https://blog.tensorflowcn.cn/2020/05/how-hugging-face-achieved-2x-performance-boost-question-answering.html
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhrx9XGcQWQ66cO8gqB43rA6C3A6OA2Le0qLFckWR0wiQySYoeggdClrdigArHzAwB4BlwfYYv3aZBhZ6xg_I1ECty8YRIr2rhKot_AFX5Garo-2ZgtANPd7_JDHoiDU3x0dde1c0D09GI/s1600/NLP+models.png
来自 Hugging Face 的客座文章:Pierric Cistac,软件工程师;Victor Sanh,科学家;Anthony Moi,技术主管。
Hugging Face 🤗 是一家 AI 初创公司,其目标是通过开发工具来改善社区合作并积极参与研究工作来为自然语言处理 (NLP)做出贡献。
由于 NLP 是一项困难的领域,我们相信解决它只有在所有参与者共享他们的研究成果和结果的情况下才有可能。这就是我们创建
🤗 Transformers 的原因,这是一个领先的 NLP 库,拥有超过 200 万次下载量,并被许多公司的研究人员和工程师使用。它使优秀的国际 NLP 社区能够快速尝试、迭代、创建和发布适用于各种任务(文本/令牌生成、文本分类、问答……)的各种语言模型(当然包括英语,但也包括法语、意大利语、西班牙语、德语、土耳其语、瑞典语、荷兰语、阿拉伯语和许多其他语言!)。目前,Transformers 提供了超过 300 种不同的模型。
虽然 Transformers 对于研究非常有用,但我们也一直在努力解决 NLP 的生产方面,研究和实施可以简化其在各行各业采用的解决方案。在这篇博文中,我们将展示我们认为可以帮助实现这一目标的路径之一:使用“小型”但性能良好的模型(例如
DistilBERT),以及针对 Node 等不同于 Python 的生态系统的框架,通过
TensorFlow.js 实现。
对小型模型的需求:DistilBERT
我们感兴趣的领域之一是“低资源”模型,它可以取得接近最先进的结果,同时体积更小,运行速度也快得多。这就是我们创建 DistilBERT 的原因,它是
BERT 的蒸馏版本:它拥有更少的参数(减少 40%),运行速度提高 60%,同时在 GLUE 语言理解基准测试中保留了 BERT 97% 的性能。
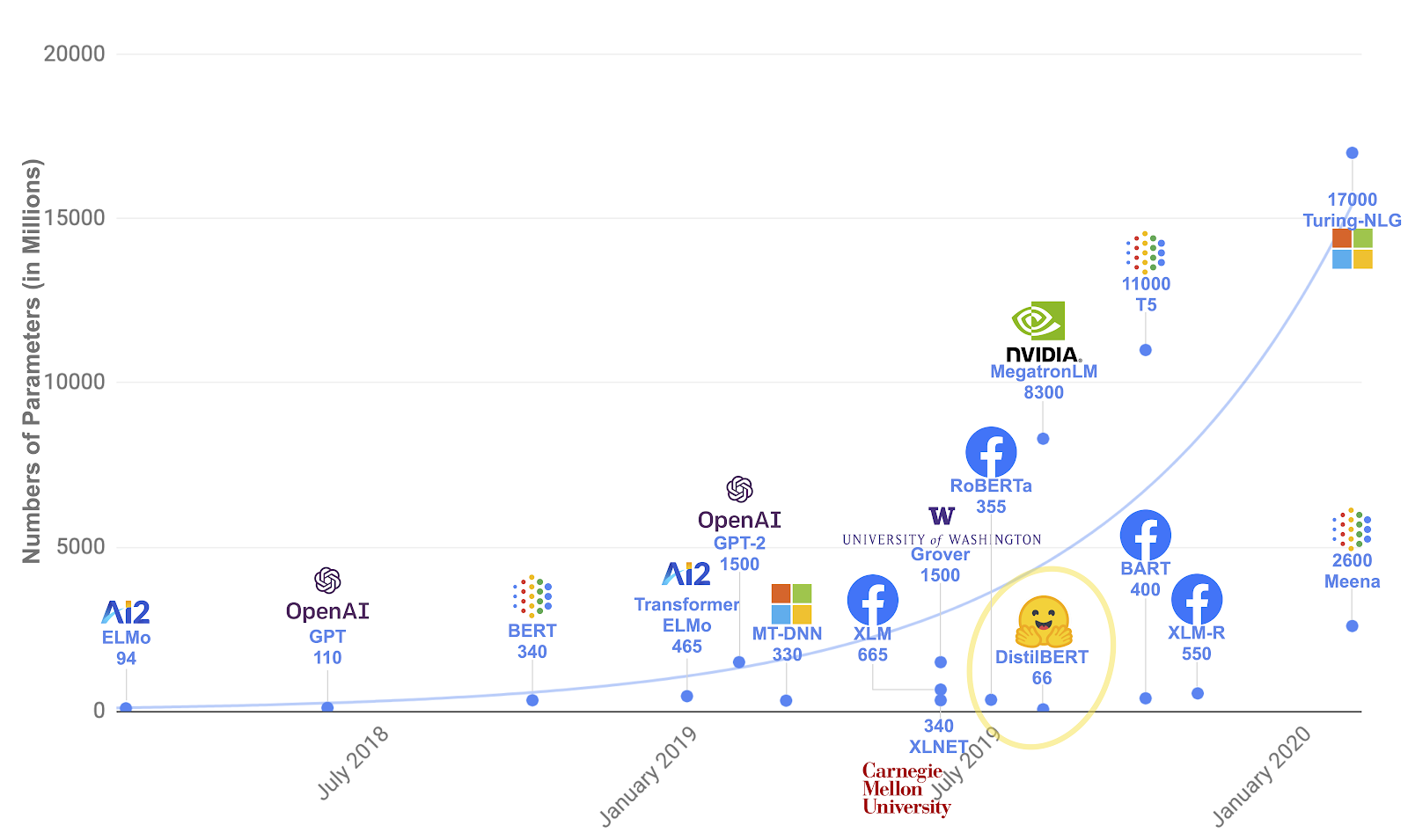 |
| 随着时间的推移,NLP 模型及其参数数量 |
为了创建 DistilBERT,我们已经将知识蒸馏应用于 BERT(因此得名),知识蒸馏是一种压缩技术,它训练一个小型模型来复制大型模型(或模型集合)的行为,由
Hinton 等人 证明。
在师生训练中,我们训练一个学生网络来模仿教师网络的完整输出分布(其知识)。我们不是使用针对硬目标(金类别的一热编码)的交叉熵来进行训练,而是使用针对软目标(教师的概率)的交叉熵,将知识从教师转移到学生。因此,我们的训练损失变为
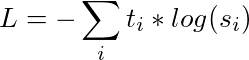 |
| 其中 t 是教师的 logits,s 是学生的 logits |
我们的学生是 BERT 的一个小型版本,我们在其中删除了令牌类型嵌入和池化器(用于下一句分类任务)。我们保留了其余的架构,但在减少层数时,从两层中取出一层,利用学生和教师之间共有的隐藏大小。我们使用梯度累积(每批高达 4000 个示例)对 DistilBERT 进行了大批量训练,并采用了动态掩蔽,同时删除了下一句预测目标。
这样,我们就可以在问答的特定任务上微调我们的模型。为此,我们使用在
SQuAD 1.1 上微调的
BERT-cased 模型作为教师,并使用知识蒸馏损失。换句话说,我们将一个问答模型蒸馏成一个之前使用知识蒸馏预训练的语言模型!这包含了很多师生:DistilBERT-cased 最初由 BERT-cased 教授,然后由 SQuAD 微调的 BERT-cased 版本“再次教授”,从而获得 DistilBERT-cased-finetuned-squad 模型。
鉴于网络的大小,这产生了非常有趣的性能:我们微调的 DistilBERT-cased 模型在开发集上的 F1 分数达到 87.1,比完整微调的 BERT-cased 模型低不到 2 个点!(88.7 F1 分数)。
如果您有兴趣了解更多关于蒸馏过程的信息,您可以阅读我们的
专用博客文章。
对语言中立格式的需求:SavedModel
使用以上过程,我们最终会得到一个 240MB 的 Keras 文件(.h5),其中包含我们 DistilBERT-cased-squad 模型的权重。在此格式中,模型的架构驻留在相关的
Python 类 中。但是,我们的最终目标是能够在尽可能多的环境中使用此模型(本博文的 Node.js + TensorFlow.js),而 TensorFlow 的
