Chansung Park 和 Sayak Paul(ML-GDE)的客座文章
持续集成和交付 (CI/CD) 是 DevOps 领域中备受关注的话题。在 MLOps(机器学习 + 运营)领域,我们还有另一种形式的连续性 - 持续评估和再训练。MLOps 系统根据世界变化而演变,这通常是由 数据/概念漂移 造成的。因此,为了适应数据变化,我们需要持续评估已部署的 ML 模型,并根据需要对其进行再训练和重新部署。
在这篇博文中,我们介绍了一个项目,该项目实现了结合批处理预测和模型评估的工作流程,以进行持续评估再训练,从而捕获数据中的变化。我们将首先讨论项目的总体设置。然后我们将继续介绍对持续评估 ML 模型然后根据需要重新训练它至关重要的关键组件(批处理预测、新数据范围、再训练等)。我们不会讨论项目的技术实施细节,而是将其保持在高层,以便我们专注于理解底层概念。
该项目使用 TensorFlow Extended (TFX)、Keras 和 Google Cloud Platform 提供的各种服务实现。你可以在 GitHub 上找到该项目。
此项目展示了如何构建两个独立的管道来协同工作,以创建响应数据变化的 CI/CD 工作流程。第一个管道用于模型训练,第二个管道用于基于批处理预测结果的模型评估,如图 1 所示。
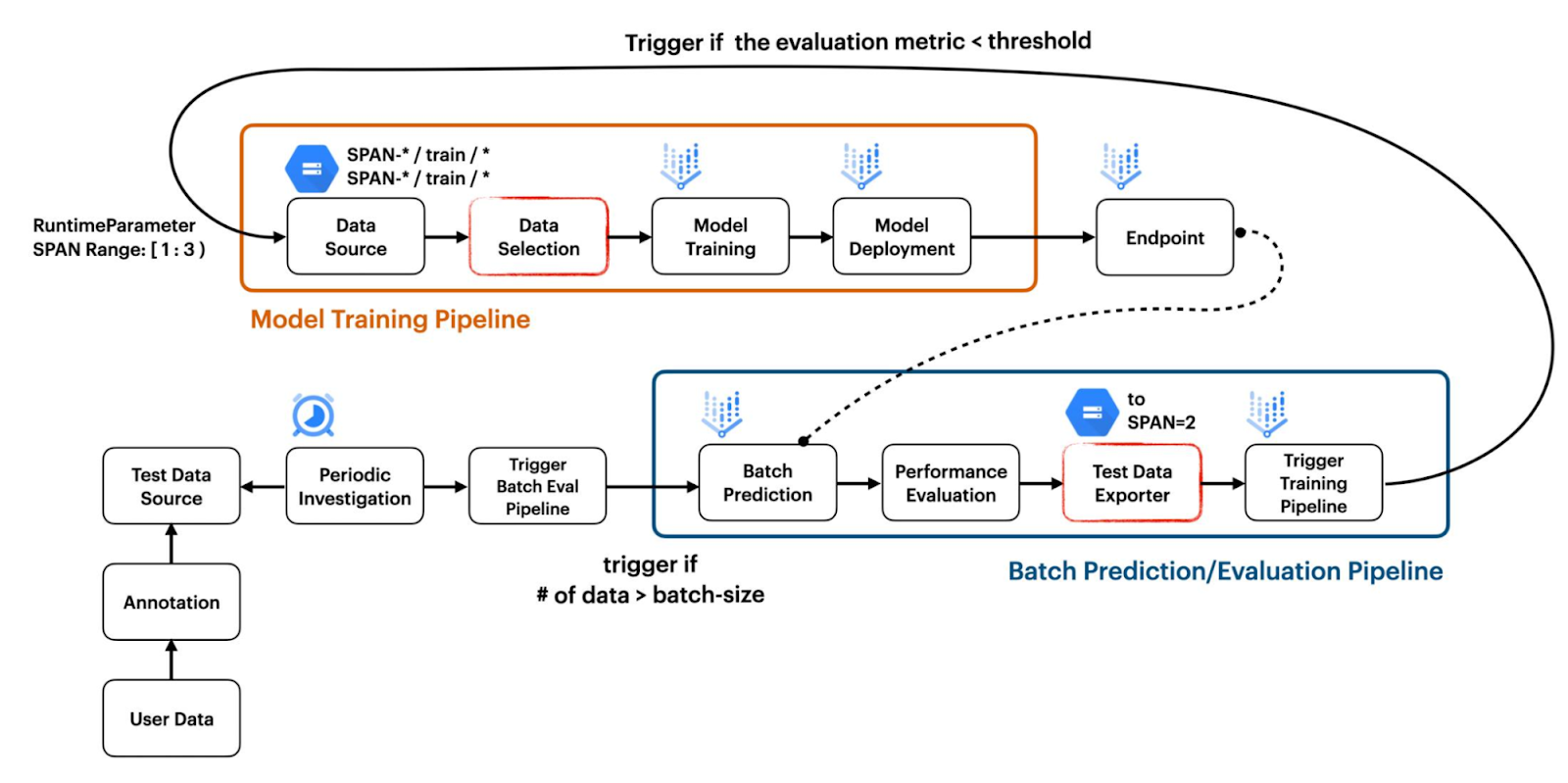 |
| 图 1. 项目结构概述 (原始) |
模型训练管道通过将标准 TFX 组件(如 ImportExampleGen 和 Trainer)与自定义 TFX 组件(如 VertexUploader 和 VertexDeployer)相结合来构建。由于 Pusher 标准组件在我们进行此项目时存在问题,我们从我们之前的项目 双部署 中引入了自定义组件。
ImportExampleGen 如何处理要馈送到模型的数据集,这有一个重要的实施细节。我们设计了我们的项目,将来自不同分布的数据集存储在具有文件系统路径的单独文件夹中,这些路径指示跨度编号。例如,初始训练和测试数据集可以存储在 SPAN-1/train 和 SPAN-2/test 中,而漂移数据集可以分别存储在 SPAN-2/train 和 SPAN-2/test 中,如图 2 所示。
为了 Google Cloud Storage (GCS) 中的版本控制功能,你可能会认为我们不需要以这种方式管理数据集。但是,我们认为我们的方法使数据集更易于管理。例如,你可能想要选择来自 SPAN-1 和 SPAN-2 或 SPAN-1 和 SPAN-3 的数据来训练模型,具体取决于情况。此外,属于同一分布的数据集仍然可以从 GCS 中的版本控制功能中受益。
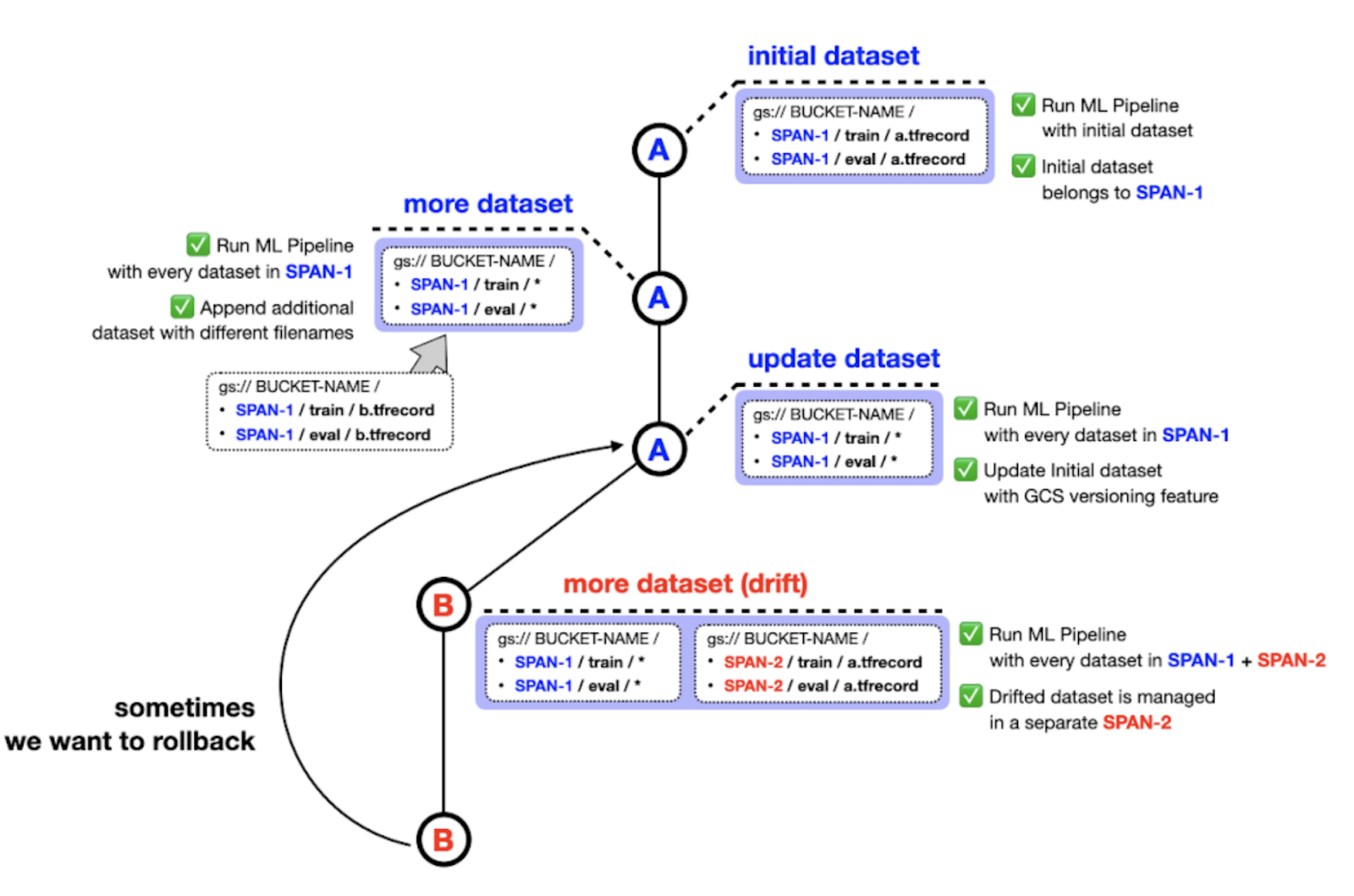 |
| 图 2. 如何管理数据集 (原始) |
