九月,我们开源了 TensorFlow 推荐系统,这是一个简化构建最先进推荐系统模型的库。今天,我们很高兴地宣布 TensorFlow 推荐系统 (TFRS) 的新版本 v0.3.0。
新版本提供了两个重要功能,这两个功能对于构建和部署高质量的可扩展推荐模型至关重要。
第一项内置支持快速、可扩展的近似检索。通过利用 ScaNN,TFRS 现在可以构建深度学习推荐模型,该模型可在毫秒内从数百万候选对象中检索最佳候选对象 - 同时保留部署单个“输入查询特征,输出推荐”SavedModel 对象的简单性。
第二项支持用于建模特征交互的更好技术。TFRS 新版本包括 深度和交叉网络 的实现:用于学习深度学习推荐模型中使用的所有不同特征之间交互的有效架构。
如果您渴望尝试新功能,则可以立即进入我们的 高效检索 和 特征交互建模 教程。否则,继续阅读以了解更多信息!
许多推荐系统的目标是从数百万甚至数千万的候选对象池中检索出一些不错的推荐。推荐系统的检索阶段解决了“大海捞针”问题,即从整个候选对象列表中找到一个有希望的候选对象列表。
如我们在 前一篇博文中 所讨论的,TensorFlow Recommenders 可轻松构建 两塔检索模型。此类模型分两步执行检索
第一步的成本在很大程度上取决于查询塔模型的复杂程度。例如,如果用户输入是文本,则使用 8 层 Transformer 的查询塔计算成本将大约是使用 4 层 Transformer 的计算成本的两倍。诸如 稀疏性、量化 和 架构优化 之类技术都有助于降低此成本。
然而,对于数百万候选对象的大型数据库,第二步对于快速推理通常更为重要。我们的两塔模型使用用户输入和候选对象嵌入的点积来计算候选对象相关性,而且尽管计算点积相对便宜,但对数据库中的每个嵌入计算一个点积(其规模与数据库大小成线性关系)很快就会在计算上变得不可行。快速的 近邻搜索 (NNS) 算法因此对于推荐系统性能至关重要。
输入 ScaNN。ScaNN 是 Google Research 的最先进 NNS 库。它在 标准基准测试 中显著优于其他 NNS 库。此外,它与 TensorFlow Recommenders 无缝集成。如下所示,ScaNN Keras 层 作为蛮力检索的无缝替代品
# Create a model that takes in raw query features, and
# recommends movies out of the entire movies dataset.
# Before
# index = tfrs.layers.factorized_top_k.BruteForce(model.user_model)
# index.index(movies.batch(100).map(model.movie_model), movies)
# After
scann = tfrs.layers.factorized_top_k.ScaNN(model.user_model)