SavedModel 格式非常适合此目的:它是一种“序列化”格式,这意味着运行模型所需的所有信息都包含在模型文件中。它也是一种语言中立格式,因此我们可以在 Python 中使用它,也可以在 JS、C++ 和 Go 中使用它。
要转换为 SavedModel,我们首先需要从模型代码构造一个图。在 Python 中,我们可以使用
tf.function 来实现。
import tensorflow as tf
from transformers import TFDistilBertForQuestionAnswering
distilbert = TFDistilBertForQuestionAnswering.from_pretrained('distilbert-base-cased-distilled-squad')
callable = tf.function(distilbert.call)
在这里,我们将 Keras 模型中调用的函数
call 传递给
tf.function。作为回报,我们得到一个
可调用对象,我们可以反过来使用它来使用特定的签名和形状跟踪我们的调用函数,这要归功于
get_concrete_function
concrete_function = callable.get_concrete_function([tf.TensorSpec([None, 384], tf.int32, name="input_ids"), tf.TensorSpec([None, 384], tf.int32, name="attention_mask")])
通过调用
get_concrete_function,我们跟踪编译模型的 TensorFlow 操作,以获得由两个形状为
[None, 384] 的张量组成的输入签名,第一个是输入 ID,第二个是注意力掩码。
然后,我们终于可以将我们的模型保存为 SavedModel 格式
tf.saved_model.save(distilbert, 'distilbert_cased_savedmodel', signatures=concrete_function)
借助 TensorFlow,仅用 4 行代码即可完成转换!我们可以通过使用以下命令来检查生成的 SavedModel 是否包含正确的签名
saved_model_cli:
$ saved_model_cli show --dir distilbert_cased_savedmodel --tag_set serve --signature_def serving_default
输出
The given SavedModel SignatureDef contains the following input(s):
inputs['attention_mask'] tensor_info:
dtype: DT_INT32
shape: (-1, 384)
name: serving_default_attention_mask:0
inputs['input_ids'] tensor_info:
dtype: DT_INT32
shape: (-1, 384)
name: serving_default_input_ids:0
The given SavedModel SignatureDef contains the following output(s):
outputs['output_0'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 384)
name: StatefulPartitionedCall:0
outputs['output_1'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 384)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
完美!您可以通过打开
此 colab 笔记本 来自己尝试转换代码。现在,我们已准备好使用 TensorFlow.js 使用我们的 SavedModel 了!
对 Node.js 中 ML 的需求:TensorFlow.js
在 Hugging Face,我们坚信,为了充分发挥其采用的潜力,NLP 必须在生产中比 Python 更广泛使用的其他语言中可用,其 API 足够简单,即使没有机器学习博士学位的软件工程师也可以操作;其中一种语言显然是 Javascript。
借助 TensorFlow.js 提供的 API,在 Node.js 中与之前创建的 SavedModel 进行交互非常简单。以下是我们
NPM 问答包 中 Typescript 代码的简化版本
const model = await tf.node.loadSavedModel(path); // Load the model located in path
