Google Research 软件工程师 Summer Misherghi 和 Thomas Greenspan 发布
去年 12 月,我们开源了 公平性指标,这是一个允许对机器学习模型性能进行分片评估的平台。这种负责任的评估是避免偏差的关键第一步,因为它允许我们确定我们的模型对各种用户如何运作。当我们确实发现我们的模型在数据的某些分片上表现不佳时,我们需要一个策略来减轻这种情况,以避免创建或强化不公平的偏见,符合 Google 的 AI 原则.
今天,我们宣布了 MinDiff,这是一种解决机器学习模型中不公平偏差的技术。给定两组数据,MinDiff 通过对两组之间分数分布的差异进行惩罚来运作。随着模型的训练,它将尝试通过使分布更接近来最小化惩罚。MinDiff 是最终将成为更大模型修复库的第一项技术,每种技术都适合不同的用例。要了解 MinDiff 背后的研究和理论,请参阅 我们在 Google AI 博客上的文章.
MinDiff 演练
您可以在此 MinDiff 笔记本 中亲自运行代码并跟踪代码。在本演练中,我们将强调笔记本中的重要点,同时提供有关公平性评估和修复的上下文。
在此示例中,我们正在训练一个文本分类器来识别可能被认为“有毒”的书面内容。对于此任务,我们的基准模型将是在 文明评论数据集 上预先训练的简单 Keras 顺序模型。由于此文本分类器可用于自动审核互联网上的论坛(例如,标记潜在的有毒评论),我们希望确保它对所有人都有效。您可以在 这篇博文 中阅读有关自动化内容审核中如何出现公平性问题的更多信息。
为了尝试减轻潜在的公平性问题,我们将
我们的目的是用最小的工作流程向您演示 MinDiff 技术的使用,而不是阐述机器学习中公平性的完整方法。我们的评估将只关注一个敏感类别和一个指标。我们也没有解决数据集中的潜在缺陷,也没有调整我们的配置。
在生产环境中,您需要更加严格地处理每个问题。例如
出于这篇博文的目的,我们将跳过构建和训练我们的基准模型,直接跳到评估它的性能。我们使用了一些实用函数来计算我们的指标,我们已准备好可视化评估结果(请参阅笔记本中的“渲染评估结果”)。
widget_view.render_fairness_indicator(eval_result) 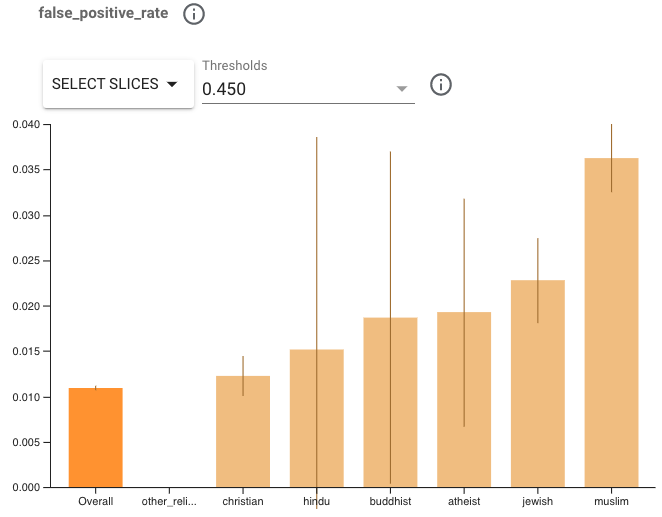
让我们看看评估结果。尝试选择阈值为 0.450 的指标假阳性率 (FPR)。我们可以看到,该模型在某些宗教群体上的表现不如其他群体,显示出更高的 FPR。请注意某些群体上的置信区间很宽,因为它们的示例太少。这使得很难确定地说这些分片之间的性能存在显著差异。我们可能希望收集更多示例来解决这个问题。但是,我们可以尝试对我们确信表现不佳的两个群体应用 MinDiff。
我们选择重点关注 FPR,因为更高的 FPR 意味着引用这些身份群体的评论更有可能被错误地标记为有毒。这可能导致在与宗教相关的对话中与用户进行不平等的互动,但请注意,其他指标的差异会导致其他类型的伤害。
现在,我们将尝试改善模型在表现不佳的宗教群体上的 FPR。我们将尝试使用 MinDiff 来做到这一点,这是一种修复技术,它试图通过在训练期间对性能差异进行惩罚来平衡数据的不同分片上的错误率。当我们应用 MinDiff 时,模型在其他分片上的性能可能会略有下降。因此,我们在 MinDiff 中的目标是改善表现不佳的群体的性能,同时保持其他群体和整体的良好性能。
为了使用 MinDiff,我们创建了两个额外的拆分数据
拥有足够多的属于表现不佳的类的示例非常重要。根据您的模型架构、数据分布和 MinDiff 配置,所需的数据量可能会有很大差异。在过去的应用中,我们发现 MinDiff 在每个数据拆分中至少有 5,000 个示例的情况下效果良好。
在我们的案例中,少数群体拆分中的群体拥有 9,688 和 3,906 个示例。请注意数据集中类别的不平衡;实际上,这可能会引起担忧,但我们不会在这个笔记本中试图解决它们,因为我们的意图只是演示 MinDiff。