批处理评估管道不利用任何标准 TFX 组件。相反,它由五个自定义 TFX 组件组成,分别是 FileListGen、BatchPredictionGen、PerformanceEvaluator、SpanPreparator 和 PipelineTrigger。这些组件可以作为独立模块使用 这里。
 |
| 图 3. 批处理评估管道中的自定义 TFX 组件 (原始) |
FileListGen 生成一个文本文件,由当前部署在 Vertex AI 上的模型查找,以根据 Vertex Prediction 所需的格式 执行批处理预测。然后,BatchPredictionGen 将根据 FileListGen 准备的文本文件简单地执行 Vertex Prediction,并输出一组包含批处理预测结果的文件。PerformanceEvaluator 根据批处理预测结果计算平均准确率,如果低于阈值,则输出 False。如果输出为 True,则管道将终止。或者,如果输出为 False,SpanPreparator 将通过压缩原始数据的列表来准备 TFRecord 文件,然后将这些 TFRecords 放入一个新文件夹中,该文件夹的名称包含连续的跨度编号,例如 span-2。最后,PipelineTrigger 通过 RuntimeParameter 传递应包含在训练模型的数据的跨度编号来触发模型训练管道。
在本节中,我们将逐步介绍项目中的关键组件,并对用于实现它们的工具进行一些说明。
我们专注于概念,并考虑以最小的方式实现它们,以便我们的实现尽可能地可复制和可访问。牢记这一点,我们使用 CIFAR-10 训练集 作为我们的训练数据,并微调 ResNet50 模型以适应数据。我们的训练管道在 此笔记本 中进行了演示。
为了模拟数据漂移场景,我们从互联网上收集了大量与 CIFAR-10 类匹配的图像。为了便于跟踪,我们在 Colab Notebook 中实现了此工作流程,该笔记本可以在 此处 获得。此工作流程还包括将训练后的模型上传和部署为 Vertex AI 平台 上的服务。
然后,我们使用上述步骤中的训练模型对这些图像执行推断。我们执行批处理推断而不是在线推断以获取结果。我们使用 Vertex AI 的批处理预测服务 来实现这一点。在实践中,通常在执行此步骤后,将模型测试图像和模型预测发送给领域专家以进行审核。他们还将在测试图像上提供预期的真实标签。只有在之后,我们才能验证预测结果。但是为了这个项目的目的,我们消除了这个步骤,并假装真实标签已经可用。因此,一旦批处理预测结果可用,我们就会对其进行评估。整个工作流程在 此笔记本 中介绍。
我们部署了一个 Cloud Function 来监控 Google Cloud Storage (GCS) 存储桶中的特定位置。如果该位置中有足够数量的新测试图像可用,我们将触发批处理预测管道。我们将在 此笔记本 中介绍此工作流程。这就是我们实现项目“持续评估”方面的方式。