const result = tf.tidy(() => {
// ids and attentionMask are of type number[][]
const inputTensor = tf.tensor(ids, undefined, "int32");
const maskTensor = tf.tensor(attentionMask, undefined, "int32");
// Run model inference
return model.predict({
// “input_ids” and “attention_mask” correspond to the names specified in the signature passed to get_concrete_function during the model conversion
“input_ids”: inputTensor, “attention_mask”: maskTensor
}) as tf.NamedTensorMap;
});
// Extract the start and end logits from the tensors returned by model.predict
const [startLogits, endLogits] = await Promise.all([
result[“output_0"].squeeze().array() as Promise,
result[“output_1”].squeeze().array() as Promise
]);
tf.dispose(result); // Clean up memory used by the result tensor since we don’t need it anymore
请注意 TensorFlow.js 函数
tf.tidy 的使用,它负责自动清理诸如
inputTensor 和
maskTensor 之类的中间张量,同时返回模型推理的结果。
我们如何知道需要使用
"ouput_0" 和
"output_1" 从模型返回的结果中提取起始和结束 logits(可能回答问题的跨度的开始和结束)?我们只需查看之前导出到 SavedModel 后运行的
saved_model_cli 命令指示的输出名称。
对快速且易于使用的分词器的需求:🤗 Tokenizers
我们在构建 Node.js 库时,目标是使 API 尽可能简单。正如我们刚刚看到的,有了 SavedModel,运行模型推理非常简单,这要归功于 TensorFlow.js。现在,最困难的部分是将数据以正确的格式传递给输入 ID 和注意力掩码张量。我们通常从用户那里收集的是字符串,但张量需要数字数组:我们需要对用户输入进行分词。
输入
🤗 Tokenizers:一个我们一直在 Hugging Face 上开发的、用 Rust 编写的、性能卓越的库。它允许您非常轻松地使用不同的分词器,例如 BertWordpiece,并且它还支持 Node.js,这要归功于提供的
绑定
const tokenizer = await BertWordPieceTokenizer.fromOptions({
vocabFile: vocabPath, lowercase: false
});
tokenizer.setPadding({ maxLength: 384 }); // 384 matches the shape of the signature input provided while exporting to SavedModel
// Here question and context are in their original string format
const encoding = await tokenizer.encode(question, context);
const { ids, attentionMask } = encoding;
就是这样!只需 4 行代码,我们就可以将用户输入转换为格式,然后使用它来使用 TensorFlow.js 为我们的模型提供数据。
最终结果:Node.js 中强大的问答
借助 SavedModel 格式、用于推理的 TensorFlow.js 以及用于分词的 Tokenizers 的强大功能,我们实现了目标,在 NPM 包中提供了一个非常简单但功能强大的公共 API
import { QAClient } from "question-answering"; // If using Typescript or Babel
// const { QAClient } = require("question-answering"); // If using vanilla JS
const text = `
Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season.