我们只为这些群体选择负面示例,以便 MinDiff 能够优化将这些示例正确分类。如果我们主要关注的是假阳性率的差异,那么剔除一组真实负面示例似乎违反直觉,但请记住,假阳性预测是指被错误地分类为正的真实负面示例,这是我们试图解决的问题。
为了准备我们的数据拆分,我们为敏感和非敏感群体创建了掩码
minority_mask = data_train.religion.apply(
lambda x: any(religion in x for religion in ('jewish', 'muslim')))
majority_mask = data_train.religion.apply(
lambda x: x == "['christian']") 接下来,我们选择负面示例,以便 MinDiff 能够降低敏感群体的 FPR
true_negative_mask = data_train['toxicity'] == 0
data_train_main = copy.copy(data_train)
data_train_sensitive = (
data_train[minority_mask & true_negative_mask])
data_train_nonsensitive = (
data_train[majority_mask & true_negative_mask])要开始使用 MinDiff 进行训练,我们需要将我们的数据转换为 TensorFlow 数据集(此处未显示 - 有关详细信息,请参阅笔记本中的“创建 MinDiff 数据集”)。不要忘记对您的训练数据进行批处理。在我们的案例中,我们将批处理大小设置为与原始数据集相同的值,但这并不是必需的,实际上应该进行调整。
dataset_train_sensitive = dataset_train_sensitive.batch(BATCH_SIZE)
dataset_train_nonsensitive = (
dataset_train_nonsensitive.batch(BATCH_SIZE))
准备完三个数据集后,我们使用 库中提供的实用函数 将它们合并到一个 MinDiff 数据集中。
min_diff_dataset = md.keras.utils.pack_min_diff_data(
dataset_train_main,
dataset_train_sensitive,
dataset_train_nonsensitive) 要使用 MinDiff 进行训练,只需将原始模型包装在一个 MinDiffModel 中,并使用相应的 `loss` 和 `loss_weight`。我们使用 1.5 作为默认的 `loss_weight`,但这是一个需要针对您的用例进行调整的参数,因为它取决于您的模型和产品要求。您应该尝试更改该值以查看它如何影响模型,并注意增加它会使少数群体和多数群体的性能更接近,但可能会带来更明显的权衡。
如上所述,我们创建原始模型,并将其包装在一个 MinDiffModel 中。我们传入一个 MinDiff 损失,并使用 1.5 的中等高权重。
original_model = ... # Same structure as used for baseline model.
min_diff_loss = md.losses.MMDLoss()
min_diff_weight = 1.5
min_diff_model = md.keras.MinDiffModel(
original_model, min_diff_loss, min_diff_weight) 在包装完原始模型后,我们像往常一样编译模型。这意味着使用与基准模型相同的损失
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss = tf.keras.losses.BinaryCrossentropy()
min_diff_model.compile(
