxTrack 上的 TinyML 模型如何解释和分类不同侧向流动分析 (LFA) 结果的直观表示。 |
为了应对这一挑战,我们开发了 mPOD DxTrack,这是一款非处方 (OTC) LFA 阅读器,通过使用简单、成本低于 5 美元 (商品成本) 的全球可部署设备,实现快速客观读取,从而提高侧向流动分析的效用。mPOD DxTrack 旨在使用机器学习读取侧向流动分析测试,以实现两个目标:1) 实现对 LFA 的快速客观读取,2) 简化数字报告。重要的是,TinyML 允许将 mPOD DxTrack 上的软件部署在低成本 (低于 5 美元) 的硬件上,可以广泛分发 - 对于依赖于高成本/高复杂度硬件的现有 LFA 阅读器来说,这是很困难的,因为每个单元的成本高达数百至数千美元。最终,我们相信 TinyML 将使 mPOD DxTrack 能够通过消除人为偏差并提高对侧向流动设备测试的信心来发现被遗漏的阳性测试结果,减少用户错误并提高总体结果准确性。
 |
| 图 5. mPOD DxTrack 与侧向流动分析 (LFA) 盒的组装视图。 |
技术深入
关键考量因素
TinyML 的模型尺寸约束
在 Pico4ML Dev 套件上部署 DxTrack TinyML 模型受到两块硬件的限制:闪存和 SRAM。Pico4ML Dev 套件有 2 MB 的闪存用于存储 .uf2 文件,以及 264 KB 的 SRAM 用于容纳模型的中间数组(以及其他内容)。确保模型尺寸保持在这些界限内至关重要,因为虽然代码可以成功编译、在主机上运行,甚至可以成功闪存到 Pico4Ml Dev 套件,但在设置过程中会挂起,而不会执行主循环。
我们并没有去猜测和检查中间数组的大小(我们最初采用的过程,几乎没有可重复的成功),而是开发了一种工作流程,使我们能够通过首先使用解释器函数来量化模型的区域大小。请看下面的示例,其中此函数在设置过程中被调用
TfLiteStatus setup_status = ScreenInit(error_reporter);
if (setup_status != kTfLiteOk){
while(1){TF_LITE_REPORT_ERROR(error_reporter, "Set up failed\n");};
}
arena_size = interpreter->arena_used_bytes();
printf("Arena_Size Used: %zu \n", arena_size);打印出来后,解释器函数的值在 Pico4ML Dev 套件启动期间应如下所示
DEV_Module_Init OK
Arena_Size Used: 93500
sd_spi_go_low_frequency: Actual frequency: 122070
V2-Version Card
R3/R7: 0x1aa
R3/R7: 0xff8000
R3/R7: 0xc0ff8000
Card Initialized: High Capacity Card
SD card initialized
SDHC/SDXC Card: hc_c_size: 15237
Sectors: 15603712
Capacity: 7619 MB
sd_spi_go_high_frequency: Actual frequency: 12500000
有了这个值,我们就可以设置合适的 TensorArenaSize。从上面可以看到,该模型使用 93500 字节的 SRAM。通过将 TensorArenaSize 设置为略高于该数值 99x1024 = 101376 字节,我们能够分配足够的内存来容纳模型,而不会超过硬件限制(这也会导致 Pico4ML Dev 套件冻结)。
// An area of memory to use for input, output, and intermediate arrays.