The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California.
As this was the 50th Super Bowl, the league emphasized the "golden anniversary" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as "Super Bowl L"), so that the logo could prominently feature the Arabic numerals 50.
`;
const question = "Who won the Super Bowl?";
const qaClient = await QAClient.fromOptions();
const answer = await qaClient.predict(question, text);
console.log(answer); // { text: 'Denver Broncos', score: 0.3 }
强大?没错!由于 TensorFlow.js 原生支持 SavedModel 格式,因此我们获得了非常出色的性能:以下是一项基准测试,它比较了我们的 Node.js 包和我们流行的 transformers Python 库,运行的是同一个 DistilBERT-cased-squad 模型。如您所见,我们实现了 2 倍的速度提升!谁说 Javascript 速度慢?
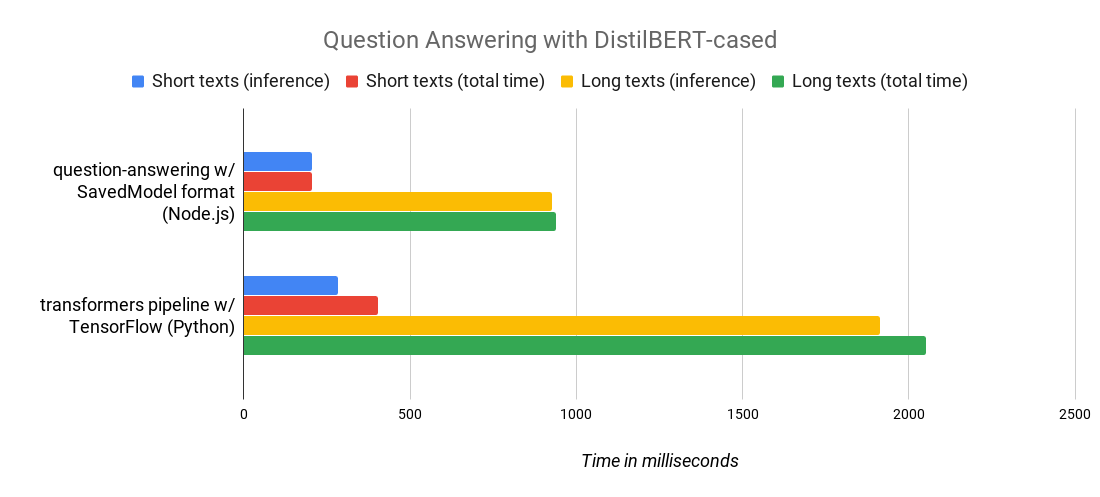 |
| 短文本是介于 500 到 1000 个字符之间的文本,长文本是介于 4000 到 5000 个字符之间的文本。您可以查看 Node.js 基准测试脚本 此处(Python 版本等效)。基准测试在运行 macOS 10.15.2 的标准 2019 MacBook Pro 上进行。 |
自然语言处理 (NLP) 领域正处于一个激动人心的时刻:像 GPT2 和 T5 这样的大型模型不断改进,而如何“精简”这些优秀但庞大且昂贵的模型的研究也越来越受到关注,蒸馏技术就是其中之一。再加上允许大型开发者社区参与这场革命的工具(例如 TensorFlow.js 和 JavaScript 生态系统),NLP 的未来比以往任何时候都更加激动人心,也更加适合生产环境!
如需了解更多信息,请随时访问我们的 Github 仓库
https://github.com/huggingface