optimizer=optimizer, loss=loss, metrics=['accuracy']) 我们将模型拟合到 MinDiff 数据集上进行训练,并将原始模型保存以进行评估(有关我们为什么不保存 MinDiff 模型的详细信息,请参阅 API 文档)。
min_diff_model.fit(min_diff_dataset, epochs=20)
min_diff_model.save_original_model(
min_diff_model_location, save_format='tf') 最后,我们评估新结果。
min_diff_eval_subdir = 'eval_results_min_diff'
min_diff_eval_result = util.get_eval_results(
min_diff_model_location, base_dir, min_diff_eval_subdir,
validate_tfrecord_file, slice_selection='religion') 为了确保我们正确地评估新模型,我们需要以与评估基准模型相同的方式选择阈值。在生产环境中,这意味着确保评估指标符合发布标准。在我们的案例中,我们将选择导致总体 FPR 与基准模型类似的阈值。此阈值可能与您为基准模型选择的阈值不同。尝试选择阈值为 0.400 的假阳性率。(请注意,示例数量非常少的子组具有非常宽的置信区间范围,结果不可预测。)
widget_view.render_fairness_indicator(min_diff_eval_result) 
注意:y 轴的刻度已从基准模型图中的 .04 更改为 MinDiff 模型中的 .02
回顾这些结果,您可能会注意到我们目标群体的 FPR 已经改善。我们表现最差的群体和多数群体之间的差距已从 .024 改善至 .006。鉴于我们观察到的改进以及多数群体持续的良好性能,我们已经实现了我们的两个目标。根据产品,可能需要进一步改进,但这项方法使我们的模型更接近于为所有用户公平地执行。
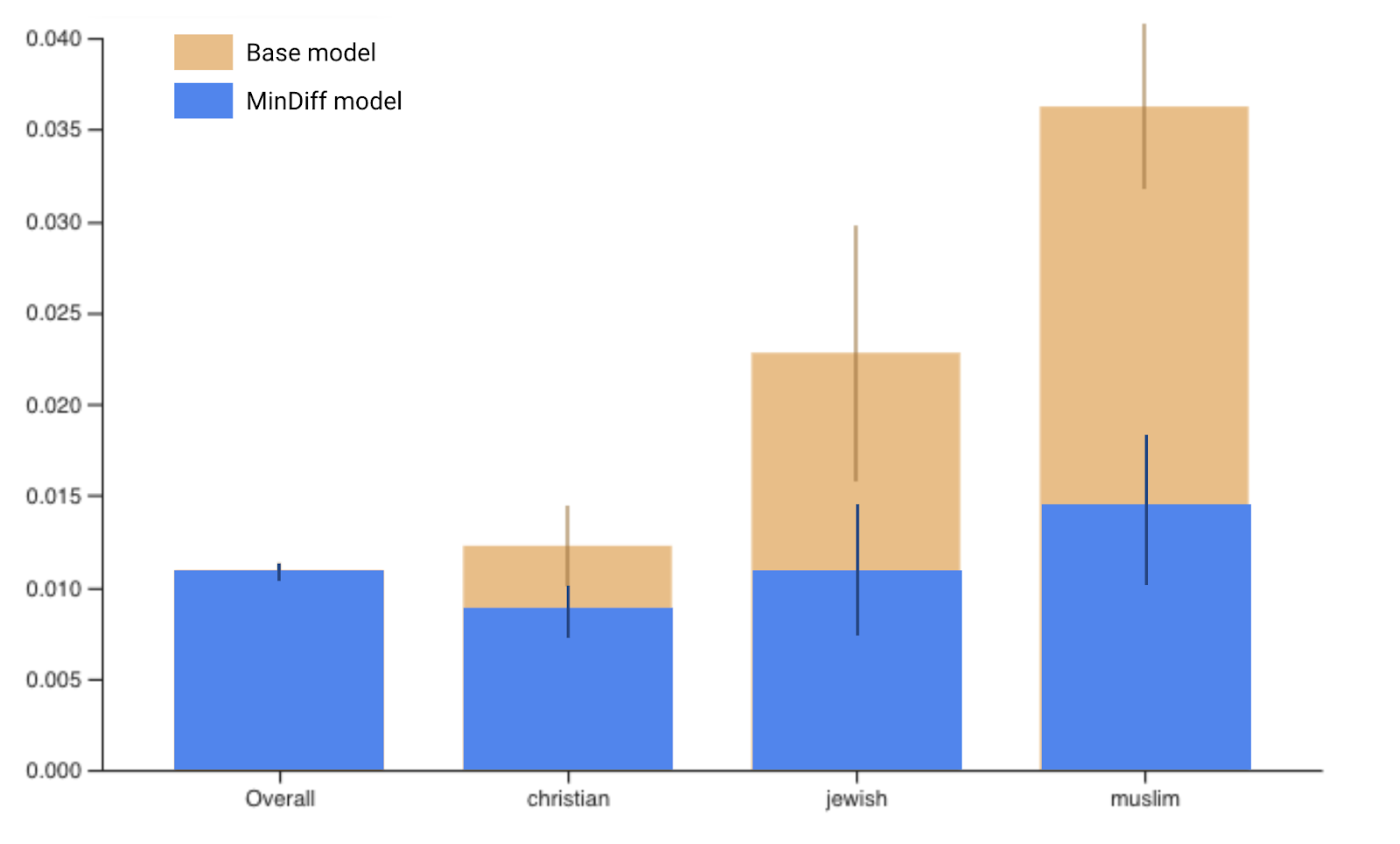
为了更好地理解规模,我们将 MinDiff 模型叠加在基础模型之上。
您可以访问 MinDiff 页面 在 tensorflow.org 上开始使用 MinDiff。有关 MinDiff 背后研究的更多信息,请参见 我们在 Google AI 博客上的文章。您还可以通过 本指南 了解有关公平性评估的更多信息。
鸣谢
MinDiff 框架是与 Thomas Greenspan、Summer Misherghi、Sean O'Keefe、Christina Greer、Catherina Xu、Manasi Joshi、Dan Nanas、Nick Blumm、Jilin Chen、Zhe Zhao、James Chen、Maciej Kula、Lichan Hong、Mahesh Sathiamoorthy 和 Meg Mitchell 合作开发的。这项关于分类中 ML 公平性的研究工作由(按字母顺序)Alex Beutel、Ed H. Chi、Flavien Prost、Hai Qian、Jilin Chen、Shuo Chen 和 Tulsee Doshi 共同领导。此外,这项工作是在与 Cristos Goodrow、Christine Luu、Jonathan Bischof、Pierre Kreitmann 和 Qiuwen Chen 合作中进行的。

2020 年 11 月 16 日 — 由 Google Research 软件工程师 Summer Misherghi 和 Thomas Greenspan 发布 去年 12 月,我们开源了 公平性指标,这是一个支持机器学习模型性能分层评估的平台。这种负责任的评估是避免偏见的关键第一步,因为它使我们能够确定模型如何为各种用户服务。当我们发现……





