https://blog.tensorflowcn.cn/2020/08/introducing-semantic-reactor-explore-nlp-sheets.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhG-602_CZahqVVdo4ONtCzkvmZxISKj5LkWKHhJFLGAdmUf5xXL72sDqEsjlY36CGVPVehroqFwdfbeGIM9cxJj-X9YcwtU3Qi-USK86obGgmWgqbVI2iAwukWn8uIWoKDAFG0YgdvOwM/s1600/semantic_reactor.gif
发布者 Dale Markowitz,应用人工智能工程师
编者注:本文的早期版本版本发布在 Dale 的博客上。
机器学习可能很棘手,因此能够快速制作原型 ML 应用是一个福音。如果您正在构建一个语言驱动的应用程序,例如具有玩家可以与之交谈的角色的视频游戏或客户服务机器人,那么语义反应器是一个可以帮助您实现这一目标的工具。
语义反应器 是
Google 表格 的一个新插件,它允许您在自己的数据上运行自然语言理解 (NLU) 模型(
通用句子编码器 的变体),直接从电子表格中进行。
在这篇文章中,我将向您展示如何使用该工具及其使用的 NLU 模型,但首先,NLP 究竟是如何工作的?幕后发生了什么?(想要直接跳到工具?滚动到下一节。)
理解嵌入
什么是词嵌入?
构建自然语言驱动的软件的一种简单(但功能强大)的技术是使用“嵌入”。
在机器学习中,嵌入是一种在空间中表示数据的学习方式(即绘制在 n 维网格上的点),使得点之间的距离是有意义的。词向量是一个流行的例子
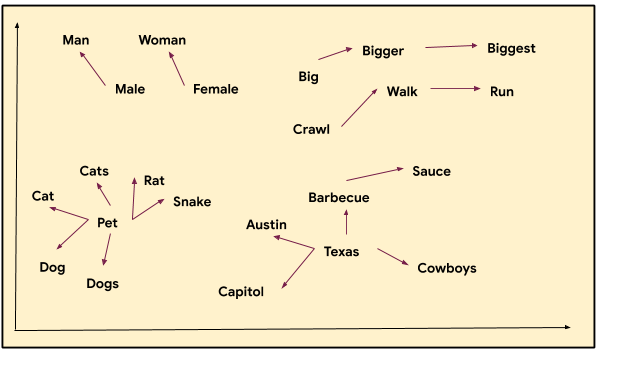
上图粗略地展示了词语如何在彼此更近或更远的地方。请注意,“奥斯汀”、“德克萨斯”和“烧烤”这几个词彼此之间关系密切,就像“宠物”和“狗”以及“行走”和“奔跑”一样。每个词都由一组坐标(或向量)表示,并放置在一个图上,我们可以看到它们之间的关系。例如,我们可以看到,“老鼠”这个词与“宠物”和“猫”都比较接近。
这些数字来自哪里?它们是由机器学习模型通过大量的对话和语言数据学习得到的。通过展示所有这些例子,模型学习了哪些词往往出现在句子中的相同位置。
考虑这两个句子
- “我母亲生了一个儿子。”
- “我母亲生了一个女儿。”
由于“女儿”和“儿子”这两个词经常在类似的上下文中使用,因此模型将学习到它们应该在空间中彼此靠近地表示。词嵌入在自然语言处理中很有用。它们可以用来查找同义词(“语义相似性”)、解决类比问题,或者作为更复杂模型的预处理步骤。您可以使用 TensorFlow
在这里快速训练自己的基本词嵌入。
什么是句子嵌入?
事实证明,使用一种称为
通用句子编码器 的模型,整个句子(甚至简短的段落)也可以有效地嵌入到空间中。使用句子嵌入,我们可以确定两个句子是否相似。例如,如果您正在构建一个聊天机器人,并且想知道用户提出的问题(例如,“你什么时候叫醒我?”)在语义上是否与您(聊天机器人程序员)预料到的并写下过答案的问题(“我的闹钟几点?”)相似。
语义反应器:在 Google 表格中使用 NLP 制作原型
好了,现在进入有趣的部分:构建事物!语义反应器中提供了三个 NLP 模型
- 本地 - 通用句子编码器 的一个小型 TensorFlow.js 版本,可以在网页内完全运行。
- 基本在线 - 通用句子编码器的完整尺寸、通用版本。
- 多语言在线 - 在 16 种语言的问答对上训练的完整尺寸通用句子编码器模型。
每个模型都提供两种排名方法
- 语义相似性:两个文本块有多相似?
