https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj9UrK4PYtWtQM0EcUx67uXAJv-9AFy94HhODhDoBZtFgy9iB_4iBpJXAKnzznisZloSFcchWNkk1cQWQteJnZg1SgzJCi_KxG3Do2qfBfWDaZ5ENEC_Moo1MSXz9v-ihny1SPyY80_8pA/s1600/flowchart+5.gif
发布者 Tulsee Doshi,Andrew Zaldivar
随着全球数十亿人继续使用以 AI 为核心的产品或服务,AI 的
负责任部署变得比以往任何时候都更加重要:维护信任并将每个用户的福祉放在首位。我们一直将构建包容性、合乎道德且对社区负责的产品作为我们的最高优先事项,特别是在过去的一个月里,美国一直在努力解决其系统性种族主义的历史,这种做法一直,并将继续与以往一样重要。
两年前,谷歌推出了其
AI 原则,指导我们研究和产品中 AI 的道德开发和使用。AI 原则阐明了我们围绕
隐私、
问责制、
安全、
公平和
可解释性的
负责任的 AI 目标。每一个都是确保基于 AI 的产品为每个用户正常工作的关键要素。
作为 Google 负责任的 AI 产品主管和开发者倡导者,我们亲眼目睹了开发者如何在使用像
TensorFlow这样的平台构建负责任的 AI 目标方面发挥着重要作用。作为世界上最受欢迎的机器学习框架之一,拥有数百万次下载量和全球开发者社区,TensorFlow 不仅在 Google 内部使用,而且在全球范围内用于解决具有挑战性的现实世界问题。这就是我们不断扩展 TensorFlow 生态系统中负责任的 AI 工具包的原因,以便世界各地的开发者能够更好地将这些原则融入其机器学习开发工作流程。
在这篇博文中,我们将概述使用 TensorFlow 构建负责任的 AI 应用程序的方法。这里的工具集只是我们希望成为一个不断增长的工具包和经验教训库的起点,以及应用这些教训的资源。
您可以在
TensorFlow 的负责任的 AI 工具集中找到下面讨论的所有工具。
使用 TensorFlow 构建负责任的 AI:指南
构建到工作流程中
虽然每个 TensorFlow 管道都可能面临不同的挑战和开发需求,但我们看到开发者在构建自己的产品时遵循一致的工作流程。而且,在这个流程的每个阶段,开发人员都会面临不同的负责任的 AI 问题和注意事项。考虑到这种工作流程,我们正在设计我们的负责任的 AI 工具包来补充现有的开发人员流程,以便将负责任的 AI 工作直接嵌入到开发者已经熟悉的结构中。
您可以在以下位置查看工作流程和工具的完整摘要:
tensorflow.org/resources/responsible-ai
为了简化我们的讨论,我们将工作流程分为 5 个关键步骤
- 步骤 1:定义问题
- 步骤 2:收集和准备数据
- 步骤 3:构建和训练模型
- 步骤 4:评估性能
- 步骤 5:部署和监控

实际上,我们预计开发人员将在这些步骤之间频繁移动。例如,开发人员可能会训练模型、识别性能低下,并返回收集和准备更多数据以解决这些问题。很可能,模型将在部署后被迭代和改进多次,这些步骤也将被重复。
无论您何时以及以何种顺序执行这些步骤,在每个阶段都需要提出关键的负责任的 AI 问题,以及相关工具来帮助开发人员调试和识别关键见解。随着我们更详细地介绍每个步骤,您会看到列出了一些问题,以及我们建议您研究的一组工具和资源,以回答提出的问题。当然,这些问题并非旨在涵盖所有问题;它们只是作为示例来激发您在开发过程中的思考。
请记住,许多这些工具和资源可以在整个工作流程中使用,而不仅仅局限于使用它们的步骤。
公平指标和
机器学习元数据,例如,可以作为独立工具分别评估和监控您的模型是否存在意外偏差。这些工具也集成在
TensorFlow Extended中,为开发人员提供了一种途径,不仅可以将模型投入生产,还可以为他们提供一个统一的平台,以更无缝地迭代工作流程。
步骤 1:定义问题
什么是我正在构建的?什么是目标?