然而,还有其他方法可以捕获数据中的漂移。例如,使用 JS-Divergence,我们可以比较新可用数据和训练数据之间的分布。你可以按照 Robert Crowe 的 Coursera 课程,该课程深入探讨了这些技术。
在评估批处理预测后,下一步是确定是否需要根据预定义的性能阈值对模型进行重新训练,该阈值通常取决于业务环境和许多其他因素。我们在项目中将此阈值设置为 0.9。如果我们需要重新训练,那么我们将触发相同的模型训练管道(如 此笔记本 中所示),但将新可用数据添加到 CIFAR-10 训练集中。我们可以从之前的检查点热启动我们的模型,或者我们可以使用所有可用训练数据从头开始训练模型。对于这个项目,我们选择后者。
在下一节中,我们将回顾我们实施中的几个非平凡组件,并讨论它们的动机和技术细节。提醒一下,我们的实施是完全开源的 此处。
在本节中,我们将逐步介绍项目中一些关键方面的实施细节。请查看 项目存储库 并查看所有笔记本以获取更多信息。
初始 CIFAR-10 数据集分别存储在 {bucket-name}/span-1/train 和 {bucket-name}/span-1/test GCS 位置。此步骤通过 第一个笔记本 完成。然后,我们使用 Bing Image Downloader 下载更多与 CIFAR-10 类别相同的图像。这些图像被调整为 32x32 大小以使其与 CIFAR-10 数据集兼容,并将它们存储在另一个 GCS 存储桶中,例如 {bucket-batch-prediction}/2021-10/。
请注意,我们使用 YYYY-MM 作为存储图像的名称。这是因为由 Cloud Scheduler 触发的 Cloud Function 将查找最新的 GCS 位置以启动批处理评估管道,如下所示。
def get_latest_directory(storage_client, bucket):
blobs = storage_client.list_blobs(bucket)
folders = list(
set(
[
os.path.dirname(blob.name)
for blob in blobs
if bool(
re.match(
"[1-9][0-9][0-9][0-9]-[0-1][0-9]", os.path.dirname(blob.name)
)
)
is True
]
)
)
folders.sort(key=lambda date: datetime.strptime(date, "%Y-%m"))
return folders[0]
如你所见,它只查找与 YYYY-MM 格式完全匹配的 GCS 位置。Cloud Function 通过 RuntimeParameter 传递要查找以进行批处理预测的 GCS 位置来启动批处理评估管道。以下代码片段显示了它如何在 Cloud Function 端使用名称 data_gcs_prefix 传递到管道。