非常适合您可以预测用户可能会问什么的问题的应用程序,例如常见问题解答机器人。(许多客户服务机器人使用语义相似性来帮助向用户提供好的答案。)
- 输入/响应:一个文本块对另一个文本块的响应有多好?
当您有一组庞大且不断变化的文本,并且您不知道用户可能会问什么时很有用。例如,与书籍对话,这是一个针对定期更新的 100,000 本书籍集合的语义搜索工具,使用输入/响应。
您可以使用语义反应器来测试响应列表与每个模型和排名方法的匹配程度。有时,您需要进行大量的实验才能找到您认为适用于您的应用程序的响应列表和模型选择。好消息是在 Google 表格中进行这项工作使它变得快速而轻松。
确定响应列表、模型选择和排名方法后,您就可以开始编写代码了,如果您希望将所有操作都保留在网站内或设备上(无需进行在线 API 调用),可以使用最新更新的
TensorFlow.js 模型。
如前所述,NLU 技术有很多很好的用途,并且几乎每天都会出现更多有趣的应用程序。每个数字助理、客户服务机器人和搜索引擎可能都在使用某种机器学习方法。Gmail 中的智能回复和智能撰写是两个充分利用语义技术的常用功能。
但是,在质量要求不高的应用程序中玩弄这项技术既有趣又有帮助,在这些应用程序中,失败是可以接受的,甚至是有趣的。为此,我们使用了语义反应器中的相同技术来创建几个示例游戏。
语义游戏 是一款词语联想游戏,它使用输入-响应排名方法,而
三个机器人的谜团 使用语义相似性。
玩这两个游戏,找出它们在哪里工作以及它们在哪里不工作,可能会让您想到可以创建哪些体验。
 |
| 语义游戏,一款由词嵌入驱动的词语联想游戏。 |
 |