scann.index(movies.batch(100).map(model.movie_model), movies)
# Get recommendations.
# Before
# _, titles = index(tf.constant(["42"]))
# After
_, titles = scann(tf.constant(["42"]))
print(f"Recommendations for user 42: {titles[0, :3]}")由于它是一个 Keras 层,因此 ScaNN 索引序列化并自动与 TensorFlow 推荐模型的其余部分保持同步。此外,由于一切都已正确连接好,因此无需在模型和 ScaNN 之间反复发送请求。随着 NNS 算法的改进,ScaNN 的效率只会提高,并进一步提高检索准确性和延迟。
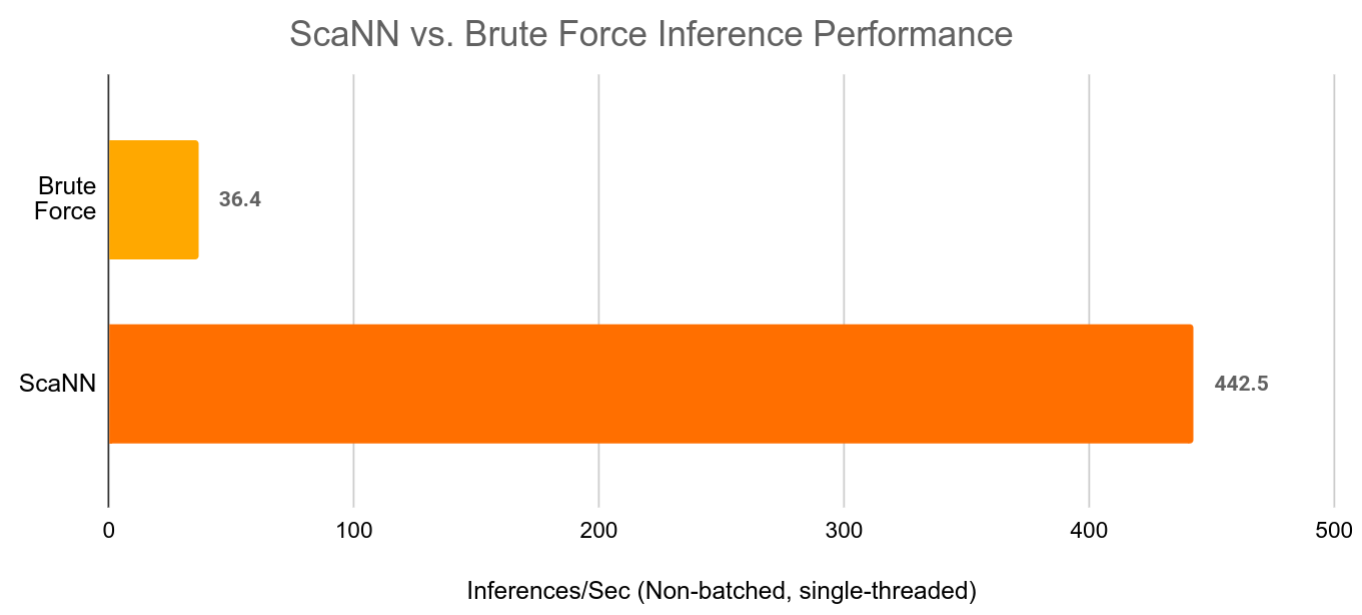 |
| ScaNN 可以加速大型检索模型超过 10 倍,同时仍提供几乎与蛮力向量检索相同的检索精度。 |
我们相信 ScaNN 的功能将导致部署最先进的深度检索模型的便捷性发生变革性的飞跃。如果您对如何构建和部署基于 ScaNN 的模型的详细信息感兴趣,请查看我们的 教程。
有效的特征交叉是许多预测模型成功的关键。假设我们正在构建一个推荐系统来使用用户的过去购买历史记录销售搅拌器。诸如购买的香蕉和食谱的数量等各个特征为我们提供了一些有关用户意图的信息,但正是它们的组合——既购买了香蕉又购买了食谱——为我们提供了用户购买搅拌器的可能性最强的信号。这种特征组合称为特征交叉。

在网络规模的应用程序中,数据大部分是分类的,导致特征空间庞大和稀疏。在这种情况下识别有效的特征交叉通常需要手动特征工程或穷举搜索。传统的馈送前向多层感知器 (MLP) 模型是通用的函数逼近器;然而,正如 深度和交叉网络 和 Latent Cross 论文指出的那样,它们甚至无法有效逼近 2 阶或 3 阶特征交叉。
DCN 旨在更有效地学习显式且有界度的交叉特征。它们从输入层(通常是一个嵌入层)开始,然后是一个建模显式特征交互的交叉网络,最后是一个建模隐式特征交互的深度网络。