谁是我在为谁构建这个?
如何他们将使用它?什么是它失败时对用户的后果?
任何开发流程的第一步都是定义问题本身。什么时候 AI 实际上是一个有价值的解决方案,它解决的是什么问题?在定义 AI 需求时,请务必牢记您可能在为其构建的不同用户以及他们可能对该产品的不同体验。
例如,如果您正在构建一个医疗模型来筛选个体的疾病,如
此 Explorable中所做的那样,该模型可能会针对成年人与儿童学习和工作不同。当模型失败时,它可能会有严重的负面影响,医生和用户都需要了解这些影响。
如何识别所有用户的重要问题、潜在危害和机会?TensorFlow 中的负责任的 AI 工具包有一些工具可以帮助您
PAIR 指南
人与 AI 研究 (PAIR) 指南,重点介绍设计以人为本的 AI,是您构建的伴侣,概述了您在开发产品时要问的关键问题。它基于来自 40 个产品团队的 Google 员工的见解。我们建议您在定义问题时通读关键问题,并使用有用的工作表!,但随着开发的进行,请参考这些问题。
AI Explorables
一组轻量级的交互式工具,Explorables 提供了对一些关键的负责任的 AI 概念的介绍。
步骤 2:收集和准备数据
我的数据集代表谁?它是否代表所有我的潜在用户?
我的数据集如何被采样、收集和标记?
如何保护我的用户的隐私?
我的数据集可能编码了哪些潜在的偏差?
在您定义了您希望使用 AI 来解决的问题之后,该过程的关键部分是收集最能考虑解决该问题的社会和文化因素的数据。希望基于非常具体的方言训练语音检测模型的开发者可能希望考虑从已经努力适应缺乏语言资源的语言的来源获取数据。
作为机器学习模型的中心和灵魂,数据集本身应该被视为一种产品,我们的目标是为您提供了解数据集代表谁以及收集过程中可能存在哪些差距的工具。
TensorFlow 数据验证
您可以利用
TensorFlow 数据验证 (TFDV) 来分析您的数据集并跨不同特征进行切片,以了解您的数据是如何分布的,以及可能存在哪些差距或缺陷。TFDV 结合了
TFX和
Facets 概述等工具,帮助您快速了解数据集特征中值的分布。这样,您就不必创建单独的代码库来监控您的训练和生产管道是否存在偏斜。
 |
| 哥伦比亚西班牙语说话者数据集的数据卡示例。 |
由 TFDV 生成的分析可用于在适当情况下为您的数据集创建
数据卡。您可以将数据卡视为您的数据集的
透明度报告,它提供对您的收集、处理和使用实践的洞察。例如,
我们的一项研究驱动的工程举措专注于为以下地区创建数据集:这些地区自然语言处理应用程序的资源有限,但互联网渗透率却在快速增长。为了帮助其他希望探索这些地区的语音技术的学者,该举措背后的团队创建了针对不同西班牙语国家的 Data Cards,包括
哥伦比亚西班牙语说话者数据集,如上所示,为使用他们的数据集时可以期待的内容提供了一个模板。
有关 Data Cards 的详细信息、创建 Data Cards 的框架以及如何将 Data Cards 的各个方面集成到您使用的流程或工具中的指南将很快发布。
步骤 3:构建和训练模型
如何在我训练模型的同时保护隐私或考虑公平性?
我应该使用哪些技术?