from kfp.v2.google.client import AIPlatformClient
api_client = AIPlatformClient(project_id=project, region=region)
response = api_client.create_run_from_job_spec(
...
parameter_values={"data_gcs_prefix": latest_directory},
)管道识别data_gcs_prefix是一种RuntimeParameter类型,它在FileListGen组件中使用,该组件准备了一个所需格式的文本文件,以执行 Vertex AI 批量预测。
def _create_pipeline(
data_gcs_prefix: data_types.RuntimeParameter,
...
) -> Pipeline:
filelist_gen = FileListGen(
...
gcs_source_bucket=data_gcs_bucket,
gcs_source_prefix=data_gcs_prefix,
).with_id("filelist_gen")
....让我们跳过由BatchPredictionGen组件执行的批量预测。
当PerformanceEvaluator组件根据BatchPredictionGen组件的结果确定应执行重新训练时,SpanPreparator会准备一个包含新收集图像的 TFRecord 文件,将其移至{bucket-name}/span-1/train和{bucket-name}/span-2/test(训练管道从那里提取数据进行模型训练),并将新收集图像所在的 GCS 位置重命名为{bucket-batch-prediction}/YYYY-MM_old/。
我们添加_old后缀,以便 Cloud Function 忽略重命名的 GCS 位置。如果重新训练的模型没有显示出足够好的性能指标,那么您有机会收集更多数据并将其与_old GCS 位置中的图像合并。
批量评估管道末尾的PipelineTrigger组件将通过传递要查找的跨度编号来触发训练管道以进行模型训练。数据将由 ImportExampleGen 根据 glob 模式匹配功能进行消费。例如,如果应使用跨度 1 和跨度 2 的数据进行模型训练,那么训练数据集的 glob 模式可能为span-[12]/train/*.tfrecord。下面的代码片段清楚地展示了该概念的通用版本。
response = api_client.create_run_from_job_spec(
...