| 三个机器人的谜团 是一款简单的游戏,由 NLU 驱动,并以开源代码的形式提供。(也可以在这里 玩。) |
这项技术的酷炫应用之一来自
Anna Kipnis,她是 Double Fine 的前游戏设计师,现在在 Stadia 工作。她使用语义反应器制作了一个视频游戏世界原型,该世界使用 ML 推断环境应该如何对玩家输入做出反应。请查看我们的对话
这里。
在安娜的游戏中,玩家通过提出任何他们想到的问题来与一只虚拟狐狸互动
然后,使用语义 ML,游戏引擎(或
效用系统)会考虑游戏可能做出响应的所有方式
- “狐狸打开灯。”
- “狐狸打开收音机。”
- “狐狸走向你。”
- “狐狸给你带来马克杯。”
使用句子编码器模型,游戏决定最佳响应是什么并执行它(在本例中,最佳响应是“狐狸给你带来一个马克杯”,因此游戏将狐狸带来马克杯的动作动画化)。如果听起来有点抽象,请务必观看上面链接的视频。
让我们看看如何使用语义反应器构建类似安娜的游戏(有关狐狸演示的所有细节,请查看她的
原始文章)。
首先,创建一个新的 Google 表格,并在第一列中写一些句子。我把这些句子放在我的 Google 表格的第一列中
- 我拿起一个球
- 我走到你身边
- 我玩球
- 我去上学。
- 我去马克杯。
- 我给你带来马克杯。
- 我打开音乐。
- 我小睡一会儿。
- 我去远足。
- 我告诉你一个秘密。
- 我依偎在你身边。
- 我要你挠挠我的肚子。
- 我发短信。
- 我接电话。
- 我做三明治。
- 我喝点水。
- 我玩棋盘游戏。
- 我写代码。
您必须在这里发挥您的想象力,并想出潜在角色(例如聊天机器人或视频游戏中的演员)可能采取的这些“动作”。