训练您的 TensorFlow 模型可能是开发流程中最复杂的部分之一。您如何训练它,使其能够
为所有人提供最佳性能,同时仍然保护用户隐私?我们开发了一套工具来简化此工作流程的各个方面,并在您设置 TensorFlow 管道时,让您能够集成最佳实践。
TensorFlow Federated
联邦学习是一种新的机器学习方法,它使许多设备或客户端能够在保持其数据本地的情况下,共同训练机器学习模型。将数据保持在本地可以带来隐私方面的益处,并有助于防范集中式数据收集的风险,例如盗窃或大规模滥用。开发人员可以使用
TensorFlow Federated 库,尝试将其应用于自己的模型。
[新] 我们最近发布了一个
教程,用于使用 Kubernetes 集群运行 TensorFlow Federated 的高性能模拟。
TensorFlow Privacy
您还可以通过
差分隐私来支持训练中的隐私,它在您的训练中添加噪声,以隐藏数据集中的单个示例。TensorFlow Privacy 提供了一组优化器,使您能够从一开始就使用差分隐私进行训练。
TensorFlow Constrained Optimization 和 TensorFlow Lattice
除了在训练模型时构建隐私考虑因素外,您可能还希望设置一组度量标准,并在训练机器学习问题时使用它们以实现理想的结果。例如,在不同群体之间创造更加公平的体验,如果不对满足此现实世界要求的度量标准组合进行考虑,可能难以实现。
TFCO 和
TensorFlow
Lattice 是提供许多不同基于研究方法的库,使基于约束的方法能够帮助您解决更广泛的社会问题,例如公平性。在下一个季度,我们希望开发并提供更多负责任的 AI 训练方法,发布我们在自己的产品中使用的基础设施,以努力解决公平性问题。我们很高兴继续构建一套工具和案例研究,展示不同的方法在多大程度上适合不同的用例,并为每个案例提供机会。
步骤 4:评估模型
我的模型是否保护隐私?
我的模型在我的多样化用户群中表现如何?
失败的例子是什么?为什么会出现这些情况?
模型经过初步训练后,迭代过程就开始了。通常,模型的第一个版本并不能像开发人员希望的那样运行,因此拥有易于使用的工具来识别其失败之处非常重要。特别是在识别用于理解隐私和公平性问题的正确度量标准和方法方面,可能会遇到挑战。我们的目标是通过工具来支持这些努力,使开发人员能够在传统评估和迭代步骤的基础上,评估隐私和公平性。
[新] 隐私测试
上周,我们宣布了 TensorFlow Privacy 的一个
隐私测试库。这个库是我们希望发布的许多测试中的第一个,它使开发人员能够查询其模型并识别单个数据点的信息被记住的实例,这些实例可能需要开发人员进一步分析,包括考虑将模型训练为具有差分隐私。
评估工具套件:公平性指标、TensorFlow 模型分析、TensorBoard 和 What-If 工具您还可以探索 TensorFlow 的评估工具套件,以了解模型中的公平性问题,并调试特定示例。