parameter_values={
"input-config": json.dumps(
{
"splits": [
{
"name": "train",
"pattern": f"span-[{int(latest_span)-1}{latest_span}]/train/*.tfrecord",
},
{
"name": "val",
"pattern": f"span-[{int(latest_span)-1}{latest_span}]/test/*.tfrecord",
},
]
}
),
"output-config": json.dumps({}),
},
)我们在parameter_values中以这种方式形成RuntimeParameter的原因是,ImportExampleGen组件的模式匹配功能应在input-config和output-config参数中指定。我们的目的不需要output-config参数,但在将input-config参数作为RuntimeParameter传递时需要它。这就是output-config参数为空的原因。请注意,在将RuntimeParameter用于标准 TFX 组件时,必须以协议缓冲区格式形成参数。下面的代码展示了ImportExampleGen组件如何使用传递的input-config和output-config。
example_gen = tfx.components.ImportExampleGen(
input_base=data_root, input_config=input_config, output_config=output_config
)值得注意的是,如果后端环境是 Kubeflow Pipeline v1,您可以利用 TFX 与标准组件支持的滚动窗口功能。下面的代码片段展示了如何使用CsvExampleGen组件和Resolver节点来实现这一点。
examplegen_range_config = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=2, end_span_number=2))
example_gen = tfx.components.CsvExampleGen(
input_base=data_root,
input_config=examplegen_input_config,
range_config=examplegen_range_config)
resolver_range_config = proto.RangeConfig(
rolling_range=proto.RollingRange(num_spans=2))
examples_resolver = tfx.dsl.Resolver(
strategy_class=tfx.dsl.experimental.SpanRangeStrategy,
config={
'range_config': resolver_range_config
},
examples=tfx.dsl.Channel(
type=tfx.types.standard_artifacts.Examples,
producer_component_id=example_gen.id)).with_id('span_resolver')这是一种更好的方法,因为它会重复使用先前ExampleGens生成的工件,而当前的管道运行只关心新跨度中的数据。不幸的是,基于 Kubeflow Pipeline v2 的 Vertex AI Pipeline 不支持此功能。我们与 TFX 团队就此进行了广泛的讨论,这就是我们想出与标准方法不同的方法的原因。
Vertex AI 训练是 Pipeline 的一项独立服务。我们需要分别为 Vertex AI Pipeline 付费,截至撰写本文时,每项管道运行的费用约为 0.03 美元。每个 TFX 组件的计算实例类型为e2-standard-4,每小时费用约为 0.134 美元。由于整个管道完成不到一个小时,我们可以估计 Vertex AI Pipeline 运行的总成本约为 0.164 美元。
自定义模型训练的成本取决于机器类型和小时数。此外,您还必须考虑您需要分别为服务器和加速器付费。对于这个项目,我们选择了n1-standard-4机器类型,其价格为每小时 0.19 美元,并选择了NVIDIA_TESLA_K80加速器类型,其价格为每小时 0.45 美元。每个模型的训练都在不到一个小时内完成,因此总成本约为 1.28 美元。因此,根据我们的估计,发生的成本的上限不应超过 5 美元。
成本仅来自 Vertex AI,因为其他组件(如 Pub/Sub、Cloud Functions 等)的使用量非常少。因此,即使我们对这些成本进行小幅估算,该项目的总成本上限也不应超过 5 美元。请参考有关价格的官方文档:Vertex AI 价格参考,Cloud Build 价格参考.
无论如何,您应该使用此GCP 价格计算器来更好地了解 GCP 服务的成本可能会有所不同。
在这篇博文中,我们提到了机器学习系统持续评估和重新训练的想法以及实现它们的工具。还有一种更传统的 CI/CD 形式,用于针对代码更改(包括超参数、模型架构等更改)的 ML 系统。我们有一个单独的项目展示了该用例。我们鼓励您在此处查看它们:第一部分和第二部分.
我们感谢ML-GDE 计划提供 GCP 积分以支持我们的实验。我们衷心感谢 Google 的 Robert Crowe 和 Jiayi Zhao 帮助审查。
2021 年 12 月 1 日 — 由 Chansung Park、Sayak Paul(ML-GDE)撰写 持续集成和交付 (CI/CD) 是 DevOps 领域中备受追捧的话题。在 MLOps(机器学习 + 操作)领域,我们还有另一种持续性——持续评估和重新训练。MLOps 系统会根据世界变化而发展,而这通常是由数据/概念漂移造成的。因此,为了满足……






{kind=link}
{kind=link}
{kind=link}