constexpr int kTensorArenaSize = 99* 1024; // 136 * 1024; //81 * 1024;
static uint8_t tensor_arena[kTensorArenaSize];从非量化模型转换为量化模型
现在,我们拥有了一种可重复的方法来量化和将模型部署到 Pico4ML Dev 套件,我们的下一个挑战是确保模型能够在符合硬件尺寸约束的情况下,达到我们所需的准确率。作为参考,mPOD DxTrack 平台设计用于解释 96x96 像素的图像。在原始的模型设计中,我们能够使用模型实现 > 99.999% 的准确率,但中间层是 96x96x32 的 fp32,需要超过 1 MB 的内存 - 它无法容纳在 Pico4ML Dev 套件的 264 KB SRAM 中。为了满足模型的尺寸要求,我们需要将模型从非量化转换为量化;我们最好的选择是利用完整的 int8 量化。本质上,我们不是将张量值视为浮点数 (float32),而是将这些值关联到整数 (int8)。不幸的是,这使模型尺寸缩小了 4 倍,使其能够容纳在 Pico4ML Dev 套件上,但从 fp32 到 int8 的舍入误差叠加,导致模型性能急剧下降。
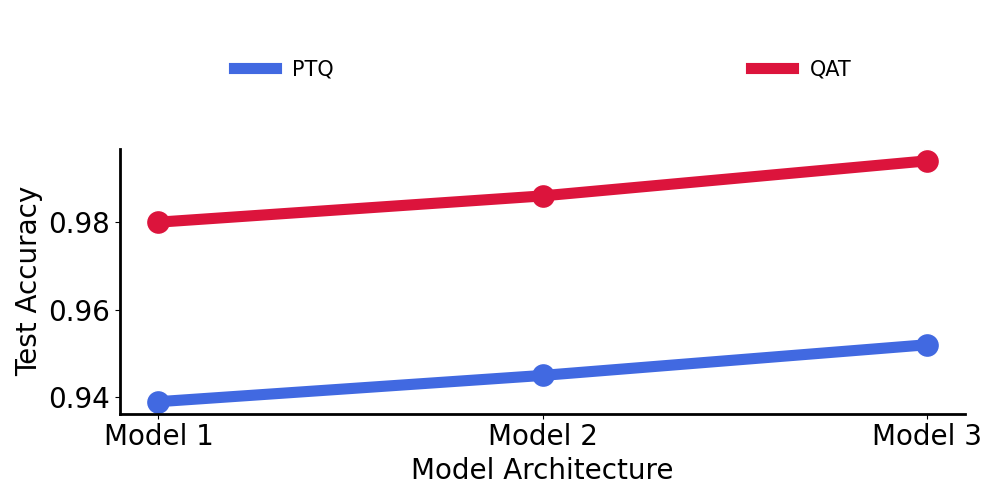
为了解决模型性能下降的问题,我们研究了两种不同的量化策略对性能的影响:训练后量化 (PTQ) 和量化感知训练 (QAT)。
下面,我们比较了 3 种不同的模型,以了解哪种量化策略最佳。作为参考
我们可以看到,量化感知训练 (QAT) 始终优于训练后量化 (PTQ) 方法,它也成为我们后续工作流程的一部分。
我们现在能够实现什么性能?
经过 800 多次真实世界的测试运行,mPOD DxTrack 的总体准确率可以初步达到 98.7%。我们目前正在与我们密切合作的制造合作伙伴网络一起评估这个版本的模型。我们目前正在组建一个独特的图像数据集,作为以患者为中心的数据管道的一部分,从每个制造合作伙伴那里学习并构建定制模型。

我们的初步工作也帮助我们将模型性能与适当的大型数据集尺寸相关联,以实现医疗应用所需的足够高准确率。根据附图,模型需要在一个至少有 15,000 张图像的高质量数据集上进行训练。我们的商业级目标可能需要超过 100,000 张图像的数据集。

要了解更多关于 mPOD Inc 的信息,请访问我们的网站 www.mpod.io。如果您有兴趣了解更多关于 TinyML 的信息,我们建议您查看这本 书 和这个 课程。
2022 年 3 月 28 日 — mPOD, Inc. 的 CEO Jeffrey Ly 和 CMO Joanna Ashby 的客座文章。mPOD 是一家获得 NIH 资助的种子前创业公司,总部位于纽约市的强生创新中心(JLABS)。在这篇文章中,我们想与大家分享我们在 mPOD 独立开发的一款硬件设备,该设备将 TensorFlow Lite Micro (TFLM) 作为核心技术,名为 DxTrack。mPOD DxTrack 利用 TFL…





