该 API 基于 Keras 层和模型抽象构建,隐藏了上述复杂性,因此您可以用几行代码对整个模型进行量化。
记录计算统计信息
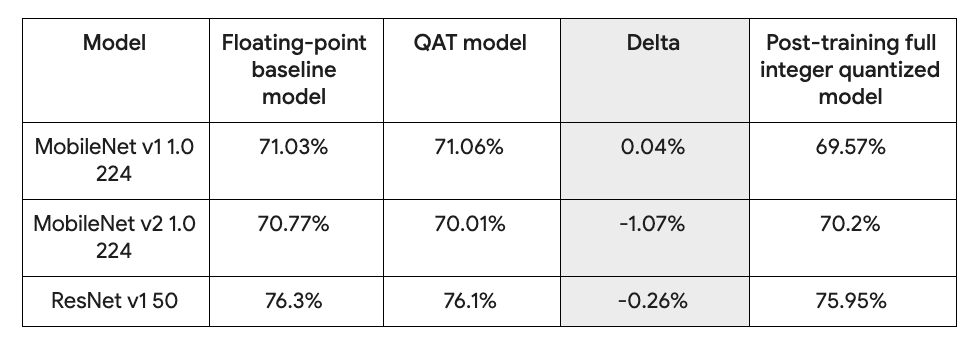
除了模拟降低精度的计算外,API 还负责记录量化训练模型所需的统计信息。例如,这使您能够获取使用 API 训练的模型,并将其转换为量化的仅整数 TensorFlow Lite 模型。
如何用几行代码使用 API
QAT API 提供了一种简单且高度灵活的方式来量化您的 TensorFlow Keras 模型。它使您能够非常轻松地使用“量化感知”对整个模型或部分模型进行训练,然后将其导出以与 TensorFlow Lite 一起部署。
量化整个 Keras 模型
import tensorflow_model_optimization as tfmot
model = tf.keras.Sequential([
...
])
# Quantize the entire model.
quantized_model = tfmot.quantization.keras.quantize_model(model)
# Continue with training as usual.
quantized_model.compile(...)
quantized_model.fit(...)
量化 Keras 模型的部分
import tensorflow_model_optimization as tfmot
quantize_annotate_layer = tfmot.quantization.keras.quantize_annotate_layer
model = tf.keras.Sequential([
...
# Only annotated layers will be quantized.
quantize_annotate_layer(Conv2D()),
quantize_annotate_layer(ReLU()),
Dense(),
...
])
# Quantize the model.
quantized_model = tfmot.quantization.keras.quantize_apply(model)
默认情况下,我们的 API 被配置为使用 TensorFlow Lite 中可用的量化执行支持。一个包含端到端训练示例的详细 Colab 位于 这里。
API 非常灵活,能够处理更复杂的用例。例如,它允许您精确控制层内的量化,创建自定义量化算法,以及处理您可能编写的任何自定义层。