公平性指标允许对大型数据集上的分类和回归模型的常见公平性指标进行评估。该工具还附带了一系列
案例研究,帮助开发人员轻松识别适合其需求的度量标准,并使用 TensorFlow 模型设置公平性指标。可视化可以通过广泛流行的
TensorBoard 平台 实现,建模人员已经使用该平台来跟踪其训练指标。最近,我们推出了一项
案例研究,重点介绍了如何在 pandas 中使用公平性指标,以支持对更多数据集和数据类型的评估。
公平性指标建立在
TensorFlow 模型分析 (TFMA) 之上,TFMA 包含更广泛的指标集,用于评估跨不同关注点的常见指标。
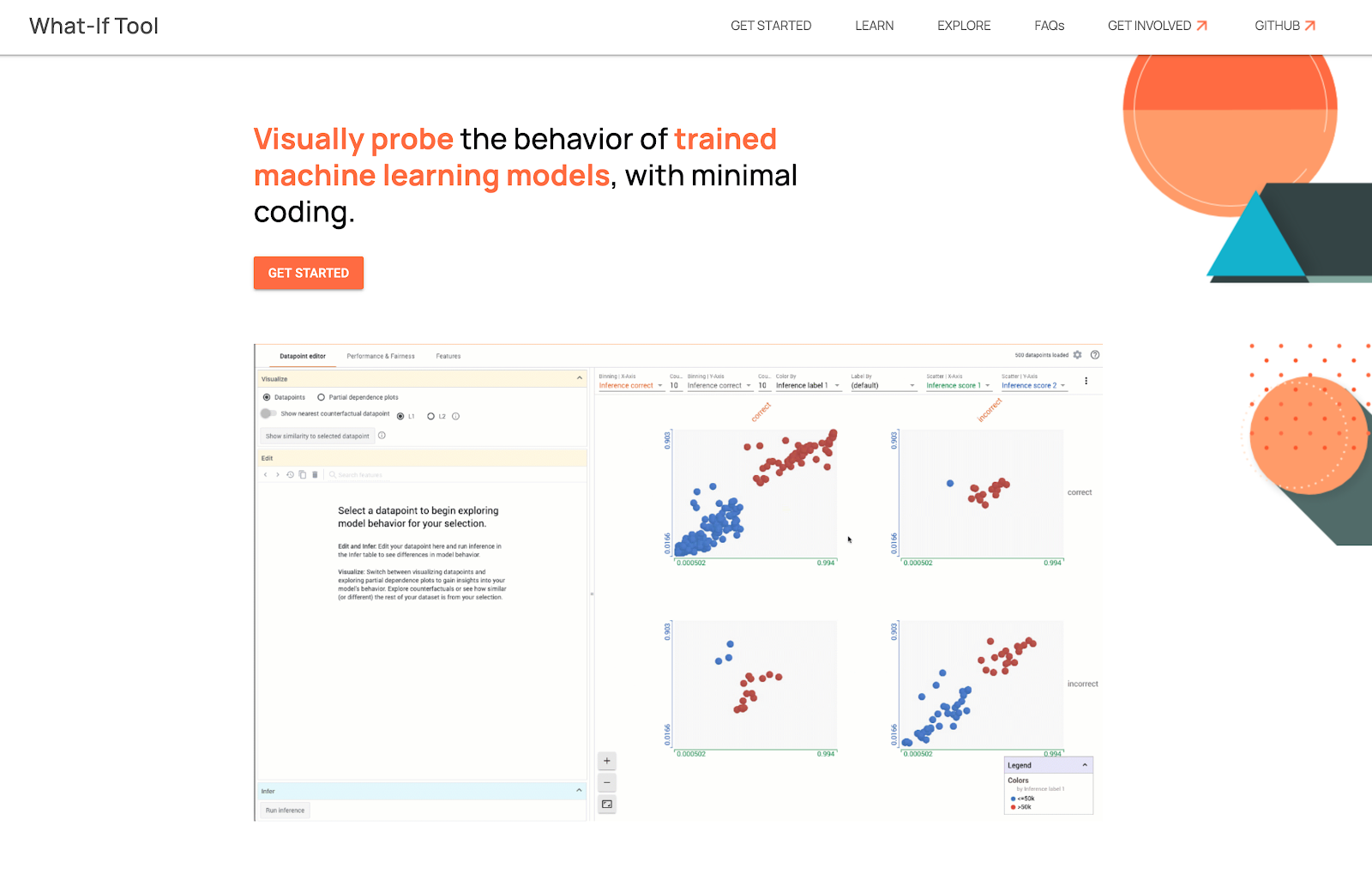 |
| What-If 工具允许您测试数据点上的假设情况。 |
一旦您识别出没有表现良好的切片,或者想要更仔细地理解和解释错误,您就可以使用
What-If 工具 (WIT) 进一步评估您的模型,该工具可直接从
公平性指标和 TFMA 中使用。使用 What-If 工具,您可以通过检查数据点级别的模型预测来深化对特定数据切片的分析。该工具提供了大量功能,从测试数据点上的假设情况(例如,“如果此数据点来自不同的类别,会发生什么?”)到可视化不同数据特征对模型预测的重要性。
除了在公平性指标中的集成之外,What-If 工具还可以作为独立工具在其他用户流中使用,并且可以通过
TensorBoard 或在
Colaboratory、
Jupyter 和
Cloud AI Platform 笔记本中访问。
[新] 今天,为了帮助 WIT 用户更快地入门,我们发布了
一系列新的教育教程 和演示,帮助我们的用户更好地使用该工具的众多功能,从
充分利用反事实来解释模型行为,到
探索您的特征并识别常见偏差。
可解释 AI Google Cloud 用户可以使用可解释 AI 将 WIT 的功能更进一步,可解释 AI 是一个工具包,它建立在 WIT 之上,引入了额外的可解释性功能,包括
集成梯度,它可以识别对模型性能影响最大的特征。
TensorFlow.org 上的教程 您可能还对这些教程感兴趣,它们用于处理
不平衡数据集,以及使用
集成梯度 解释图像分类器,类似于上面提到的内容。
 |
| 使用上面的教程来解释为什么这张图像被归类为消防船(可能是因为喷水)。 |
步骤 5:部署和监控
我的模型随着时间的推移表现如何? 它在不同的场景下表现如何? 如何继续跟踪和改进其进展?没有一个模型开发过程是静止的。随着世界变化,用户也会变化,他们的需求也会变化。例如,
前面讨论过的用于筛选患者的模型,在流行病期间可能不再有效。重要的是,开发人员拥有能够跟踪模型的工具,以及清晰的渠道和框架,以便将有用的模型详细信息传达给可能继承模型的开发人员,或者传达给希望了解模型如何适用于各种人群的用户和政策制定者。TensorFlow 生态系统拥有可以帮助进行这种谱系跟踪和透明度的工具。
ML Metadata