这是 DCN 的核心。它在每一层显式应用特征交叉,并且最高的多项式次数(特征交叉阶数)随着层级深度而增加。下图显示了第 (i+1) 个交叉层。
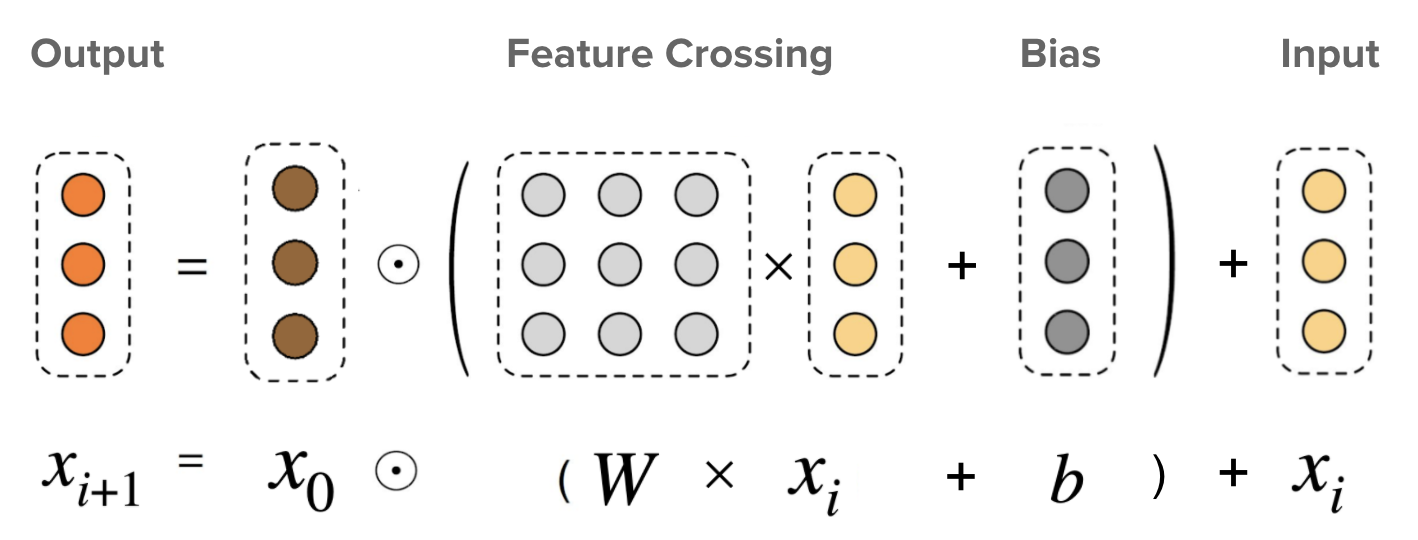 |
| 交叉层可视化。x0 是基础层(通常设置为嵌入层),xi 是交叉层的输入,☉ 表示逐元素乘法,矩阵 W 和向量 b 是要学习的参数。 |
当我们只有单跨层时,它会创建输入要素中的 2 阶(成对)要素交叉。在上述搅拌器示例中,跨层的输入将是连接三个要素的向量:[国家、购买香蕉、购买菜谱书]。然后,输出的第一维将包含国家与所有三个输入要素之间成对交互的加权和;第二维将包含购买香蕉和所有其他要素的加权交互,等等。
这些交互项的权重形成矩阵 W:如果一个交互不重要,其权重就会接近于零。如果它很重要,它将远离零。
为了创建高阶要素交叉,我们可以堆叠更多跨层。例如,我们现在知道单个跨层输出 2 阶要素交叉,例如购买香蕉与购买菜谱书之间的交互。我们可以进一步将这些 2 阶交叉提供给另一个跨层。然后,要素交叉部分将这些 2 阶交叉与原始(1 阶)要素相乘,以创建 3 阶要素交叉,例如国家、购买香蕉和购买菜谱书之间的交互。残差连接将延续在前一层中已经创建的那些要素交叉。
如果我们一起堆叠 k 跨层,那么 k 层交叉网络将创建所有高达阶数 k+1 的要素交叉,它们的权重由权重矩阵和偏置向量中的参数表征。
深度与交叉网络的深度部分是传统的前馈多层感知器 (MLP)。
然后,深度网络和交叉网络组合起来形成 DCN。通常,我们可以在交叉网络顶部堆叠一个深度网络(堆叠结构);我们也可以将它们并行放置(并行结构)。
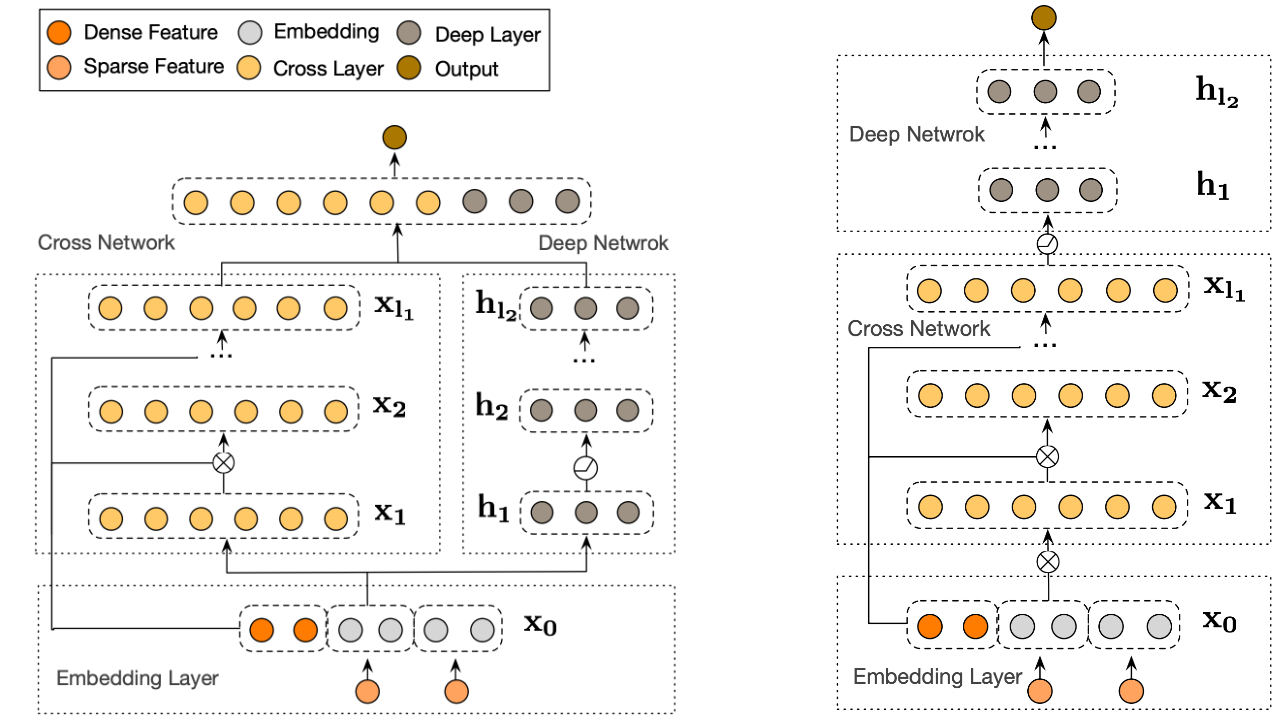 |
| 深度与交叉网络 (DCN) 可视化。左图:并行结构;右图:堆叠结构。 |
很好地理解学习到的要素交叉有助于提高模型可理解性。幸运的是,交叉层中的权重矩阵 W 揭示了模型学到的哪些要素交叉非常重要。
以向客户销售搅拌机为例。如果同时购买香蕉和菜谱书是数据中最具预测性的信号,那么 DCN 模型应该能够捕获这种关系。下图显示了在合成的训练数据(其中联合购买要素最重要)上一层交叉层 DCN 模型学习的矩阵。我们看到模型本身已经学会了交互`purchased_bananas`和`purchased_cookbooks`很重要,没有任何手动要素工程应用。
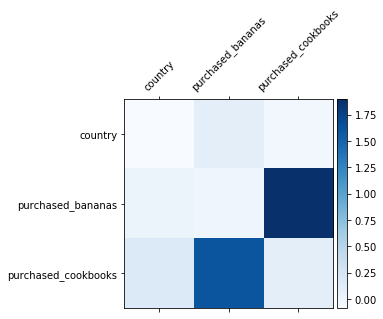 |
| 在交叉层中学习权重矩阵。 |
跨层现在已在 TensorFlow Recommenders 中实现,您可以轻松地将其作为模型中的构建模块。要了解如何操作,请查看我们的教程,了解示例用法和实践课程。如果您有兴趣了解更多详细信息,请查看我们的研究论文DCN和DCN v2。