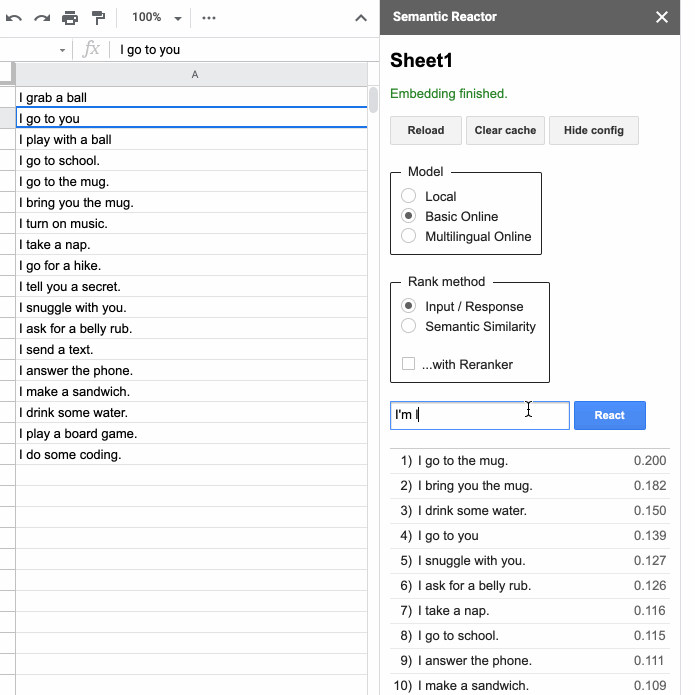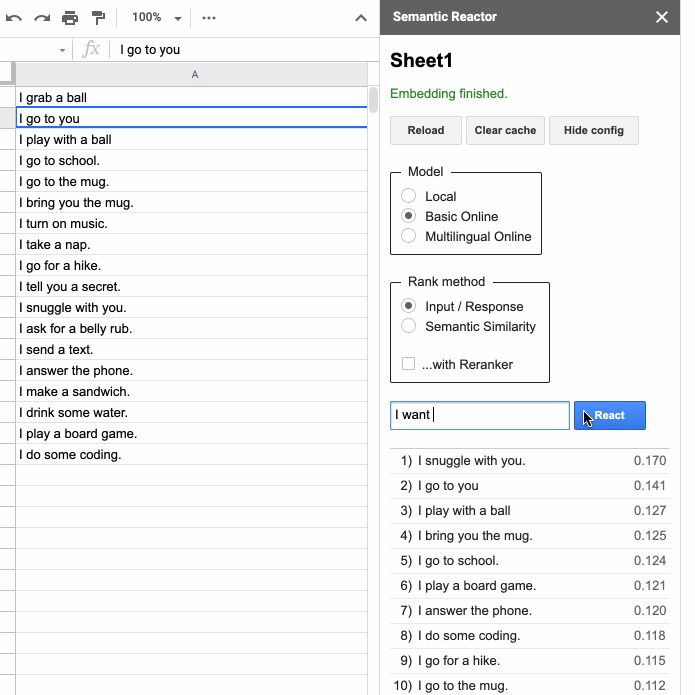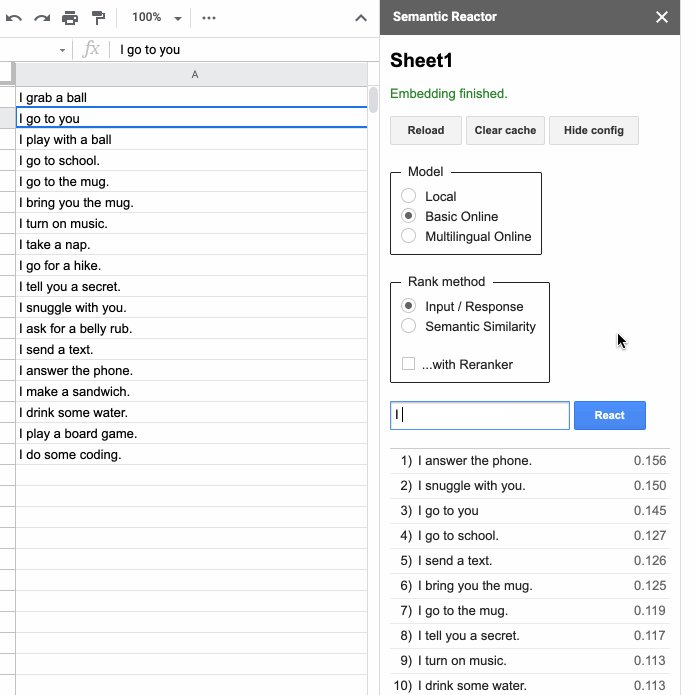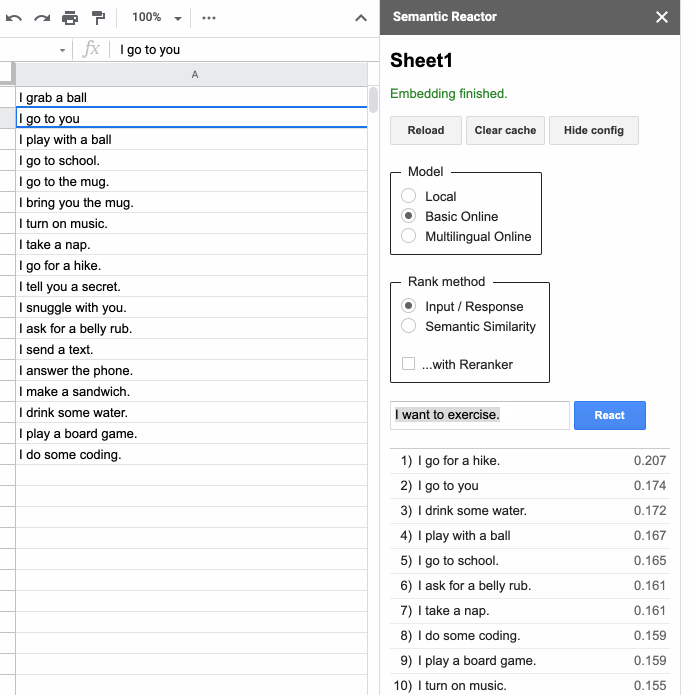
在您申请并获得对语义反应器的访问权限后,您就可以通过点击“附加组件 -> 语义反应器 -> 开始”来启用它。
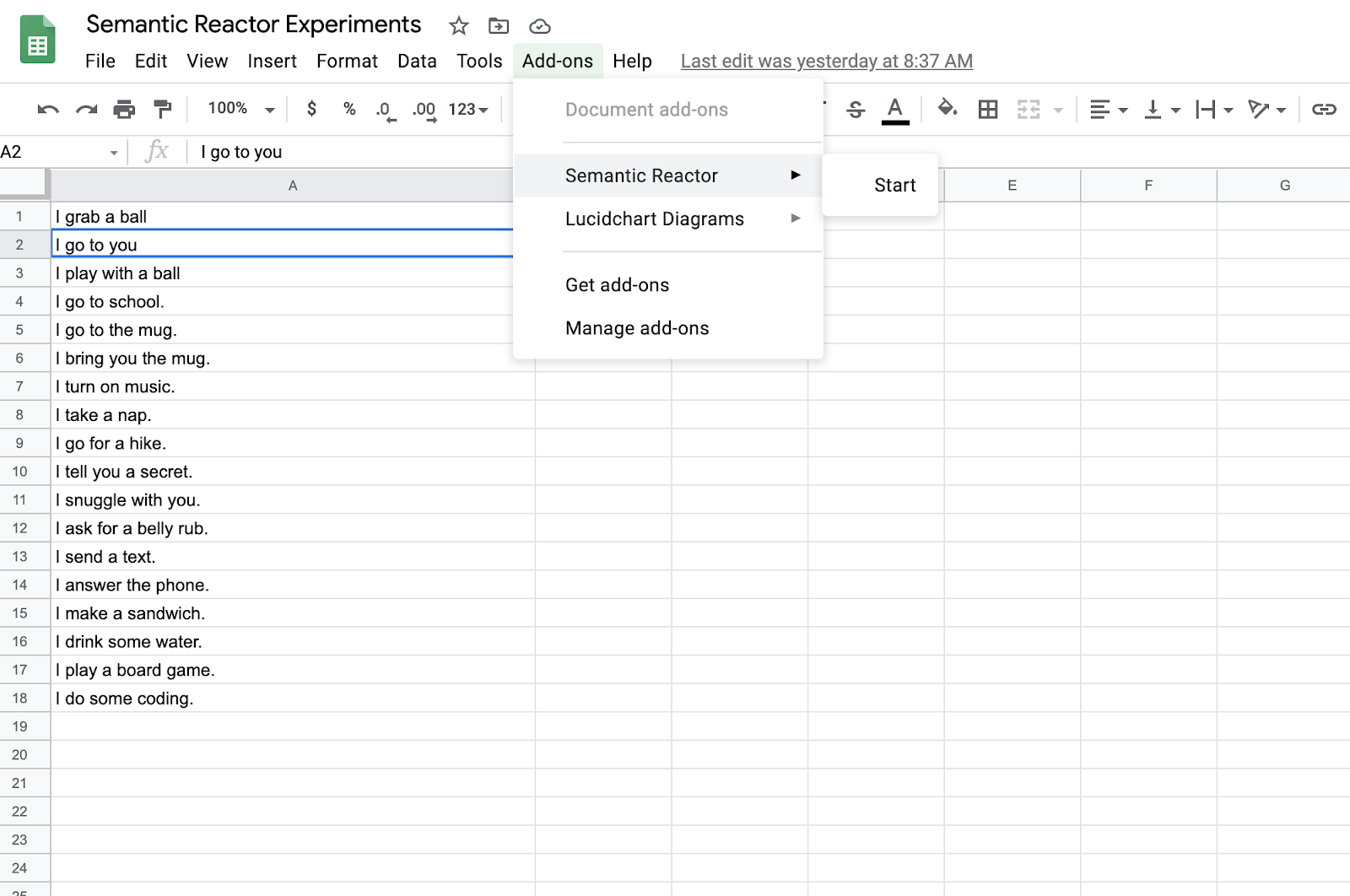
点击“开始”将打开一个面板,允许您在其中输入内容并点击“反应”
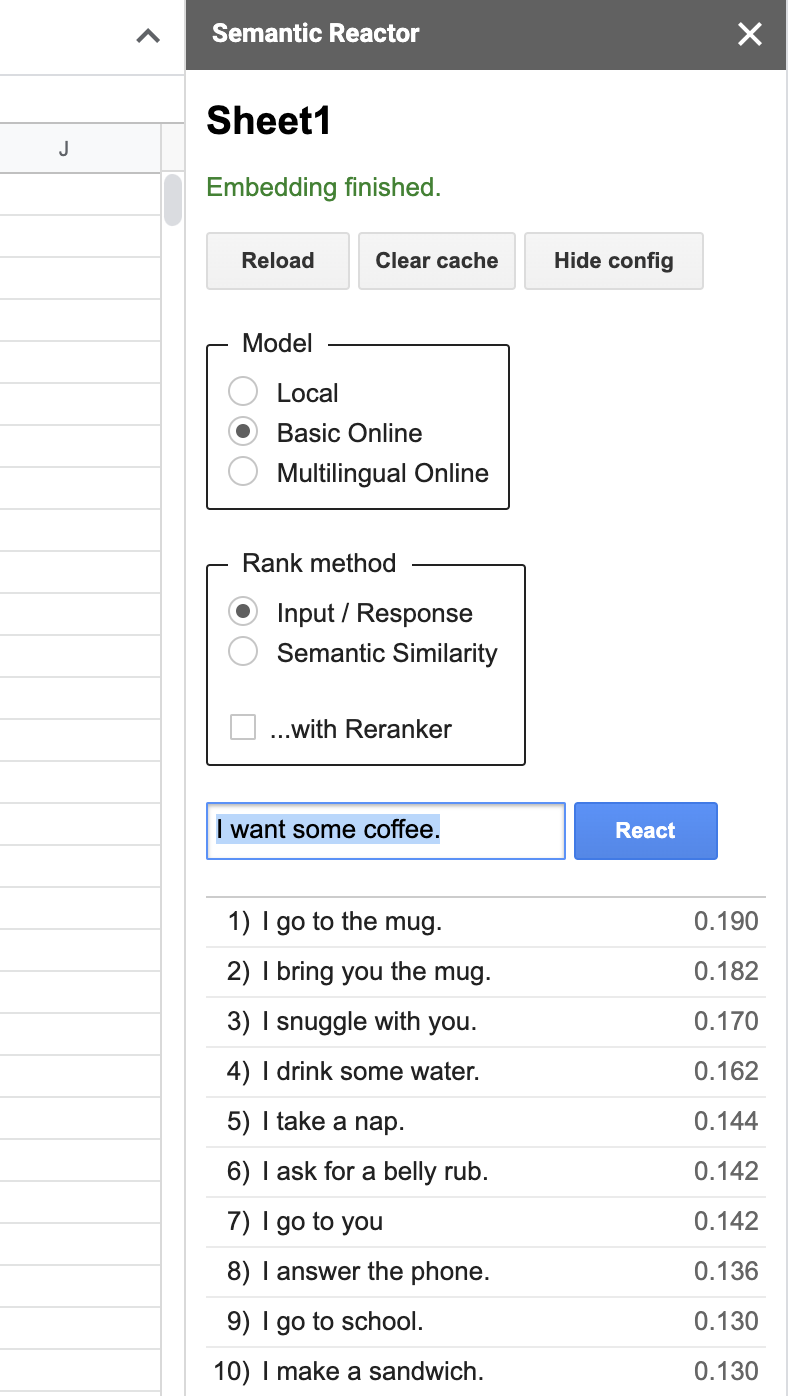
点击“反应”后,语义反应器会使用模型嵌入您在第一列中写入的所有响应,计算一个分数(这个句子对查询的响应有多好?),并对结果进行排序。例如,当我输入“我想要一些咖啡”时,我的电子表格中排名最高的响应是“我去马克杯”和“我给你带来马克杯”。您还会注意到,使用此工具有两种不同的方式对句子进行排名:“输入/响应”和“语义相似性”。顾名思义,前者根据句子作为给定查询的响应的程度对其进行排名,而“语义相似性”只是对句子与查询的相似程度进行评分。
从电子表格到代码,使用 TensorFlow.js
在幕后,语义反应器由在
这里找到的开源 TensorFlow.js 模型驱动。
让我们看看如何在 JavaScript 中使用这些模型,以便您可以将您的电子表格原型转换为可工作的应用程序。
1 - 创建一个新的 Node 项目并安装模块
npm init
npm install @tensorflow/tfjs @tensorflow-models/universal-sentence-encoder