在您设计和训练模型时,您可以允许 ML Metadata (MLMD) 在整个开发过程中生成可跟踪的工件。从您的训练数据摄取和每个步骤执行的任何元数据,到使用评估指标导出您的模型以及相应的上下文(例如变更列表和所有者),MLMD API 可以创建您的 ML 工作流程所有中间组件的轨迹。MLMD 提供的这种持续进行的进度监控有助于识别训练中的安全风险或并发症。
模型卡
在您部署模型时,您还可以将模型部署与
模型卡相结合,模型卡是一种以特定格式结构化的文档,它为您提供了一个机会来传达模型的价值和局限性。模型卡可以让开发人员、政策制定者和用户了解有关训练模型的各个方面,从而为更大的开发人员生态系统提供额外的清晰度和可解释性,从而使 ML 不太可能被用于不适合它的环境。基于 Google 研究人员在 2019 年初发表的
学术论文 中提出的框架,模型卡已与
Google Cloud Vision API 模型 一起发布,包括其对象和人脸检测 API,以及许多开源模型。
今天,您可以从论文和
现有示例 中获得灵感,开发自己的模型卡。在接下来的两个月内,我们计划将 ML Metadata 和模型卡框架相结合,为开发人员提供一种更自动化的方式来创建这些重要的工件。敬请关注我们的模型卡工具包,我们将其添加到负责任的 AI 工具包集合中。
需要注意的是,虽然 ML 工作流程中的负责任 AI 是一个关键因素,但从 AI 道德的角度构建产品是技术、产品、政策、流程和文化因素的结合。这些问题是多方面的,从根本上说是
社会技术的。例如,公平性问题通常可以追溯到世界上基础系统中的偏差历史。因此,主动的 AI 责任努力不仅需要测量和建模调整,还需要政策和设计变更,以提供透明度、严格的审查流程以及能够带来多种视角的多样化决策者。
这就是为什么我们在 Google 进行的许多工具和资源都以我们在 Google 进行的社会技术研究工作为基础。如果没有这样一个强大的基础,这些 ML 和 AI 模型注定无法有效地造福社会,因为它们可能会错误地集成到决策系统中的纠缠中。采用跨文化视角,将我们的工作建立在以人为本的设计之上,将透明度扩展到所有领域,无论专业知识如何,并将我们的经验教训运用于实践——这些是我们负责任地构建 AI 所采取的步骤。
我们理解负责任的 AI 是一个不断发展的关键领域,因此我们对 TensorFlow 社区思考我们讨论过的问题(更重要的是,社区采取行动)感到鼓舞。在我们最新的
Dev Post 挑战 中,我们要求社区使用 TensorFlow 构建出色的 AI 原则产品。
获奖作品 探讨了公平性、隐私和可解释性等领域,并向我们展示了负责任的 AI 工具应该很好地集成到 TensorFlow 生态系统库中。我们将专注于此,以确保这些工具易于访问。
当您开始下一个 TensorFlow 项目时,我们鼓励您使用上述工具,并在
tf-responsible-ai@google.com 向我们提供反馈。与我们分享您的经验教训,我们将继续这样做,以便我们共同构建真正对所有人都有效的产品。