我们要特别感谢 Derek Zhiyuan Cheng、Sagar Jain、Shirley Zhe Chen、Dong Lin、Lichan Hong、Ed H. Chi、Bin Fu、Gang (Thomas) Fu 和 Mingliang Wang 对深度与交叉网络 (DCN) 的重要贡献。我们还要感谢从研究构想至产品化的 DCN 工作的每一个帮助和支持过我们的人:Shawn Andrews、Sugato Basu、Jakob Bauer、Nick Bridle、Gianni Campion、Jilin Chen、Ting Chen、James Chen、Tianshuo Deng、Evan Ettinger、Eu-Jin Goh、Vidur Goyal、Julian Grady、Gary Holt、Samuel Ieong、Asif Islam、Tom Jablin、Jarrod Kahn、Duo Li、Yang Li、Albert Liang、Wenjing Ma、Aniruddh Nath、Todd Phillips、Ardian Poernomo、Kevin Regan、Olcay Sertel、Anusha Sriraman、Myles Sussman、Zhenyu Tan、Jiaxi Tang、Yayang Tian、Jason Trader、Tatiana Veremeenko、Jingjing Wang、Li Wei、Cliff Young、Shuying Zhang、Jie (Jerry) Zhang、Jinyin Zhang、Zhe Zhao 和其他许多人(按字母顺序排列)。我们还要感谢 David Simcha、Erik Lindgren、Felix Chern、Nathan Cordeiro、Ruiqi Guo、Sanjiv Kumar、Sebastian Claici 和 Zonglin Li 对 ScaNN 的贡献。

2020 年 11 月 30 日 — Ruoxi Wang、Phil Sun、Rakesh Shivanna 和 Maciej Kula(Google)发布
在 9 月份,我们开源了 TensorFlow Recommenders,这是一个有助于轻松构建最先进的推荐系统模型的库。今天,我们很高兴宣布 TensorFlow Recommenders (TFRS) 将发布新版本 v0.3.0。新版本带来两个重要功能,这两者对于构建和部署高质量的…