2 - 创建一个新文件(use_demo.js)并引入库
require('@tensorflow/tfjs');
const encoder = require('@tensorflow-models/universal-sentence-encoder');
3 - 加载模型
const model = await encoder.loadQnA();
4 - 编码您的句子和查询
const input = {
queries: \["I want some coffee"\],
responses: \[
"I grab a ball",
"I go to you",
"I play with a ball",
"I go to school.",
"I go to the mug.",
"I bring you the mug."
\]
};
const embeddings = await model.embed(input);
5 - 瞧!您已经将您的响应和查询转换为向量。不幸的是,向量只是空间中的点。为了对响应进行排序,您需要计算这些点之间的距离(您可以通过计算
点积来完成此操作,它会给出点之间的
欧几里得距离的平方)。
//zipWith :: (a -> b -> c) -> \[a\] -> \[b\] -> \[c\]
const zipWith =
(f, xs, ys) => {
const ny = ys.length;
return (xs.length <= ny ? xs : xs.slice(0, ny))
.map((x, i) => f(x, ys\[i\]));
}
// Calculate the dot product of two vector arrays.
const dotProduct = (xs, ys) => {
const sum = xs => xs ? xs.reduce((a, b) => a + b, 0) : undefined;
return xs.length === ys.length ?
sum(zipWith((a, b) => a * b, xs, ys))
: undefined;
}
如果您运行此代码,您应该会看到类似的输出。
[
{ response: 'I grab a ball', score: 10.788130270345432 },
{ response: 'I go to you', score: 11.597091717283469 },
{ response: 'I play with a ball', score: 9.346379028479209 },
{ response: 'I go to school.', score: 10.130473646521292 },
{ response: 'I go to the mug.', score: 12.475453722603106 },
{ response: 'I bring you the mug.', score: 13.229019199245684 }
]
查看完整的代码示例
这里。
就这样——这就是您如何快速地从语义 ML 电子表格转到代码!
本文的早期版本发布在
https://daleonai.com/semantic-ml 上。






